Lecture 10: File System Performance
CS 111 Winter 2012
Written by Sayan Samanta, Saqib Mohammad, Ju Young Park, Lawrence Huang
Example Disk – Seagate XT Barracuda 3 TB hard disk drive:
Example Disk – Corsair Force solid state drive 60 GB:
Optimized version 1 (sequential access):
Optimized version 2 (batching):
Optimized version 3 (multitasking):
Optimized version 4 and beyond:
Summary of optimization methods
A file system is an abstraction of storing data in a method such that there will be consistent, reliable behavior during start up and execution.
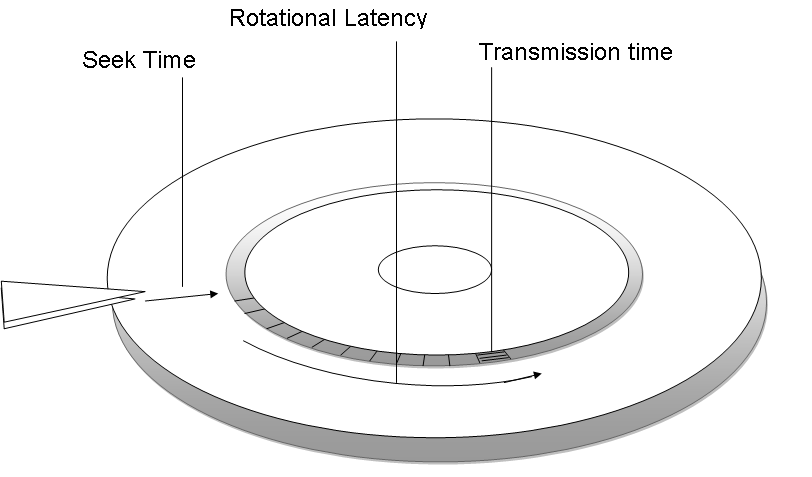
During the initial design stages of UNIX disks were faster than their CPU counterparts. Therefore, the premium was to minimize the amount of time spent by the CPU running file system code. The current issue is that CPU’s dominate disks in terms of speed, so the current model has changed to focusing on minimizing the amount of disk access time.
A disk is…
A disk has…

The overall mechanism for an average read can be as follows:
disk -> cache -> RAM -> CPU
disk -> cache -> CPU
1 char buf[8192];
2 for(;;) {
3 lseek(in_fd, in_offset, SEEK_SET);
4 n=read(in_fd, buf, sizeof(buf));
5
6 n1=compute(buf, n);
7 lseek(out_fd, out_offset, SEEK_SET);
8 write(out_fd, buf, n1);
9 }
Let’s analyze the time spent in each line of code:
Time for each loop iteration:
8.32 ms latency
18 ms seek time
0.04404 ms syscall overhead
10 ms compute time
-------------------------------------------------
= 36.36404 ms / iteration
Each iteration covers 8192 bytes, we have a performance of 8192 / 0.03636 ≈ 225 kBps
This is not a very efficient way to do file I/O, and we propose some basic optimization ideas:
remove all lseek by accessing drive sequentially
1 for(;;){
2 n=read(fd,buf,sizeof(buf));
3 n1=compute(buf,n);
4 write(old,buf,n1);
5 }
Assuming the device is a RAM drive, we now have a seek time of almost 0 (except for initial track-to-track seek time). Suppose our drives have 1000 tracks/platter, and the hardware seek time is 1.8ms for each 1-GB track. This means we will spend an average of 0.0144ms per 8 KiB, so we say seek time is now about 0.015 ms for each access (0.03 total). In this implementation there are 2 fewer system calls, also cutting that time in half (0.02202ms).
Loop iteration time after implementing sequential access:
8.32 ms latency
0.03 ms seek time (down from 18 ms)
0.02202 ms syscall
10 ms compute time
-------------------------------------------------
= 18.372ms / iteration on average, which is about half of what we needed in our prototype.
We now have a performance of about 450kBps!
Use 1MB buffers instead of 8KiB
1 char buf[1024*1024];
Loop iteration time:
8.32 ms latency
0.03 ms seek
0.02202 ms syscall overhead
1280 ms compute time
-------------------------------------------------
= 1288.37202 ms / iteration, but we are processing 1MB instead of 8KiB of data.
Therefore, we now we have about 795kBps.
Why not use even larger buffers? Say 1GB for example?
Let CPU do other computations while waiting for disk I/O (assuming 8KiB buffers)
Since we know there is going to be a few milliseconds of latency on the read/write system calls, we can schedule another process and perform useful computations while waiting. Under this implementation, there will no longer be seek delay or latency issues, because we are never idling. However, this does introduce an extra context switching overhead of, say, 0.4 ms.
Total time for loop
0.02202 ms system call overhead
10 ms compute time
0.4 ms context switching overhead
-------------------------------------------------
= 10.42202 ms per iteration of 8KiB. So after now we have about 800kBps throughput.
We can use better caching or speculating methods, which are heavily dependent on the specifications of hardware and application that is being run. However, since the unavoidable data computation takes up almost 96% of our total computation time, further optimizations are not going to introduce dramatic performance improvements.
Optimization methods | Original throughput | Optimized throughput | Speedup rate |
Original (unmodified) | 225 kBps | N/A | N/A |
Sequential Access | 225 kBps | 450 kBps | 200% |
Batching at 1MB | 450 kBps | 795 kBps | 177% |
Multitasking | 450 kBps | 800 kBps | 178% |
Others | 800 kBps | N/A | N/A (low) |