CS 111Scribe Notes for 03/03/08by Tharaka Somaratna and Tom WrightRAID 4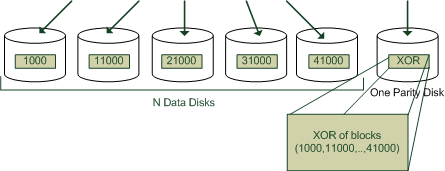 Figure 1. Whenever you write, you write twice, to two disks: Data and parity writes can be parallel. When a disk crashes, recomputed via XOR. Disadvantages
Disk Failure Notes Figure 2. Seagate’s MTTF = 300,000 ~ 35 years 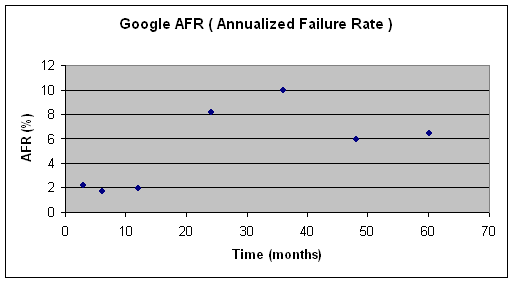 Figure 3. Shows the Google's Annual Failure Rate of Disks 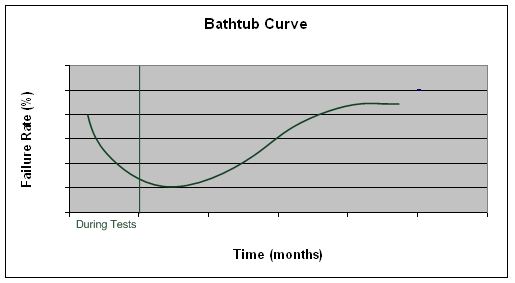 Figure 5. Disk failure rate is usually like a bathtub curve. Comparing the Google's AFR and the bathtub curve, we can see that the initial curve on the bathtub curve may be due to the testing stage of disks. 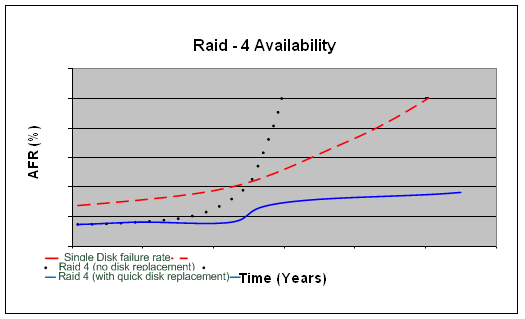 Figure 6. Raid 4 will have a low AFR if the failed disks were replaced quickly. Disk Scheduling AlgorithmsWant: high throughput (lots of data (keep disk busy)) No starvation. These two are competing goals. Simple model: N blocks, numbered 0,....,N-1 (latency + seek time) from block i to block j is |i-j| Given: a set of blocks b0,....,bm-1 to write ]. (each block number in range 0,...,N-1 Current head position: h [0:h:N) Questions and Answers
Virtual MemoryAddresses several problems at oncePrograms address memory they shouldn't Possible solutions - Hire better programmers - Use language with runtime checking -- Speed problem - Base+bounds register in hardware 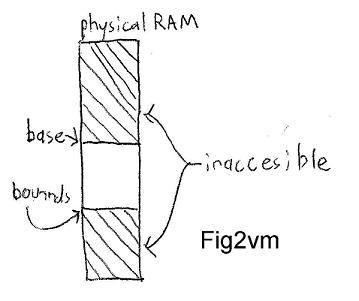
-- Common in stripped down systems -- Is this reliable? --- Per-process base+bounds --- Privileges is required to set those registers -- Is this sharable? --- Multiple threads within a single process? yes --- Share read-only parts of program? ---- Requires multiple base-bounds pairs ----- (segments) -- Problems with base bounds pairs 
--- Forcing relocateable code costs a bit --- Forces you to pro-allocate memory (fixed size programs) ----- If we assume no sharing ------ Memory references are relative to base: hardware adds base ----- If we have sharing, things get trickier because it's hard to determine base ----- To avoid the problem: ------ all your code must use relative jumps ------ e.g. gcc -fpic (position independent code) ---- Solve this problem via an extra level of indirection ---- Physical memory references almost completely decoupled from logical ones 
-- Typical model of program address space 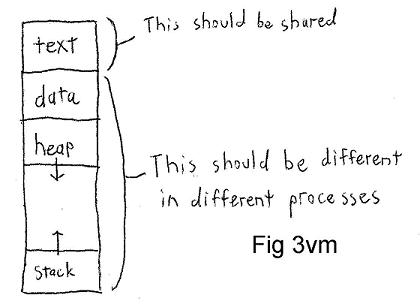
Example code from a section I labled "2-level page table"How to prevent a process from cheating(gaining access to RAM that it shouldn't) 1) setting %cr3 is privileged (this register holds the process 'address space') 2) don't let processes see own page tables 3) each page table entry contains a few spare bits (access permission bits) Procedure that hardware follows when a page is absent1) page fault 2) kernel takes control at a well specified location 3) Same rules apply for INT, and other faults What kernel can dowhen informed of the faulting address it can: 1) kill process 2) schedule a read from disk, later resume process once page is in RAM 3) on first write: allocate disk space & RAM ----- this can fail if OS over allocates pages (AIX) (can kill process due to lack of swap space) |