CS 111Scribe Notes for 1/14/08by Santoso Wijaya, Derek Kulinski, and Albert ZhuModularity & VirtualizationIncreasing modularity in last lecture's simple designOur aim is toward a more flexible API. For example, in the following function prototype
has two valuable properties:
Virtualization choices0. NoneThere is always the choice not to implement any virtualization whatsoever. Recall last lecture's sample code. The advantage to this approach (or lack thereof) is faster speed and/or performance. The downside is that the code is hard to debug and understand. It also does not scale well. 1. Function callsA common approach, this is implemented, for example, by reserving blocks in memory as "kernel" functions (implementation of a common API) to be used by other programs. e.g. Consider this simple recursive factorial function:
This code in C translates into the assembly:
So, to call
fact()'s activation record: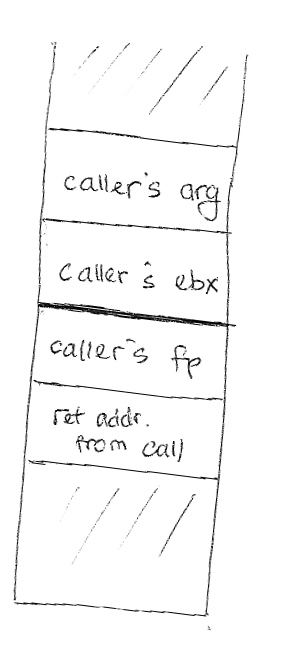 The above example shows a contract between caller and callee. This contract will uphold the stack layout meaning that the callee won't do anything to change the arguments that were pushed onto the stack by the caller. When the caller calls the callee, the contract will ensure that the return address will automatically be pushed onto the stack before the callee does anything. When returning to the caller from the callee, the contract also ensures that the return value will be stored in the %eax register. What can go wrong?
These points will all lead to a break of contract between the caller and callee, which will end in chaos! For example,
To sum up, the problem with this function calls approach is that we have a soft modularity - every component is assumed reliable - also called fate sharing. How does one attain hard modularity, where one untrustworthy component won't crash the system? 2. Hardware support for virtual machinesThis is typically done by adding more constraints to what can get called/accessed. 3. Software interpreterThis is a software approach: we emulate the hardware in a program! 4. Client-server approachA slightly more sophisticated approach is where the server is the OS, 5. OtherAbove methods aren't perfect, so there are new interesting inventions, though many of them are unsuccessful. Virtualization via Software EmulationThis is done by having the kernel contain an x86 interpreter (like JVM for example)Applications are interpretedA interpreter checks every memory access. It can establish a time limit. It can go run another program if one holds or crashes. Further, the hardware itself needs not be an actual x86 hardware. This leads to a very portable solution. The downside of such approach is, of course, a sacrifice in computing speed. We need hardware supportEnter virtualizable processor (for each application). The hardware itself is designed so that it will let the kernel take over immediately when the application does a halt or any other privileged instructions. It can also let the kernel take over periodically no matter what to examine running applications (e.g. to catch infinite loops). More importantly, it lets the kernel take control when the application accesses memory that it "shouldn't". This is not limited to RAM but also I/O devices, etc. The combination of this virtualizable processor and the OS itself lets us support the notion of a process.
In UNIX, the way one creates a process is by using:
LayeringThe term refers to the practice of building a higher level abstraction over a lower level one.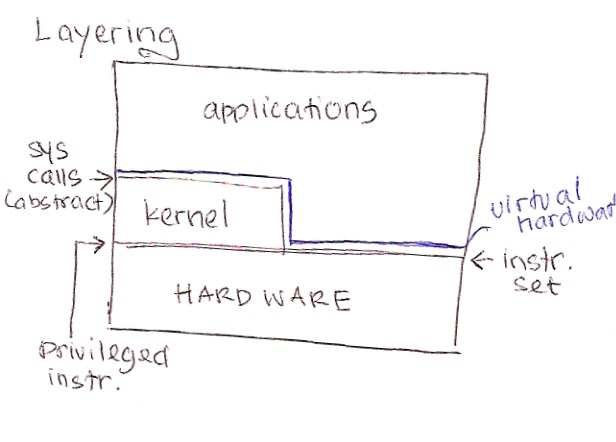
To implement, don't use function calls for this; it will result in soft modularity! Instead use protected transfer control - where ordinary apps execute unprivileged instructions at full speed, but when they execute a "bad" instructions, they trap into the OS. In effect, applications cannot fool the kernel. Applications contact the kernel by executing a "bad" instruction. On x86, the
instruction (short for interrupt) causes the processor to enter the kernel state at a location chosen by the kernel.
This is done by a lookup to an interrupt address table: 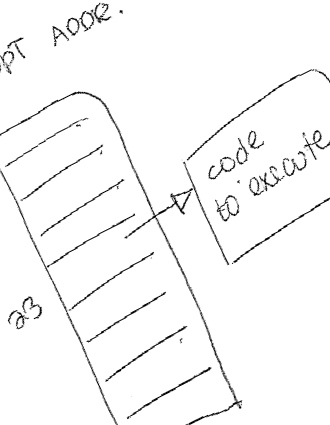
How it works:
The interrupt instructions are also called system calls. These are like function calls, but with protected transfer of control. They are slower, and can be more of a hassle (applications can't do some "reasonable" things as a result of forced hard modularity). Question to ponder: |