CS111 Lecture 15
Outline
- optimization to avoid page fault
- page fault occurs when a program is trying to access a page that is not on RAM, but mapped to a virtual address
- hardware traps, INT is called and control is then passed to kernel, after which, control is passed back to the next instruction
Mechanism: how page fault is dealt inside the kernel
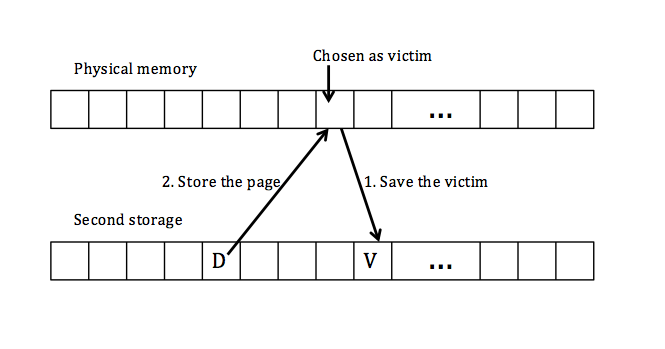
- the physical memory (a bunch of pages) is checked and a "victim" is picked (usually, the victim is a page in the program hat hasn't been accessed for very long)
- why don't we pick a free page? If the process has run for a long time, there is no free memory since "free memory is wasted memory"
- after picking the victim, it might be tempting to just discard it away, but bearing in mind that this victim might be useful to other users, we instead save the victim onto disk
the mechanism is illustrate by the graph below
up to this point, let's assume that there exists a removal_policy() function that returns the address of the victim with a well-thought policy decision of choosing a good victim
off_t swapmap(proc, vpn) // vpn is virtual page number
{
// return disk address that contains the page or FAIL (if that is a bad virtual address)
}
// the function get invoked after traps
void pfault (proc, vpn, accesstype) // accesstype gives information like READ / WRITE
{
off_t disk_address = swapmap (proc, vpn);
if (disk_address == FAIL)
kkill (proc, SIGSEGV);
else
{
(procv, vpnv, ppnv) = removal_policy();
// save victim data
// write page from (ppnv) to disk at (swapmap(proc, vpnv))
// update victim's page table such that vpnv points to NULL
// read page into (ppnv) from disk at (disk_address)
// update proc's page table such that vpn points to ppnv
}
}
note that page fault is not desirable, since it makes the program slow, and thus we need to avoid page fault
Optimization: to avoid page fault or to minimize overhead of page fault
Besides changing to large pages, there are two common optimizations
- Demand paging
- pages should only be brought into memory if they are demanded
- only the first page is read into RAM, and then page fault if necessary
advantage: improve wait time
disadvantage: more page faults during execution
i.e. during execution, instead of reading pages sequentially, it reads one page then computes then read again, etc. resulting in higher change of page faults
to illustrate the advantage of demand paging over non-demand paging:

- Dirty bit
- keeps track of when a page in RAM isn't the same as what is on the disk
- when dealing with victim page, if the victim's dirty bit is zero, immediately discard it, without saving it (to save writing time in pfault() function)
- dirty bit can be implemented into page table entry along with r, w, x bits (maintained by hardware)
- alternatively, dirty bit can be simulated via the write bit (materialized by software)
advantage: eliminate the time used to store victim's data on disk in pfault(), and thus increase performance
Policy: decision on how to choose the victim
this policy should work for non-random access memory
if the memory is randomly accessed, any policy works just fine
- FIFO (first in first out policy)
victimize the page that has been in the memory for the longest amount of time
the idea is illustrate below with 5 virtual pages and 3 physical pages
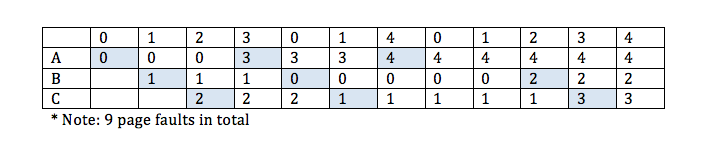
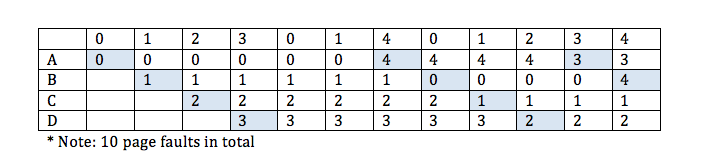
when the number of page frames are increased to 4, number of page faults also increases. This phenomenon is known as Belady's anomaly. Check out more information on Belady's anomaly here.
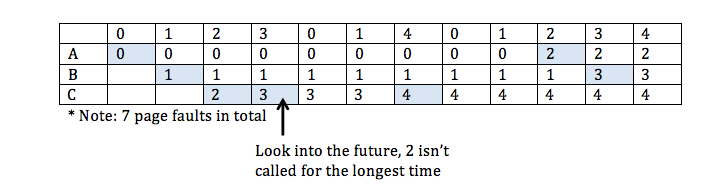
- Optimal policy
when deciding the victim at a particular time, look ahead to see which page is not needed for the longest time, choose that page as victim
to make it more efficient, the first step can be executed in parallel as follows

- LRU (least recently used) Policy
the victim page is the one that hasn't been accessed for the longest duration.

LRU mechanism
- to add a time stamp column in the page table (hardware)
- alternatively, to have another software page table that has a time stamp inside, and this time stamp can be as simple as an easy counter, instead of precise timing (software)
Distributed System and RPC (remote procedure calls)
differences between RPC and system calls
- caller and callee don't share address space
advantage: get hard modularity for free
disadvantage: poor performance
- no call by reference, only call by value
- caller and callee might have different architectures
e.g. different endian-ness
resolving endian-ness
- sender transmits data in the form the recipient prefers (polite sender)
- always transmit own format (rude sender)
- standardized on big endian
Data transmission and data storage in RPC: marshaling and un-marshaling
marshaling: the data in the client side is rearranged as a sequence of data and sent to the server
un-marshaling: on the server side, the sequence of data sent is broken down into certain data formats that server understands
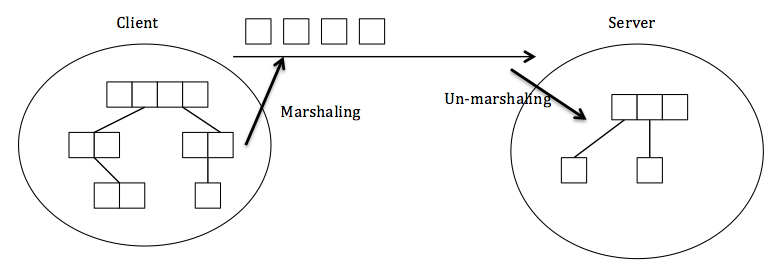
to convert the parameters passed between client and server, a stub is needed. A client stub is used to convert parameters used in function calls and de-convert results passed from server after the function calls are executed. A server stub is used to de-convert parameters passed by the client and to convert the results after the execution of the function calls. You can find more information on "stub" here.