CS111 - Winter 2008
Lecture 7 (January 30, 2008)
by Caleb Kapusta and
Amarin Phaosawasdi
Scheduling
- Allocating resources.
- Some say, this is the core of OS creation.
Which resources?
- CPU (scarce resource)
- Network
- Disk
- Power access: CPU (busy)
- Etc.
Scale of scheduling
- Long term:
- Whether jobs are accepted in the first place; how many
can we support?
- fork() can return -1
- Medium term:
- Which processes (or parts of processes) reside in RAM
vs. disk?
- Short term:
- Which of the runnable processes get a CPU?
Scheduling metrics
- used to determine quality of algorithms
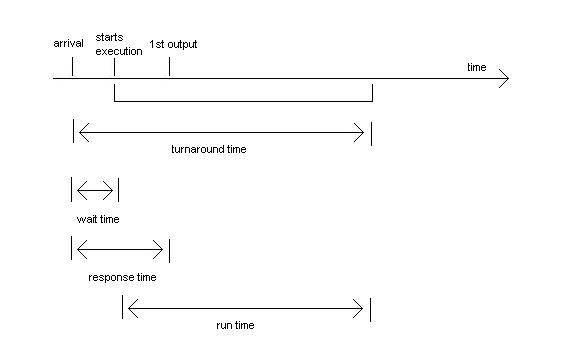
- response time: good for interactive apps (e.g. web browser)
- utilization = runtime/(turnaround time)
- throughput = runtime/(total time)
- throughput ~ utilization
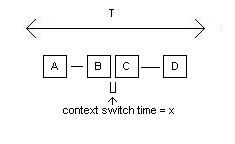
- utility = (|A| + |B| + |C| + |D|)/T =
throughput from
the CPU’s point of view
- expected wait time = average wait time, averaged over all
jobs
- worst case wait time – longest wait time,
averaged over all jobs
First Come First
Served (FCFS)
- Simplest algorithm
- Jobs serviced in order of arrival
| Job Names |
Arrival Times (AT) |
Run Times (RT) |
Wait Times (WT) |
Turnaround Times (TT) |
| A |
0 |
5 |
0 |
5 |
| B |
1 |
2 |
4 + x |
6 + x |
| C |
2 |
9 |
5 + 2x |
14 + 2x |
| D |
3 |
4 |
13 + 3x |
17 + 3x |
- TTi = WTi + RTi
- WTi = ATi-1 +
TTi-1 – ATi + x

- Average WT = 5.5 + 1.5x
- Worst case WT = 13 + 3x
- Utilization = 20/(20 + 3x)
- Average TT = 10.5 + 1.5x
Advantages
- Simple
- “fair” in some sense
Disadvantages
- One job can hog system, making other jobs wait; therefore
average wait time goes up (due to the convoy effect).
- Assumption: we know run times
Shortest Job First
(SJF)
- Scheduler dispatches shortest available job first.
- Assumption: we know the run times ahead of time.
| Job Names |
Arrival Times (AT) |
Run Times (RT) |
Wait Times (WT) |
Turnaround Times (TT) |
| A |
0 |
5 |
0 |
5 |
| B |
1 |
2 |
4 + x |
6 + x |
| C |
2 |
9 |
9 + 3x |
18 + 3x |
| D |
3 |
4 |
4 + 2x |
8 + 2x |

- Average WT = 4.25 + 1.5x
- Average TT = 9.25 + 1.5x
- Throughput = 20/(20+3x)
Advantages
- Shorter average wait time than FCFS.
Disadvantages
- C loses, but D gains more than C loses
Can we improve even more on average wait time?
- Yes, if we are allowed to schedule “no
job” and
you know jobs that will come in the future.
- Yes, if
we are allowed to pre-empt jobs.
- Otherwise, no!
Problems
| Job Names |
Arrival Times |
Run Times |
| A |
0 |
3 |
| B |
0 |
2 |
| C |
1 |
2 |
| D |
3 |
2 |
| E |
5 |
2 |
| F |
7 |
2 |
| X |
2x + 1 |
2 |
Job A waits forever.
Round Robin
If one process uses the CPU more than a quantum time Q (usually
configurable), it is preempted and has to continue its job in the next
round.
Suppose Q = 2, then the jobs in the table below would be scheduled as
follows.
AA.BB.CC.DD.AA.CC.DD.A.CC.CC.C
where the dot represents context-switching.
| Job Names |
Arrival Times |
Run Times |
Wait Times |
Turnaround Times |
| A |
0 |
5 |
0 |
5 |
| B |
1 |
2 |
4 + x |
6 + x |
| C |
2 |
9 |
9 + 3x |
18 + 3x |
| D |
3 |
4 |
4 + 2x |
8 + 2x |
When we compare round robin to FCFS and SJF, we can see that the
waiting time is better, but the turnaround time gets worse.
The waiting and turnaround time actually depends on Q.
Observations
- The average wait time increases as we increase Q.
- The turnaround time decreases as we increase Q.
- If Q is infinity, round robin becomes equivalent to FCFS.
- If Q = 0, no job is done except context switching.
Problems
| Job Names |
Arrival Times |
Run Times |
| A |
0 |
3 |
| B |
2 |
2 |
| C |
4 |
2 |
| D |
6 |
2 |
| E |
8 |
2 |
| F |
10 |
2 |
| X |
2x |
2 |
The round robin algorithm schedules the jobs as follows.
AA.BB.CC.DD.EE.FF... and so on, but A never gets executed again
(starvation).
Solution
Each job arrives at the end of the queue. This way, jobs that have
already started would be executed first if its round coincides with an
arriving process.
Priority Scheduling
In the real world, some jobs have more importance than others and
should be executed first. Examples include interactive applications.
Convention
Small number = high priority. For example, priority 1 is more important
than priority 2.
Observations
- Arrival order is priority in FCFS
- Service time is priority in SJB
We now introduce other priorities which are
- external priorities which are priorities set by the user.
- internal priorities which are calculated by the OS.
Problems
| Job Names |
Arrival Times |
Run Times |
Priorities |
| A |
0 |
5 |
2 |
| B |
1 |
2 |
2 |
| C |
2 |
9 |
0 |
| D |
3 |
4 |
1 |
The priority column is the external priority set by the user.
Suppose Q = 2, the job scheduling would be as follows.
AA.CC.CC.CC.CC.C.DD.DD.BB.AA.A
Solution
We can see that jobs with low priority can still starve, so we need
what is called priority aging, which means that the longer the process
lives, the lower its priority becomes. Priority aging is an example of
internal priorities.
Real world
scheduling problems
Problem 1: Priority Inversion
Suppose we have three jobs, namely, IO, Med, and High.
Tio is an input/output job with the lowest
priority. It acquires a lock,
computes, and returns the lock.
Tmed is a medium priority job.
Thigh is a high priority job and also needs the
same lock.
| Time |
Tio |
Tmed |
Thigh |
| 0 |
(runnable) |
(waiting) |
(waiting) |
| 1 |
lock
( &m ) |
|
|
| 2 (context switch) |
|
(runnable) |
(runnable) |
| 3 |
|
|
lock
( &m ) |
| 4 (context switch) |
(runnable) |
(runnable) |
(blocked) |
At time 0, only IO is runnable, so IO is scheduled.
At time 1, IO acquires the lock.
At time 2, Med and High become runnable. Context switch, and High gets
its turn.
At time 3, High needs the lock, but IO has it, so High blocks.
At time 4, Medium gets its turn because it has higher importance than
IO.
The problem is that Medium should not be scheduled when High is still
in the loop.
Solution
High can "lend" its priority to IO when it wants some resources from IO.
This way IO will have higher priority than Med until it releases the
lock.
Problem 2: Receive Livelock
Suppose we have a buffer that receives external network packets. The OS
reads these packets and service them (by which point, the packets will
be removed from the buffer.)
Packet entries cause interrupts which are more important than servicing.
During busy times, when packets arrive rapidly, instead of doing
servicable work, we are only handling interrupts.
This can also be viewed as a denial of service.
