RPCs and NFS
Chris Dickens, Matt Sperry, and Andre Song
March 10, 2008
Instead of splitting the machine, take a natural approach with a hardware-influenced modularization, one that is suggested by the underlying network. This is nice because it fits with what you're doing.
1 Remote Procedure Calls
Remote procedure calls are to distributed systems what system calls are to a single system. Put shortly, RPCs are like syscalls, but they go to another host, not the kernel.
1.1 Properties
- Caller and callee don't share address space (this is good because there is no extra work to achieve hard modularity)
- No call by reference (because callee can't dereference pointers)
- Performance is an issue: for example, copying large objects
- Callee and caller could have different architecture
Big Endian: Most significant bit first
Little Endian: Least significant bit first
- Marshalling (generates a serial representation of a complicated data structure and sends it) (also known as pickling or serialization)
- Unmarshalling (creates complicated structures from a serial form)
- Stubs: A small procedure on the client which marshals the arguments, ships it to the server, gets a marshalled response, unmarshals the file, and returns the data.
1.2 Example: HTTP
The client sends a string to the server, and the server replies with a header and a data file.
| Client: | |
| GET / HTTP/1.0\r\n |
| Server: | |
| HTTP/1.1 200 OK\r\n |
| Content-type: text/html\r\n |
| Content-length: 10243\r\n |
| \n\n |
| Body <- HTML |
1.3 Example: X Windows
Clients: Applications
Server: Your Desktop
Writing a pixel:
| Client Actions | |
| send x |
| send y |
| send color |
| read reply |
| Server Actions | |
| read x |
| read y |
| read color |
| draw pixel |
| write reply |
Note that this is usually done via stubs, and also that it needs better efficiency.
2 RPC Issues
2.1 RPC Failure Modes
RPC's failure modes are different than that of the other systems we have discussed in this course.
- Advantages
- The callee/server cannot corrupt the caller's/client's data structures. This is because all data is always copied from the client to the server and never passed by reference. It wouldn't be possible to pass by reference because since the client and server are different systems, they do not share the same hardware resources and thus one system cannot dereference a pointer passed by another.
- Disadvantages
- Messages can get lost and/or corrupted during transmission from the client to the server.
- The network over which the systems communicate might be slow or down. From the client's point of view, both could seem like the same thing if waiting on a response from the server. The client has no way of knowing that the message successfully reached the server other than by receiving a response from the server, but with a slow or down network the client may abandon the call.
- The server may be slow or down.
To address the above disadvantages, which are really correctness issues, the following procedures can be implemented:
1. The client and server can use a checksum along with the transmitted messages as a way to verify the integrity of the received message. The client calculates a checksum before sending the message and sends its calculated checksum along with the message, and the server calculates its own checksum of the received message and compares it against the checksum passed along with the message by the client. If it is the case that the checksums do not match, the server can
a. Ignore the corrupted message OR
b. If the message is corrupted (which can be determined with a checksum), the callee can simply ignore the message, or send a "re-request error" to the caller to ask for the message again.
2. The client can timeout after a certain specified amount of time after which it will assume the message has been lost. When a timeout occurs, the client can
a. Try again
i. This is called the "At-Least-Once RPC" because it guarantees the operation will be performed at least once. It may happen more than once if, for example, the server successfully performs the operation and sends a response to the client, but the response gets lost. The client will try again not knowing the operation has already been performed, and this can repeat as many times until the client gets a response from the server.
ii. Such a method is suitable for idempotent operations where performing some operation either once or multiple times will not affect the desired outcome of the operation.
b. Give up and report an error to the caller
i. This is called the "At-Most-Once RPC" because it guarantees the operation will only be performed at most one time. If it so happens that the server performs the operation and the response from the server is lost, the same operation will not be done more than once.
Ideally, what we want is an "Exactly-Once RPC," but achieving this is theoretically impossible if data can be lost or corrupted during a transmission.
2.2 RPC Performance Problems
Consider the following diagram where a single client is sending requests to a single server synchronously.
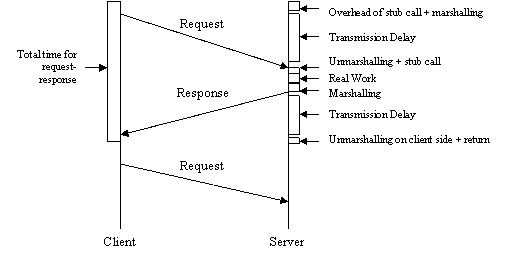
In the above diagram, there is a substantial amount of overhead in the client/server communication. The amount of "real work" done by the server in performing the requested operation is substantially smaller than the total amount of time needed for the client to send the request to the server and receive a response from the server. This scenario leads to very low utilization when there are many repeated operations that you know you want to do (e.g. read many blocks from a disk, color many pixels on the display).
To deal with this performance issue, we can
1. Add new function calls for common patterns
2. Have the client and server communicate asynchronously. That is, have the client send multiple requests without waiting for a response from the server, as in the following diagram.
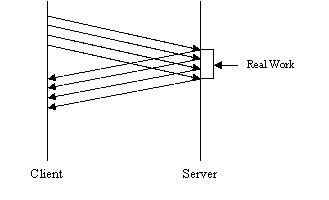
a. This method leads to a much better utilization of the server and a lower latency time. A real-world example of this is HTTP Pipelining (available with the HTTP 1.1 extension).
So if using asynchronous communication, what happens if an early request fails due to a transmission failure (lost or corrupted data) or the server rejecting the request? We can take a couple different courses of action.
1. Ignore the later responses from the server.
2. Cancel operations in progress.
a. This can be quite complicated to implement as both the client and server need to be equipped to handle this.
Something to consider with asynchronous communication is that failure reports will become less accurate. Though the requests are sent in order by the client, there is no guarantee that the responses from the server will be in order as well. One way to address this issue is to have the next similar RPC as the one that failed send a failure message as well. This lets the client know that somewhere along the line a request failed, and the client must decide how to handle the situation.
Some ways to improve the performance and utilization of the RPCs is to use a cache or to pre-fetch. If multiple similar requests are made close together, the common answers to the requests can be cached. This will work very well to increase the speed of the operation but has its limitations. It will only work if the data in the operation is stable and not changing. In addition, implementing this caching feature increases the complexity of the system, requires the use of more physical memory for the cache, and relies on cache coherence. In the same manner, if multiple similar requests are made close together, the answer can be "pre-fetched" before the request is asked. Modern computers use pre-fetching in a variety of ways to improve performance.
3 Network File System
A network file system allows an operating system to write to and read from a network resource as if it were a disk directly connected to the computer.
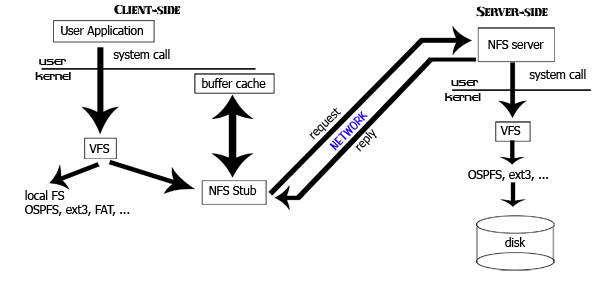 The NFS system connects via the Virtual File System, and appears to the operating system as any other disk.
The Network File System protocol contains several I/O functions:
The NFS system connects via the Virtual File System, and appears to the operating system as any other disk.
The Network File System protocol contains several I/O functions:
LOOKUP(dirfh, name)
CREATE(dirfh, name, attrs)
MKDIR
REMOVE
RMDIR
RENAME
READ
WRITE
It is not a coincidence that these represent a one-to-one correspondence with Unix system calls. The NFS system converts these calls into RPCs, which it uses to communicate with the server. Likewise, the RPCs sent from the server to the client are converted to system calls which operate on the local hardware.
3.2 NFS File Handles
NFS filehandles uniquely identify a file on a server so that the local operating system may read and write from them. Because of the tenuous nature of network connection, the NFS filehandle must remain connected to the file even through network connectivity losses and reboots of the server.
NFS filehandles take the following form: fh = device + inode# + inode_serial#. The device part tells the local machine which network device the resource is located on. The inode identifies the file on that device, and the serial number exists to prevent inode reuse.
In order to maintain reliability, the goal of the NFS system is to have a stateless server. If this were to be achieved, all operations would be reliable due to the atomicity of the server data. Some behaviors help this goal along. For example, if the server reboots, the data is consistent, and the filehandle remains correct. If the server stops responding to calls, the client will likewise freeze up to retain a measure of atomicity. And if the client freezes, the server goes about its business, because it is not receiving calls from that client.
Some interesting examples abound in consistency on NFS systems. For example, consider the following set of operations:
| Client 1 | Client 2 |
| fh = open("foo") | rename("foo", "bar") |
What will happen when Client 1 wants to access "foo"?
Renames are ok, because other processes can just use the filehandle they grabbed before. But removes are trickier, because the server doesn't know which clients have the file open. A read(fh) on a deleted file returns -ESTALE.
Consider a case in which network latency causes some clients to respond more slowly than others:
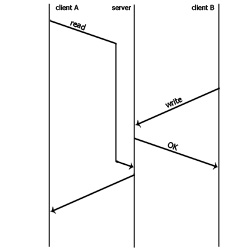 In this case, although Client A requested the contents of a file before they were changed, the server returns the contents after the write by Client B, because the network did not transmit Client A's request quickly enough.
In this case, although Client A requested the contents of a file before they were changed, the server returns the contents after the write by Client B, because the network did not transmit Client A's request quickly enough.
In most cases, there is nothing that can be done to solve these problems, due to the unpredictable nature of the network. Short of caching all operations, then "inserting" operations into the timeframe and calculating changes due to that operation, there is not a good way to stop the problem from happening, so we may as well let it.
Locking over NFS is tricky because read/write locks on a server compromise statelessness. NFSv4 has locks, but not NFSv3.
4 Acknowledgements
NFS diagram and timing diagram taken from the scribe notes of the Fall 2006 CS111 class, by Subhash Arja, Matthew Ho, Grant Jenks, and Samuel Kwok.
File translated from
TEX
by
TTH,
version 3.80.
On 15 Mar 2008, 20:21.