A critical section is a portion of code that only one thread should be running at any given time. For example, we wouldn’t want two different threads in this code that transfers money from one bank account to another.
acct1 += amt;
acct2 -= amt;One possible solution to this problem is to create a global variable called watch_out. When a thread is in a critical section, it sets watch_out to 1.
watch_out = 1;
acct1 += amt;
acct2 -= amt;
watch_out = 0;This doesn’t work if two threads need to call watch_out since it never checks if watch_out is set to 1. We need to have a thread check if watch_out is already 1 before it can set watch_out to 1.
int watch_out;
while (watch_out)
continue;
watch_out = 1;
// CRITICAL SECTION CODE
watch_out = 0;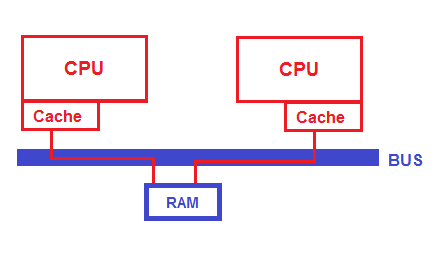
We still have a race condition because two different threads could exit instruction at same time, so we ask for help from the hardware people. We are given a memory access protocol where all the CPUs check transactions going across the bus. Since messages in the bus are global, one CPU can check if another wants exclusive access to a critical section.
There is an instruction, lock incl, which loads a word into memory and adds 1 to it, all while making sure no other CPU can do the same thing. The advantage of this approach is that it is atomic and we don’t have to worry about anything else trying to do the same thing. However, the disadvantage is that this method is extremely slow since we are forced to use RAM even though caches are much faster. This is not a method we would want to use for something as simple as incrementation.
To use this instruction, we call asm(‘lock incl x’).
There are several instructions in x86 designed to do this (e.g. int test_and_set(int *p, int val), int exchange(int *p, int newval)).
int exchange(int *p, int newval) {
int oldval = *p;
*p = newval;
return oldval;
}Use lock xchgl x instead which atomically exchanges %eax with the value x.
typedef int volatile lock_t; // volatile to ensure the assignment of 0 is not delayed
void lock(lock_t *p) {
while(exchange(p, 1))
continue;
}
void unlock(lock_t *p) { // don't need to exchange because current thread has the lock
*p = 0;
}Preconditions for unlocking:
Preconditions for locking:
exchange(p,1), it will always return 1 since you already have the lockThe use of critical sections is not scalable since 1 CPU can cause N-1 CPUs to busy wait.
Locks can be avoided sometimes. One way to avoid locks is to make the code so simple that it already behaves atomically, such as narrowing the code down to a single load or store of an int. Unfortunately, loads and stores are only atomic for objects of a certain size. For atomic behavior, objects can’t be too large.
int x;
threadA: { int i = x; }
threadB: x = 27;If the object is too large, you'll get part of the old value of x and part of the new value of x.
Objects also can’t be too small.
struct {
unsigned int a : 7; // the colon specifies that the bit field is exactly 7 bits wide
unsigned int b : 1; // a and b fit in 1 byte
} x;
threadA: { int i = x.b; } threadB: { x.b = 1; } threadC: x.a = 97;
int a[2];
char *p = (char*) a;
p += sizeof(int)/2;
int *ip = (int *) p;
waitpid(27, p, 0);
// works on the intel architecture
// does not work atomicallyPipes are bounded buffers that are used for communication between two processes. Pipes do not work without locks.
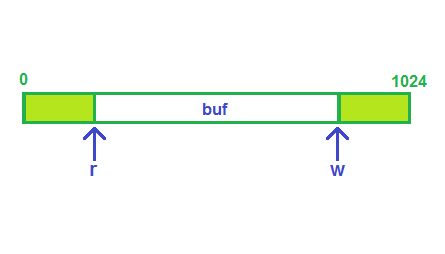
#define N 1024
struct pipe {
char buf[N];
size_t r, w; // read list and write list
}
char read_pipe(struct pipe) {
lock(&l);
while(p->r == p->w) {
unlock(&l);
lock(&l);
}
unlock(&l);
return p->buf[p->r++%N];
}
void write_pipe(struct pipe *p, char c) {
lock(&l);
while(p->w - p->r == N) // works with overflow since N is a power of 2
continue; // buffer is full
p->buf[p->w++%N] = c;
unlock(&l);
}This implementation is not thread safe. If one thread executes read_pipe while another executes write_pipe, we can get into trouble. We need to synchronize this such that two threads don’t try to do the increment (++) at the same time. However, this leads to a performance bug resulting from CPU overhead of the lock instruction and critical sections which should not have loops in them. One problem we run into is that the code can become too conservative, and it won’t allow for useful parallelization.
A coarse grained lock is an implementation such that there is only one lock for a large data structure or an entire system. While this approach is very safe, it creates a bad bottleneck. A fine grained lock works better since it only locks for its own data structure, and each pipe has its own lock. This allows parallelization when threads are using different pipes, and as long as threads are talking to different pipes, there will be no slowdown. However, this is not scalable if many threads are trying to use the same pipe.
Due to the aforementioned problems, we want to find a way to have a thread yield and only wake up when it has a good chance of getting a resource. One way of doing this is to use a blocking mutex. A blocking mutex has a lock as well as a list of other threads that want the lock.
typedef struct {
lock_t l; // spin lock, bad if you might not get resource
bool locked;
thread_t *blocked_list; // list of threads that want resource
} bmutex_t; // owning bmutex is different from owning the lock
void acquire(bmutex_t *b) {
while(lock(&b->l), (b->locked)) {
thread_t *l = b->blocked_list;
b->blocked_list = self;
self->runnable = false;
self->next = l;
unlock(&b->l);
yield();
b->locked = true;
}
unlock(&b->l);
}
void release(bmutex_t *b) {
lock(&b->l);
b->locked = false;
thread_t *next = b->blocked_list;
if(next) {
next->runnable = 1;
b->blockedlist = next->next;
}
unlock(&b->l);
}Semaphores are similar to blocking mutexes, but with an arity greater than 1. The int locked variable can go up to a bigger number, and blocking mutexes are also called binary semaphores.
The problem with this is that there is still some spinning, and that problem gets worse as the system scales. One way to fix this problem is to have a condition variable which represents whether the app is interested in the lock. Condition variables can be used to get rid of all the leftover spin.
We can still have race conditions which will give up correctness bugs. Trying to fix those bugs can lead to diminished performance. Another problem to watch out for is deadlocking, which is where two processes are waiting on each other to give up their respective locks.
tr a-z A-Z | cat | sortWe try to make cat faster by calling splice(fd1, fd2), where when we write to fd1, we also immediately write to fd2. However we can end up in a situation where we lock both &fd1 and &fd2, and they both wait for the other to give up their locks.