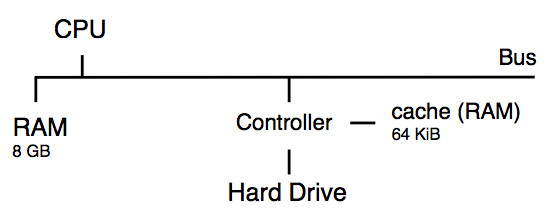
 Diagram of a computer architecture showing the secondary storage system.
Diagram of a computer architecture showing the secondary storage system.
A file system manages data that is meant to be stored after a program
terminates by giving prodedures to read, write, and update data on the
device(s) that contain it. What makes a filesystem effective? How can
we measure and increase performance of filesystems?
Storage devices can come in many different styles, this lecture focuses on two of the
most popular:
1) Disk
2) Flash
CPU speed grows exponentially while HDD speeds is closer to linear. We have
incommensurate scaling, which suggests our HDD can bottleneck our system.
Diagram of a computer architecture showing the secondary storage system.
This means increasing operations of these storage devices can give a huge boost in performance in our system. There are many ways to do this with each method having its own set of tradeoffs. We can change our device itself to provide faster mechanical operations, or we could change our filesystem which manages the procedures and algorithms for our data is read or written onto these devices.
Note: Prices are higher than usual due to Thailand floodings
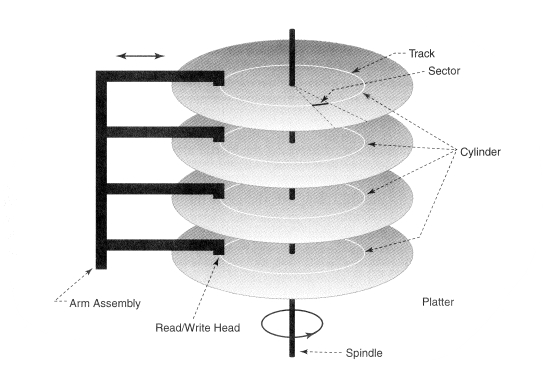
Disk: Seagate Barracuda XT 3TB (~$290 or ~$.10/GB):
- 3,907,029,160 sectors
- 64 MiB cache
- 7200 RPM (120 Hz)
- 138 Mb/s sustained data transfer rate
- 300 Gs non-operating shock
- 300 g in weight
- 4.16 ms average latency
- 8.5 ms random read seek time
- 9.5 ms random write seek time
- Unrecoverable read errors occur 1 in 1014 reads
- 9.23 watts operating, 6.39 watts idle
Have the controller take care of it. This provides a nice abstraction but can run into performance issues.
Have the OS (CPU) take care of it. Better performance at the cost of complexity.
Solid-State Device (NAND Flash): Corsair Force 60GB (~$135 or $2.25/GB)
- 1000 Gs shock
- 80 g in weight
- 280 MB/s sequential read
- 270 MB/s sequential write
- 1,000,000 hours mean time between failures
- 2 watts operating, 0.5 watts idle
As you can see SSD beat disks in almost every measure except for price. How can we get the best of both hard disk drives and solid-state devices? Hybrid drives are hard disk drives with a small SSD that acts as a buffer. Hybrid drives have a lower price-per-gigabyte compared to a comparable SSD and better performance than a disk drive.
Let's say we are given the following code:
// Assume n=n1, n = sizeof buf for sake of simplicity
char buf[8192];
for (;;) {
lseek (ifd, randomlocation, SEEK_SET);
read (fd,buf, sizeof buf);
n1 = compute (buf, n);
lseek (ofd, otherrandom, SEEK_SET);
write (ofd, buf, n1);
}This reads 8MB from a given location. What are some of the sources of slowness from this?
- lseek overhead, 4.16 ms latency + 8.5 ms avg. seek time
- read overhead, 4.6 ms latency
- write overhead, 5.6 ms latency
- compute latency 10 ms
- .001 μs application instructions
- 1 μs system call overhead
- 10 μs I/O instructions
TOTAL: ~36.36 ms, or 225,302 bytes/sec
This is SLOW! However there are a number of ways to improve our performance. The following are methods starting from the most effective to the least:
lseek is slowing things down considerably. If we get rid of lseek and access data sequentially we can assume that seek time is 0 (although in reality there is a small amount of time when finding the first section of memory).
Batching is the idea that we read larger blocks of memory. This will greatly improve our performance
however be careful as making our blocks too large can cause problems.
- L1/L2 cache overflows
- Awkward track management
- Diminishing returns (increasing the size further will have little performance gain after a certain point).
Gives roughly the same performance gain as batching.
-.02202 ms (*) system call overhead
- 10 ms for compute
- .4 ms (*) context switching
- ~800 KiB/s
With programmed I/O (lecture 2), the data from the disk controller has to go through the CPU into RAM. In DMA, the disk controller can talk directly to RAM. - Gets rid of the need for system calls
- Just polling
- 1 process asynchronous I/O
- ~830 KiB/s
The file system stores the most recently read sector, decreasing overhead.
The file system reads the next sectors as well, removing the need to seek them later
File system guess which sectors will be needed in the future and caches them for faster access.
Similar to prefetching but in the context of writes instead of reads. When a sector is written to it stores it in memory instead of the disk until that sector is no longer being written too. This saves the file system from making unnecessary writes.