CS111 - Winter 2008
Lecture 10
By Jin Li & Ei Darli Aung
Avoiding Deadlock
Circular wait is one of the 4 necessary conditions for deadlock to occur. To fix this, a cycle detection technique can be used. Or operating system keeps track of dependencies and if a wait process would cause a deadlock, operating system will cause it to fail by returning some signals like EWOULDDEADLOCK.
In many cases, Wait-For graph can be used to detect deadlock. Wait-For graph is used to track which other processes that a process is blocking on. In other words, Wait-For graph shows which process is waiting for a resource held by which other process. Just by looking at the graph, it can be determined if circular wait will occur. In a Wait-For graph, a process is represented as a circular node and resource is represented as a rectangular node. An edge from a process to a resource shows that the process is waiting to get a lock on the resource. An edge from a resource to a process denotes that lock on the resource has been granted to the process.
Examples of Wait-For graph:
2. Process 1 is holding lock of resource 1 and waiting on the lock for resource 2. Process 2 is holding lock of resource 2 and waiting on resource 1 resulting in circular wait and deadlock.
Lock Ordering
Lock ordering is another way to avoid deadlock. Main idea is to assume that locks are numbered and whenever you need more than 1 lock, you ask for locks in sequential order, eg. L1, L2, L3, etc...
There are some other cases where you can get into deadlock situation without using locks. For example, parent process and child process are using pipes to communicate each other. Parent writes to the pipe from its write end without reading anything. Child does the same thing at the same time. Eventually, both pipes are full and it will make the processes hang.
One possible solution to solve the problem is to let the parent do all writes and then reads, and at the same time, let child do all reads from its end and then all writes so that both parent and child will not do the exact same operations at the same time.
File and File System
In a broad sense, file system is a method to store and retrieve file and data efficiently. Here is what Wikipedia says about file system.
Comparison of different storage devices
Entries are in the order of fastest to slowest.
| Size | Device | Comment |
| 10^3 | registers | fast, expensive, tiny |
| 10^4.5 | L1 Cache | |
| 10^6 | L2 Cache | |
| 10^9 | DRAM | |
| 10^12 | Flash, Disk | |
| HUGE | network storage/tape/DVD/CD | slow, cheap, huge |
Here's the graph showing the importance of disk scheduling in recent years:
In the old days, we did not need to worry about disk scheduling so much because CPU was even slower than disk. However, since CPU gets way more faster than disk, it becomes necessary to schedule disk so that CPU will not waste time waiting for the disk to complete reading and writing.
Why are disk so slow?
They are mechanical devices. Here's a typical disk layout:
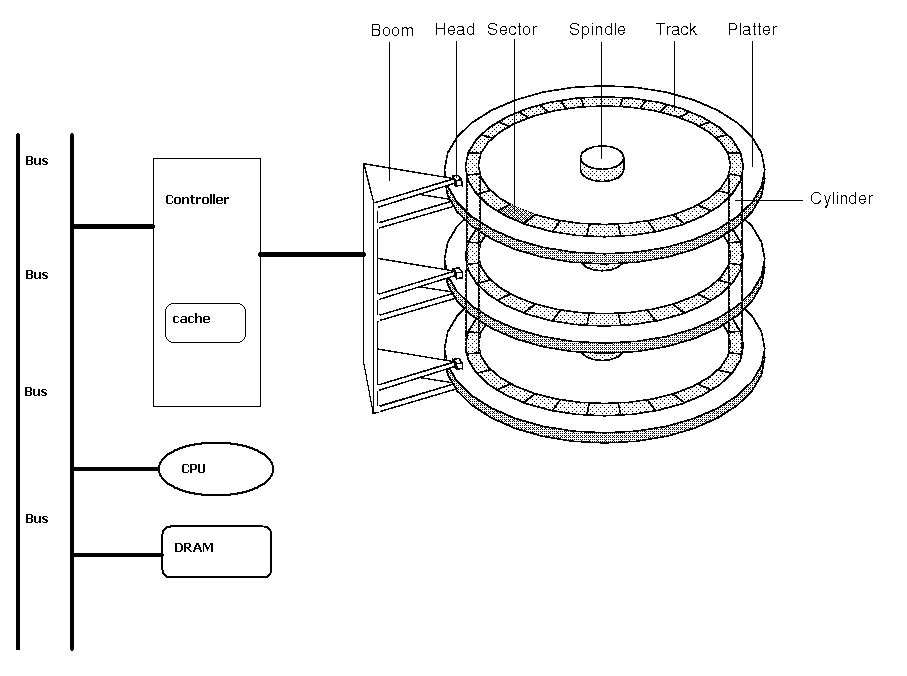
Components of Disk Latency
1. CPU issues commands to controlle
2. Controller moves read head to correct tarck->seeking
3. wait for disk to rotate to the start of the sector
4. wait for sector to pass by read head
5. transfer data to DRAM
6. inform CPU “done”
Typical disks today old desktop(WD Coviar SE16) new notebook(Seagate Nomentus 54004)
(2005) (2008)
Rotational rate(rpm) 7200 5400
Rotation time (ms) 8.333 11.111
Avg. rotational latency(ms) 4.166 5.55
Full-stroke seek (ms) 21.0
Track-to-track seek (ms) 2.0 <12
Avg. read seek time (ms) 8.9 <12
Avg write seek time(ms) 10.9 <12
Transfer rate (buffer to host) (Gb/s) 3 3
Transfer rate (buffer to disk) (Gb/s) 0.97 0.058
Cache size (MiB) 16 8
7200rpm=120Hz
1 rotation=1/120s=8.333ms
5400rpm=90Hz
1 rotation=1/90s=11.111ms
Suppose 8KB blocks
Read 1 random block; 8192
8.9ms +4.2ms+ 8192/100,000≈0.08ms+Δ≈13.2ms
avg_seek rotational transfer bit all other
latency in ms
≈13 million instructions in 1 second
For Speed: we’ll use 2 things:
1. temporial locality: access block I at time t => likely to acces block i+1 at time t+Δ
2. spatial locality: programs accessing block I often want i+1 at some i-1 time
for (;;) {
char buf[8192]
read(ifd, buf, sizeof buf); //13.2ms
compute(); //1.0ms
write(ofd, buf, sizeof buf);//15.2ms
} //29.4ms/iterations, 34iterations/sec, 272KiB/s throughput
Bottlenecks
Seek rotation xfer-rate compute
19.8ms 8.3ms 0.1ms 1.0ms
SPECULATION (general idea)
do more work than what’s needed at this time to save work later
BATCHING (can be done in O.S. or by application)
One large op is cheaper than N ops 1/Nth the size
e.g. fread( ) //maintains own buffer in userspace implemented on top of read( ).
fwrite( ), write( )
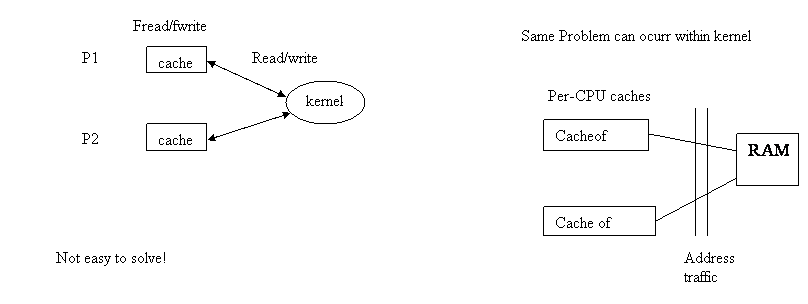
Write: DALLYING (for write) -> avoid doing work now, in hopes that it will be cheaper to do it later.
Dallying and speculation are strategies that in hope will take advantage of batching.
CACHE Coherence Problem