1. Scheduling Metrics (Examining the car industry)
Understanding scheduling metrics, or how well a scheduling algorithm is doing, is not easy. Therefore, we take
a look at the scheduling metrics for a real world example to aid our understanding of how these metrics work.
For example, we take a look at the process for building a Model T.
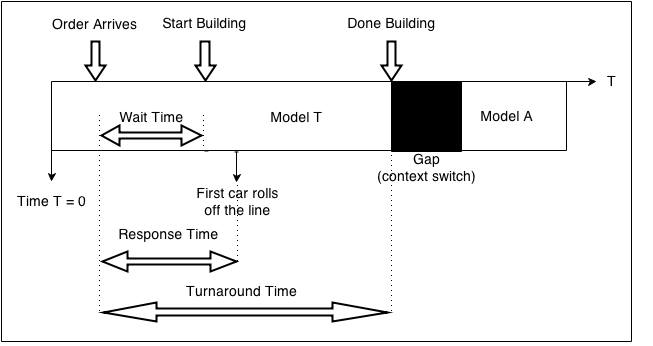
The Factory gets lots of orders and will need to process them efficiently.
There are some aggregate statistics that we need to keep track of:
1. Average Wait Time
2. Average Turnaround Time
3. Max Turnaround Time
4. Variance Turnaround Time (how far apart are the turnaround times)
5. Utilization = fraction of time doing useful work.
6. Throughput = Number of completed cars per month.
The customer, of course, wants all of these numbers to be low. However, from Lecture 1, we realized this is not always possible,
even though we wish for it with all our might. That is because we will run into the waterbed effect. For example, say that we
wanted to reduce the variance turnaround time. In this case, we can create an algorithm that allows us to switch orders such that
the time it takes to finish any single order is relatively the same. However, the problem is that the amount of context switching
(e.g. switch from making a Model T to a Model A) increases the average turnaround time. In addition, this will cause the utilization
of the factory to suffer. That is because context switching requires time (known as the "Gap" in the diagram) and excessive switching
requires an excessive amount of time. This is a good example of what we mean when we talk about the waterbed effect in relation
to optimizing the scheduling process.
This example is similar to how computers with one CPU and no hyperthreading technology might work. That CPU (the factory) is given a
task of trying to schedule many different processes all at once because the user is demanding, so it has to choose some sort of scheduling
policy that will work. In the next section below, we will cover some of the scheduling policies that one might encounter.
2. Scheduling Policy (Rule 0: You're probably not going to make a good one)
Here, we will run through several scheduling policies using an example problem:
Example Problem:
Time of Response
Process
Run time
Arrival time
1 A 5 0
1 B 2 1
3 C 9 2
3 D 4 3
Here, the gamma symbol (γ) represents the amount of time required for a context switch.
First Come First Serve (FCFS)
The policy here is pretty straightforward. If the process arrived first, then it will run first.
Starting from t=0 at the very left:
Assume: γ1 == γ2 == γ3
AAAAA |γ1| BB |γ2| CCCCCCCCC |γ3| DDDD |
To break it down:
After γ1, we have 5+γ
After γ2, we have 7+2γ
After γ3, we have 16+3γ
After the last process finishes, we have 20+3γ
Process
Wait time
A 0
B 4+γ
C 5+2γ
D 13+3γ
Notice: Another assumption we are making is that there is no beginning γ to prepare for
running process A or end γ to prepare for running whatever process exists after D.
Statistics:
Utilization: 20 ÷ 20+3γ
Throughput: 4 ÷ 20+3γ
Average wait: 5.5 + 1.5γ
Average turnaround: 10.5 + 1.5γ
Average response time: 7.5 + 1.5γ
This method makes sure that all processes will have a termination at some point (unless we run into a process
that has some obscene amount of turnaround time, then that's a different case). The problem with this policy is
that a very long process can make a shorter process wait longer than is ideal for the average turnaround time.
For our example problem, we notice that the wait time for process C (our very long process) is only 5+2γ
whereas our wait time for process D is 13+3γ.
Assuming γ to be less than 1 unit of time, then we see that the
wait time going from process C to D more than doubled. It's like needing to print 2 pages on a single printer
but someone else has already queued 100 pages to print on that same printer. Unfair.
Shortest Job First (SJF)
The policy here is to choose the job that can be completed in the shortest amount of time and do that first. A problem that
is readily apparent is the problem of pushing longer processes off in favor of shorter ones. In some cases, we can see a long
process sit idle for an obscene amount of time just because some user decided to schedule a whole bunch of shorter processes.
This is known as starvation. Nonetheless, we will still go over some metrics for this section:
Starting from t=0 at the very left:
Assume: γ1 == γ2 == γ3
AAAAA |γ1| BB |γ2| DDDD |γ3| CCCCCCCCC |
Process
Wait time
A 0
B 4+γ
C 9+3γ
D 4+2γ
Statistics:
Utilization: 20 ÷ 20+3γ
Throughput: 4 ÷ 20+3γ
Average wait time: 4.25 + 1.5γ
Average turnaround time: 9.25 + 1.5γ
Average Response time: 6.25 + 1.5γ
With respect to the First Come First Serve policy, we see that the average wait time, the average turnaround time, and the average
response time has decreased. So, this is an improvement in performance! Therefore, this is better than First Come First Serve, right?
Not necessarily. As we mentioned earlier, it's possible for many small processes to hog up the CPU and never let the larger processes
run. This is unacceptable since it brings the wait time of that particular process to infinity because of starvation. So, we conclude that
this is the worst case/policy.
On a side note, a system will approximate how long a process will take. This can be right or wrong depending on the particular process.
Preemption
Here, we will consider two cases with preemption:
1. FCFS + Preemption (Round Robin)
2. SJF + Preemption (briefly covered)
In the first case, we assume that newcomers are put last, which prevents starvation.
The order in which the processes will be executed is as follows (assume there is a context switch time between processes of different names):
A B A C B D A C D A C D A C D CCCCC
Statistics for the first case:
Utilization: 20 ÷ 20+15γ (15 total context switches)
Average wait time: 1 + 2.5γ
Average response time: (somewhat better)
Here, we get better average wait times. However, the tradeoff is that our utilization and total run time suffers (waterbed effect!). This is
better for interactive systems since new interactions can get lower wait times and that is important to the user.
In the second case, we might see average response times and average turnaround times increase. However, average wait times will decrease
but so will utilization with the increased number of context switches.
Priority Scheduling
In Linux, priority = niceness + total CPU time + (-time since last run) + ...
e.g. $nice sort bigfile > out
The nicenesses ranges from -20 to 19 where -20 is most favorable and 19 is the least favorable. Therefore, a lower priority number (e.g. -10)
will have run before a higher priority number (e.g. 10).
e.g. nice sort (runs at a niceness of 10)
nice -9 sort (runs at a niceness of 9)
nice --9 sort (meaner sort)
Here is the documentation for the nice process: nice(1) man page
3. Synchronization
The biggest problem in a multi-threaded application is synchronization.
Lack of synchronization can lead to race conditions.
A race condition occurs the behavior of an application changes depending on the timing or
sequence of thread execution. Such bugs are intermittent and rare, which makes them
notoriously hard to debug.
Thus, an efficient and non-intrusive method must be used to fix such bugs.
Imagine a situation in which both Bill and Melinda Gates are operating on the same bank
account at the same time.
We could implement the deposit() and withdraw() code as such:
void deposit(int dep_amt) {
balance = balance + dep_amt;
}
bool withdraw(int with_amt) {
if(with_amt < 0) return false;
balance = balance - with_amt;
return true;
}
However, there is a race condition here. It is possible that Bill makes a deposit at the same
time Melinda is making a withdrawal.
If deposit() reads the balance variable, and the withdraw()
reads the balance variable before deposit() assigns balance to its new value, then the overall
balance would be short with_amt of dollars.
Even though deposit() has modified balance, withdraw() is still working with the old value of balance. Thus
when balance is modified the second time by withdraw(), it is incorrect.
There are many other operations such as an audit() or a transfer() function that would face
similar problems in the face of race conditions. Thus, we must develop a way of thinking about
events that allows us to draw up models to protect against such bugs.
Abstractly, what we want is this:
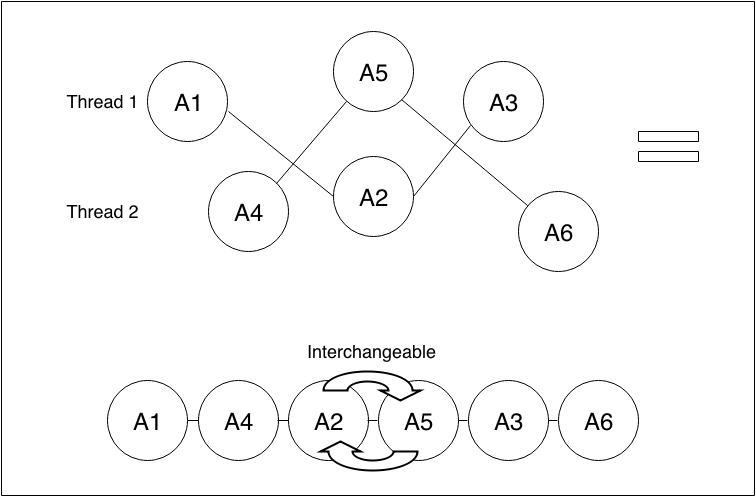
Observable behaviors should be serializable: They should explain events as if they are being executed in sequential order.
Events that do occur simultaneously should be interchangeable in their order.
Essentially, we want atomicity: an action should appear to execute instantaneously to
all threads, rather than extend over an interruptable period of time.
Implementations of such concepts are covered in the proceeding lectures.