The various metrics we will discuss are as follows:
UCLA CS 111, Spring 2014, LECTURE 8 Scribe Notes
Written by: Heather Blockhus and Megan Tench
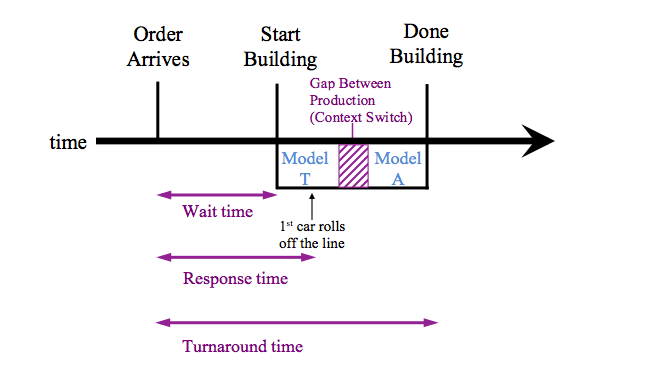
It is very hard to make a good scheduler, but there are a few measurements that can be used in order to determine how good a particular scheduler is. These methods were developed before computers in industries such as car manufacturing. For simplicity, in this lecture we assume that there is only one CPU or factory.
The various metrics we will discuss are as follows:
The factory gets a lot of orders and occasionally gets orders for different models. Between working on two different models of cars, there is time required to update the infrastructure such as switching out paint colors and bringing out parts exclusive to the specific model. In an operating system this wait time is called context switching.
In order to determine user satisfaction different statistics can be examined. The user is concerned about aggregate statistics that compile the data of all jobs ordered. Examples of some aggregate statistics could be the average wait time, maximum turnaround time, or the variance. The user would want all of the previously mentioned aggregates to be low. However, trying to improve your scheduler to minimize one of these statistics could have a waterbed effect on the others, causing them to increase.
In the first come first serve scheduling policy, the orders are executed in the order that they arrive. The following table and time-line show how this would work in an operating system on the sample processes A through D.
| Process | Run Time | Arrival Time | Time of First Response |
|---|---|---|---|
| A | 5 | 0 | 1 |
| B | 2 | 1 | 2 |
| C | 9 | 2 | 3 |
| D | 4 | 3 | 3 |
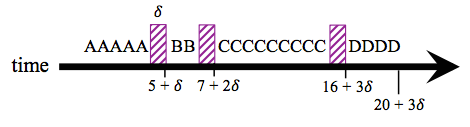
Calculation of aggregate statistics for this policy:
Is there a better way to schedule? Our goal in creating a schedule is to maximize the happiness of the customers by decreasing their wait time. In the first come first serve policy one long job causes all the other jobs to wait. If we were to swap C with D we would lower the average wait time.
In the shortest job first scheduling policy, the orders are executed by prioritizing the shortest available job. Using the same set of sample processes A though D, the following time-line shows how this would work.
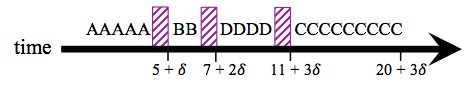
Calculation of aggregate statistics for this policy:
The benefit of this scheduling process is that it lowers the average wait time. However, a potential negative is that this policy could lead to starvation; a large order could end up waiting indefinitely due to smaller orders continually coming in. In the worst case the wait time could be infinity.
In order to solve the aforementioned issue of starvation we can add pre-emption to our scheduling processes. Pre-emption gives the OS the ability to interrupt a running process and resume its operation at a later time. Pre-emption leads to an increase in context switching, but since time taken during a context switch is usually relatively low the benefits outweigh the cost.
In the Round-Robin scheduling policy, first come first serve is combined with pre-emption to give equal opportunity to all orders. While there are multiple orders waiting to be run, the scheduler will cycle through them, giving them each equal time to run. When new processes arrive, they get put at the end of this queue. If there is only one process waiting, then it gets to run to completion unless a new process arrives.
Using the same processes as above, the new schedule that would be made by Round-Robin is as follows:
A B A C B D A C D A C D A C D CCCCC*
*note all of the spaces are context switches
Calculation of aggregate statistics for this policy:
The benefit of this scheduling process is that it lowers the average wait time while ensuring that a short process never gets trapped behind a long process. Also, this policy does not have starvation.
In the shortest remaining time first scheduling policy, shortest job first is combined with pre-emption so that the job with the shortest remaining time gets run next. A new process will start running when the current process finishes or when a shorter process arrives. When a new order arrives, it will interrupt the currently running process if its overall run time is smaller then the remaining run time on the running process.
Using the same processes as above, the new schedule that would be made by Shortest Remaining Time is as follows:
A BB AAAA DDDD CCCCCCCCC*
*note all of the spaces are context switches
Calculation of aggregate statistics for this policy:
The benefit of Shortest Remaining Times First scheduling process is that it lowers the average wait time of shortest job first, but it still has the problem of starvation.
Have you ever been at an airport waiting for your turn to board the airplane and a guy in a suit just gets to cut to the front of the line? This is probably because he has a fancy boarding pass and has priority boarding. This same concept of having priority over others can also be applied to operating systems where certain processes can have a higher priority than others.
In Linux, priority is done with niceness. Niceness has a range from -20 to 19. The higher a process's niceness is the more willing it will be to wait and allow "meaner" processes to execute before it. This means that a process with the lowest niceness score will have the highest priority and will be run first.
nice sort //default, adds 10 to the niceness of sort
nice -9 sort //adds 9 to the niceness of sort
nice --9 sort //subtracts 9 from the niceness of sort
On the Seasnet machines there are restrictions that a process can only be made nicer and cannot be made meaner, if you attempt to make a process meaner the kernel will reject your request. This is a common technique for all users that are not the Root, super user, who can change a process to any niceness.
Hard Real Time Schedulers are important when being used in dangerous circumstances where processes cannot miss deadlines. For example, this would be needed for a nuclear power plants emergency shut down procedure, or for the brake system in a car. In both these instances it is highly important that these processes run immediately. Every process in this type of system has the highest priority. For operating systems, caches are often disabled and polling is used instead of interrupts because predictability is more important than performance. Creating these types of schedulers is somewhat of a black art, as the people who write these schedulers do not often share their techniques.
Soft Real Time Schedulers are used when jobs can be cancelled with minimal cost to overall system performance. For example, this type of scheduling works well for buffering videos where if a single or a couple frames come out pixelated or are decoded incorrectly the users experience is minimally impacted. For operating systems, this is often used when scheduling the union of repetitive jobs.
A simple example of this is earliest deadline first where the process that has the earliest upcoming deadline is chosen to be run first. This works well when the number of jobs that need processing is low, but when overloaded performance suffers. For example, it may choose a job that it will be unable to complete by the deadline which wastes computation time where other jobs could have been chosen. Often this is combined with other things, such as priority or monotonic scheduling.
Synchronization is the biggest problem for multi-threaded applications. For most applications the default behavior is unsynchronized which can lead to race conditions that are notoriously hard to debug. Race conditions are hard to catch automatically because they are often intermittent and appear sparsely and randomly. Many electronics today most likely contain race conditions that have never been documented. In order to avoid race conditions in the future solutions need to be efficient, non-intrusive, and clear.
A simple example of a race condition can be seen in banking software. Imagine a scenario where both Bill and Melinda Gates have access to the same bank account and Bill wishes to make a deposit while Melinda simultaneously tries to make a withdrawal. Depending on when the balance in the account gets updated from one action it could be misread by the other action leading to an incorrect final balance on the account.
int balance;
//Bill Gates
bool deposit(int depamt, struct acct *aPtr)
{
if(!(0 <= depamt && depamt + balance <= INT_MAX+BALANCE))
return false;
balance += depamt;
return true;
}
//Melinda Gates
bool withdraw(int withamt, struct acct *aPtr)
{
if(!(0 <= withamt && withamt <= balance))
return false;
balance -= withamt;
return true;
}
One possible solution would be to have locks on the balance of the account so that only one process can access it at a time and will release the lock once the account has been updated. Another action that a bank might want to take is to perform an audit, which is an expensive operation that makes sure all deposits and withdrawals add up. This can take a lot of time and must be run at night or on the weekends when customers are not attempting to access their accounts. Also, customers might have multiple accounts which can make locks more complicated if they attempt to make a transfer between accounts.
More abstractly, in order to prevent race conditions we are concerned that the observable behavior of a multi-threaded application is serializable.
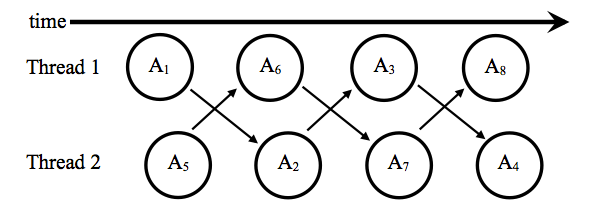
For the above example, in order for it to be serializable there needs to be an equivalent ordering of the actions such that each action is run independently and the overall output of the program is unchanged. This is only possible if processes that run at the same time, such as A1 and A5, do not depend on each other and do not access the same pieces of memory. You can pretend that A1 completes before A5 without having any impact on the application's overall output. One way to ensure that we have a serializable schedule is through atomicity, either an action occurs or it does not.