CS 111 Winter 2012
Lecture 10: File System Performance
by Daniel Ichwan and Seungdo Lee
for a lecture by Professor Paul Eggert on February 15, 2012 at UCLA
Table of Contents
- Storage Devices
- Disk Drive
- Solid State Device (SSD)
- Hybrid Device
- Random Read/Write Performance
- Improving Read/Write Performance
- Sequential Read/Write Performance
- Batching
- Multitasking
- Direct Memory Access (DMA)
- Further Read/Write Improvements
Storage Devices
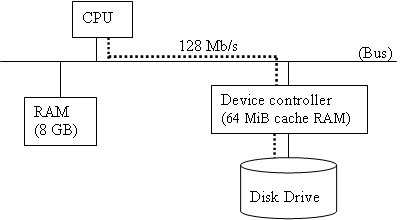
In this lecture, we handle the topic of file system and its performance. To understand the performance for the overall system, we will first look at its low level building blocks, the secondary storage device. We observe two different types of storage devices: the disk drive and flash memory.
|
Seagate Barracuda XT
3TB 7200RPM Hard Drive |
|
Corsair Force 60GB SSD |
| Read Seek Time |
8.5ms |
Read Speed |
up to 280MB/s (sequential) |
| Write Seek Time |
9.5ms |
Write Speed |
up to 270MB/s (sequential) |
| SATA Transfer Rate to Bus/Cache |
6 Gb/s |
Random Data Transfer Rate |
700 Mb/s |
| Sustained Data Transfer Rate |
130 Mb/s |
|
|
| Power Consumption |
9.23W (operating)
6.39W (idle) |
Power Consumption |
2.0W (max operating)
0.5W (idle) |
| Operating Shock |
63 Gs for 2ms |
Operating shock |
1000Gs for 2ms |
| Non-Operating Shock |
300 Gs for 2ms |
Non-Operating Shock |
1000Gs for 2ms |
| Price per GB |
$290/3TB = $0.10/GB |
Price per GB |
$143/60GB = $2.40/GB |
(A) Disk Drive
(B) Solid State Device (SSD)
SSDs act like disk drives but are internally based on NAND flash technology.
- Flash have slower random (versus sequential) reads/writes
- Flash memory wear out if keep writing to the same location - so one shouldn't write to the same block over and over again.
Possibly why writes are slower than reading in SSD because need to determine write location based on a wear-leveling algorithm.
Wear-Leveling Algorithms
These algorithms prevent favoring blocks when writing to flash memory. These algorithms are either in (A) device controller or (B) in OS/CPU.
- (A) Device Controller
In a device controller, the wear-leveling algorithm is independent of OS scheduling. Both the disk and the SSD will look like a disk drive. But
if the OS wants to use the real disk efficiently, this abstraction has performance issues because disk drive optimizations will be wasted if the device is actually
an SSD.
- (B) IN OS/CPU
If the wear-leveling algorithm is implemented in the OS, the device can be identified as a SSD or a disk drive; therefore, specific device optimizations
can be done, but the OS may be a source of complexity and bugs.
(C) Hybrid Storage Device
- If you want both the benefits of having a large memory non-cheap disk drive and fast transfer rates of the SSD,
a "hybrid drive" can be created by attaching an SSD and disk drive to a mutual device controller. The device controller
can initially write to the SSD and later, when the system is not busy, the data can be transferred from the SSD to the disk drive
- In this setup, the SSD acts as a stable cache for the hard disk; whereas RAM is an "unstable" cache because it will lose data if there
is power loss.
- But since hybrids are expensive, one can merely buy a group of disks and masks as RAID (redundant array of independent disks)
- Note: For pedagogical simplicity - only one non-hybrid device is chosen.
Random Read/Write Performance
0 char buf[8192]; // buffer: 16 sectors of 512 bytes
1 for (;;) {
2 lseek (ifd, random_location, SEEK_SET); // set the read offset to a random location
3 n = read(ifd, buf, sizeof buf); // ifd = input fd
4 n1 = compute(buf, n); // a generic process that will transform the buffer without changing its size
5 lseek(ofd, other_random_location, SEEK_SET); // set the write offset to a random location
6 write(ofd, buf, n1); // ofd = output fd
7 } // assume raw drive
For the given code above, we will assume a few things:
- Using a raw drive and independent disks (one for reads, one for writes)
- n = n1
- n = sizeof buf
- Application instructions: 0.01μseconds
- Syscall overhead: 1μsecond
- I/O instructions: 10μseonds
We can observe the latency of each computation from the code above in the following breakdown:
- Line 2: overhead = 4.16ms latency + 8.5ms average seek time
- Line 3: 4.16ms latency + 10.11μseconds (overhead for reading)
- Line 4: average 10ms
- Line 5: write latency = read latency + 1ms
Total latency per iteration of random read/write loop
| Latency |
2(4.16ms) = 8.32ms |
| Seek |
8.5ms + (8.5ms+1ms) = 8.32ms |
| Syscall |
0.04404ms |
| Computation (using 8KB buffer) |
10ms |
= 8.32ms + 18ms + 0.04404 ms + 10ms = 36.36404 ms per iteration
→ Bytes per second: 8192 bytes/.03636s per iteration = 225,302 bytes/second (This is terrible!)
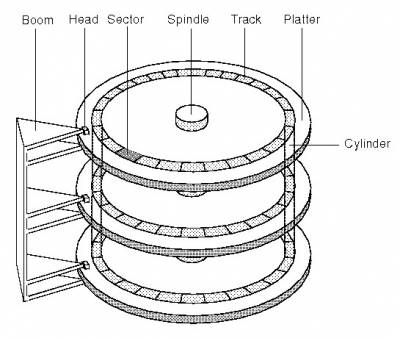
- Average rotational latency: average time to read off a sector from disk drive (from time of request to time of completed read)
Improving Read/Write Performance
Random read/write performance is usually terrible. There are many ways to improve this performance; we will discuss the bolded ones in detail:
- Sequential Read/Write Performance
- Batching
- Multitasking
- Direct Memory Access (DMA)
- Direct Memory Access (DMA) with POLLING
- Caching
- Pre-fetching
- Speculation
- Dallying Writes
(A) Sequential Read/Write
To minimize seek time, this process should be sequential. This can be done in the code by removing the lseek() calls, which
retrieved the data from random locations, allowing the new code to read/write sequentially:
0 char buf[8192];
1 for (;;) {
2 n = read(ifd, buf, sizeof buf);
3 n1 = compute(buf, n);
4 write(ofd, buf, n1);
5 } // assume raw drive
(B) Batching
The concept of batching is quite simple - use larger blocks/buffers when reading/writing:
0 char buf[1024*1024]; //buffer: now 1MB (vs 8kB)
1 for (;;) {
2 n = read(ifd, buf, sizeof buf);
3 n1 = compute(buf, n);
4 write(ofd, buf, n1);
5 } // assume raw drive
Total latency per iteration of batched read/write loop
| Latency |
2(4.16ms) = 8.32ms |
| Seek (track-to-track) |
0.030ms |
| Syscall |
0.02202ms |
| Computation |
(10ms/8kB)*(128kB/MB) = 1280ms |
= 8.32ms + 0.30ms + 0.02202 ms + 1280ms = 1288.64202 ms per iteration
→ since each iteration processes a MB → 1MiB/1288.62 ms = 813,000 bytes/s
- Note that while larger blocks are generally better, if the block size is too big (e.g. 1GB), batching may be disadvantageous:
- Data cannot be contained in Level 1/Level 2 cache → communication is now slower since the operation must communicate with RAM
- More awkward track management - the large batch might have a read that ends at the end of a track and must therefore seek another track
- Law of Diminishing Returns - one will not reduce the latency per byte after a certain point
(C) Multitasking
When reading, also schedule something else that can be done simultaneously: (i.e. in read's implementation: read(...) { ... schedule() ... }).
Multitasking could possibly eliminate effective latency and seek time if scheduled properly, but adds the penalty of context switches.
Total latency per iteration of multitasked read/write loop
*Using non-DMA and only 8KB buffers (vs 1MB)
| Latency (multitasking) |
0 |
| Seek (multitasking) |
0 |
| Syscall |
0.02202ms |
| Computation (using 8KB buffer) |
10ms |
| Context Switches (multitasking) |
.1ms/swich * (4 switches) = 0.4 ms |
= 0.02202 ms + 10ms + .4ms = 10.42202 ms per iteration
→ since each iteration processes 8 KiB → 8192/10.42202 ms = 800,000 bytes/s (comparable byte/s rate to batching)
(D) Direct Memory Access (DMA)
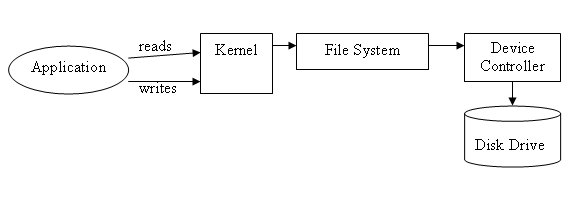
In DMA, don't use the programmed I/O approach (see Lecture 2) (CPU intermediates reads from disk controller to memory), but now
the disk controller talks directly to RAM. Non-DMA approaches have the added latency of 0.5ms for CPU mediation. This leads to the file system acting
as a level of indirection between the application and the device controller:
0 char c;
1 for (;;) { // read/write one byte at a time
2 read(ifd, &c, 1); // each read = seek + latency + etc = ~14ms
3 write(ofd, &c, 1);
4 }
(E) Direct Memory Access (DMA) with POLLING
If the DMA approach is used without context switching (i.e. polling only), there is only one process with asynchronous I/O. This allows for the elimination of
the latency from context-switching.
(F) Caching
In caching, when a read is done, the entire sector is retrieved preemptively. So if more bytes are read from that sector later on, they may be quickly
retrieved from the cache (versus actually reading from the disk).
(G) Pre-fetching
If the file system sees a read from a given sector, the next few sectors will be read preemptively to reduce overhead. This approach is based on the Principle of
Spatiality (a special case of speculation (see next section)), which predicts data nearby recently fetched data will probably be used as well.
(H) Speculation
In speculation, the file system anticipates what the application will do/need next and retrieves the necessary data preemptively.
(I) Dallying Writes
In dallying writes, a write to the disk will instead be written to cache. The file system will eventually write this cached data to the disk when there is
CPU downtime. This dallying approach allows the file system/CPU to hold off on longer writes and instead return quickly and do more useful work. An added
side effect of dallying writes is that reads of the dallying data will be faster as it is stored in cache and does not have to be read from disk.