CS 111 Lecture 8Scribe Notes for 2/04/08by Chris Swan and John CarterSynchronizationSynchronization solves the problem of coordinating activities in a shared address space, like the one we have in a threaded system. This can either be a truly parallel system (i.e. a multiprocessor system) or just a multitasking OS.Processes vs. Threads:
One of the major goals of synchronization is to avoid race conditions - situations in which behavior depends on execution order in an undesirable way. Ordinarily, threads are unsynchronized objects. They are allowed to execute in parallel with little to no communication between them. This is fine in some cases, such as when they are only accessing their own sets of data. In other cases it may spell disaster. We want to accomplish the following:
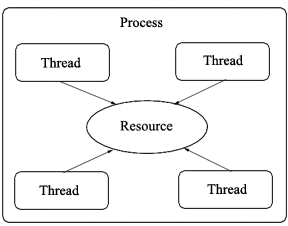
The following figure shows a situation that might benefit from synchronization:
In this diagram, several threads within a process are trying to access the same resource. Depending on the order and nature of their accesses, the behavior of this unsynchronized system could be unpredictable. When problems begin to surface due to the unsynchronized nature of threads, several techniques may be employed to alleviate the anomalous behavior. The following example helps to illustrate the core idea of these type of problems before these solutions are outlined: Example: Simultaneous Bank Withdrawals Suppose we're designing a multithreaded bank ATM system that manages accounts. Accounts have a balance, which cannot be negative, and can be deposited to or withdrawn from at any time from any ATM. The simplest possible implementation of this functionality would look something like this: void deposit(unsigned int amt) { balance += amt; }
void withdraw(unsigned int amt) { balance -= amt; }
Of course, the withdrawal code should make sure the account has enough money and should be changed to: void withdraw(unsigned int amt) {
int new_balance = balance - amt;
if(new_balance < 0)
return;
balance = new_balance;
}
Now let's have two threads executing these primitives at the same time. Paul and his brother Kurt happen to share an account with a balance of $100:
balance = 100; Paul: withdraw(100); //these two operations are performed Kurt: withdraw(100); //at different ATMs at the same time Pretend for a moment that we're using the version of withdraw() without error-checking, as it's irrelevant right now. Both Paul and Kurt's threads execute assembly code resembling the following: withdraw(d){
movl balance , %eax
subl d , %eax
movl %eax , balance
}
Paul and Kurt's ATMs both load the current balance, $100, into a register. They both subtract $100 from that value, and store the resulting value, $0, back into memory as the new balance. Both ATMs dispense $100 and the current balance is now $0. Everything worked perfectly! ...or did it? The bank has been defrauded of $100 because access to the shared balance variable was not protected! It's tempting to fix this problem with a global "busy" flag that's checked before manipulating balance, but that fails for the same reason -- both threads would check the value of the flag at the same time, then continue on as before. Before we attempt to solve this problem, let's look at the theory behind it. Some theory and definitionsWe can keep a multi-threaded environment running properly in two different ways:
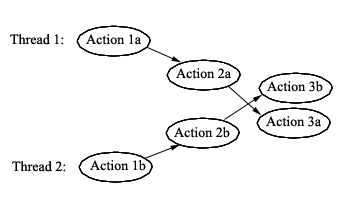
This figure illustrates the execution paths of two threads colliding, which can lead to problems. Ideally, the operations of two threads never collide (operate on the same data) and the system is therefore fully isolated. This situation is called "embarassing parallelism". In systems that are not embarassingly parallel, full isolation isn't possible, so we must rely on sequence coordination. This is accomplished through atomicity. An atomic operation enforces coordination: task X is done either all before or all after task Y, as a single unit. That is, the task is atomic if it is computationally indivisible. Caution! One should be careful in C for instructions that might appear to be indivisible such as balance+=amt; This instruction is not atomic because internally the machine code for it is implemented using a series of load, add, and store instructions which can be interrupted any time in between. Some key metrics used to classify the properties of a synchronous system are observability and serializability.
We implement atomic operations in software through critical sections. A critical section is a set of instructions executed by a thread such that atomicity is preserved if, at most, one thread's instruction pointer is in that section at any given time. In order to make critical sections work, this constraint must be enforced. However, we have two subproblems: mutual exclusion and bounded wait. First we'll look mutual exclusion. Mutual exclusion means that only one thread has access to a certain resource at a given time. We might implement that through locking. typedef int lock_t; lock_t l; void lock(lock_t *p); void unlock(lock_t *p); If a thread calls lock, it will wait until no other thread has a lock, and then it will take the lock. Unlock releases a lock. Both of these operations must be atomic. We could use the lock like this: void deposit(unsigned int amt){
lock(&l);
balance += amt;
unlock(&l);
}
Of course, we still have to implement lock() and unlock(). Here's a naive implementation: void lock(lock_t *p){
while(*p) continue;
*p = 1;
}
void unlock(lock_t *p){
*p = 0;
}
This looks great! Too bad it doesn't work. Imagine two threads attempting to make a lock at the same time: we
have the same race condition problem as before. To make lock()
work, we need hardware support in the form of a new machine
instruction. This is usually implemented in the form of the assembly
instruction xchg, which swaps the value of two registers or
memory locations. It can be used to implement a function called
test and set that provides the following behavior:
int tas(int *p, int new){
int old = *p;
*p = new;
return old;
}
Because it actually uses the xchg instruction, which is
atomic, test and set is also atomic. Using it, we can
re-implement lock() like so:
void lock(lock_t *p){ while(tas(p,1) == 1) continue; }
This is called a busy wait, or spinlock, because the
thread wastes CPU cycles "spinning" until it gets the lock. Now our
deposit and withdraw functions, armed with locks, are safe to use in
a multithreaded environment. One thing to note, however, is this
magical xchg instruction comes at a cost. The xchg instruction
is rather slow and computationally expensive because it must take
special care in coordinating bus activity to ensure no other CPU
will interrupt it.
You should also note that this type of scheme relies on the assumption of read-write coherence. As long as reading and writing to an integer is atomic, we're in business. However, this assumption is often false. On the x86 architecture, loads and stores of 32-bit quantities that are aligned on 4-byte boundaries are guaranteed to be atomic. For data structure of larger or smaller size, such as large arrays or bit fields, atomicity is not guaranteed. Imagine the following example:
Similarly, for smaller objects:
That's not the whole story, though: we've neglected the earlier-mentioned problem of bounded wait. Imagine that Paul wanted to transfer some money by depositing money into the shared account for Kurt to withdraw. Kurt's a little impatient, and attempts to withdraw before Paul can deposit anything. When that request fails, he tries again. Eventually, he's just mashing the "withdraw" button on his ATM, waiting for the cash. When Paul finally submits his deposit, the lock is taken by the withdrawal thread. As soon as the lock is released, Kurt starts up another withdrawal, and that thread is now competing with the deposit to re-acquire the lock. It's very possible that the withdrawal threads will continue to beat the deposit to the punch. The solution is to have some sort of queue that ensures threads are able to acquire locks in the order that they request them. If we implement this properly, we can also get rid of the busy-wait problem that spinlocks suffer from. The standard solution to these problems is through implementation of what is known as a blocking mutex. A blocking mutex(a portmanteau of mutual exclusion) has a spinlock for access to the mutex itself and also contains a wait queue which contains a list of threads that are waiting to resume. Building upon the previous spinlock_t structure, we introduce the following:
Although not exhaustively defined in these notes, the blocking mutex is a step forward in addressing the wastage problems of the spinlock and its strengths and weaknesses will continue to be explored in the lectures to come. |
|
|