Annual income twenty pounds, annual expenditure nineteen [pounds],
nineteen [shillings] and six [pence]
... result happiness.
Annual income twenty pounds, annual expenditure twenty pounds ought
and six ... result misery.
The success of LRU (Least Recently Used) replacement algorithms is the stuff of legends. Nobody knows what tomorrow will bring, but for most purposes our best guess is that the near future will be like the recent past. Unless you have inside information (i.e. references are not random, and you know understand the pattern) it is generally held that there is little profit to be gained from trying to out-smart LRU. The reason LRU works so well is that most programs exhibit some degree of temporal and spatial locality:
In the absence of temporal and spatial locality, Global LRU will make poor decisions. Global LRU and Round-Robin scheduling are great algorithms, but they do not work well as a team. It might make sense to give each process its own dedicated set of page frames. When that process needed a new page, we would LRU replace the oldest page in that set. This would be per-process LRU, and that might work very well with Round-Robin scheduling.
As we discovered in our discussion of paging:
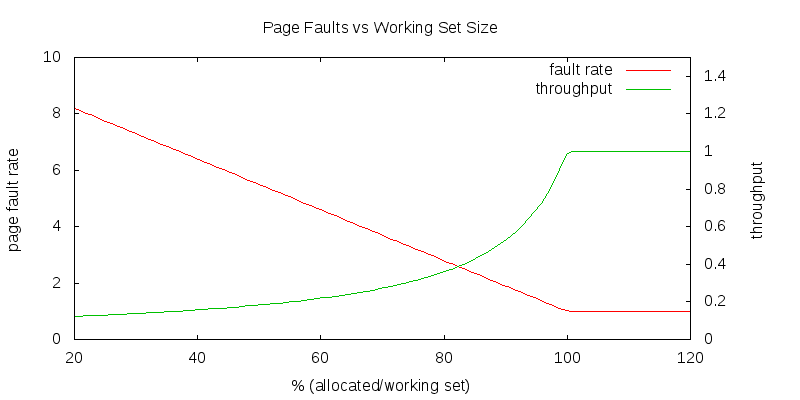
It is a good thing if a process experiences occasional page faults, and has to replace old (no longer interesting) pages with new ones. What we want to avoid is page faults due to running a process in too little memory. We want to keep the page-faults down to a manageable rate. The ideal mean-time-between-page-faults would be equal to the time-slice length. As we give a process fewer and fewer page frames in which to operate, the page fault rate rises and our performance gets worse (as we spend less time doing useful computation and more time processing page faults).
The dramatic degradation in system performance associated with not having enough memory to efficiently run all of the ready processes is called thrashing.
There is, for any given computation, at any given time, a number of pages such that:
Different computations require different amounts of memory. A tight loop operating on a few variables might need only two pages. Complex combinations of functions applied to large amounts of data could require hundreds of thousands of pages. Not only are different programs likely to require different amounts of memory, a single program may require different amounts of memory at different points during its execution.
Requiring more memory is not necessarily a bad thing ... it merely reflects the costs of that particular computation. When we explored scheduling we saw that different processes have different degrees of interactivity, and that if we could characterize the interactivity of each process we could more efficiently schedule it. The same is true of working set size. We can infer a process' working set size by observing its behavior. If a process is experiencing many page faults, its working set is larger than the memory currently allocated to it. If a process is not experiencing page faults, it may have too much memory allocated to it. If we can allocate the right amount of memory to each process, we will minimize our page faults (overhead) and maximize our throughput (efficiency).
Regularly scanning all of memory to identify the least recently used page is a very expensive process. With global LRU, we saw that a clock-like scan was a very inexpensive way to achieve a very similar affect. The clock hand position was a surrogate for age:
We can use a very similar approach to implement working sets. But we will need to maintain a little bit more information:
while ...
{
// see if this page is old enough to replace
owningProc = page->owner;
if (page.referenced) {
// assume it was just referenced
page.lastRef = owningProc->accumulatedTime;
page.referenced = 0;
} else {
// has it gone unreferenced long enough?
age = owningProc->accumulatedTime - page.lastRef;
if (age > targetAge)
return(page);
}
}
The key elements of this algorithm are:
This is often referred to as a page stealing algorithm, because a process that needs another page steals it from a process that does not seem to need it as much.
This is a dynamic equilibrium mechanism. The continuously opposing processes of stealing and being stolen from will automatically allocate the available memory to the running processes in proportion to their working set sizes. It does not try to manage processes to any pre-configured notion of a reasonable working set size. Rather it manages memory to minimize the number of page faults, and to avoid thrashing.