
Scribes: Zhen Zhou, Ding Zhao, and Haixiang Huang
Here, Process2 thinks it is reading the file by reading the cache belongs to it,
However, the actual file content has been changed after process1 writes to the file.
FIX: Don't give each process different cache. Make cache belongs to file (instead of process), and lock cache (when doing I/O)
write(); write(); write(); //what the process thought: write to disk //what actually happened: write to cache write(done); //to user //but what if it crashes here?
Look into above code,
several writes have been issued to files, and users have been received message "done".
However, what's actually happened is processes thought they were writing to disk while really they were writing to cache.
What if the system crashes at this time with all the contents in the cache?
The sync() function commits to disk all data in the cache.
Sync(); //flushes entire cache to Disk
However, since it is too global, most of the applications would be slowed down just to protect one application.
Let's look at another approach fsync(fd).
It flushes data of the file referred to by the file descriptor fd to disk.
The data here include both the real data and the metadata about the file. This approach could be slow because writing metadata also takes a while.
fsync(fd); //flush this file blocks to disk
It flushes data of the file referred to by the file descriptor fd to disk.
The data here include both the real data and the metadata about the file. This approach could be slow because writing metadata also takes a while.
The last one is:
fdatasync(fd); //only flush data, not meta data
This one is fast and useful, since sometime user do not care about timestamps, size, etc.
Suppose that your are going to design a file system with the following requrements:
Since you want each disk as cheap as possible, but also with maximum capacity.
You choose 600 GB drives. A simple calculation gives that 200,000 disks are needed.
Then you run into problems:
In the following sections, we are going to talk about several file systems that may become the solution.
Now we try to design a simple file system.
| 512 bytes sectors (directory) | file1 | file2 | file3 | <--------------------data--------------------> |
Directory: array of directory entries (each directory entry is 256 bytes (total 200 entries))
Each directory entry has the following structure:
| 0/1 (in use) | time | start | length | Name |
The 1972 RT-11 behaves just like the above, in which RT stands for real-time. Because it reads file sequantially, and predictability is ensured.
Problem 1 fragmentation
A. internal.(small) e.g., a file has a size of 20^20-3 bytes. Then only 3 bytes are not used.
B. external (big deal)
II. Preallocation Required
A. shrinking is easy. Growing is docey.
B. directory size is fixed. (perhaps it is set at filesystem creation time)
FAT stands for File Allocation Table
The goal to have FAT File System is to resolve two issues
1. External Fragmentation
2. Preallocation
The layout of FAT File System:
| boot sector | Super Block | FAT | <--------------------data--------------------> |
Super Block:
The beginning of the Super Block contains block number of first block of root directory
The Super Block is small, and its size is fixed.
The Super Block also contains Meta Data About File System
The Meta Data contains the size, version of FAT, etc.
FAT:
FAT is an array of block numbers
each entry of the FAT can have different values
0 : eof (End of File)
-1: free block
N : block number of next block in this file
Whenever we gets the first block of the file, we can keep getting the next block number until we reached the end of file
When trying to find a new empty block for new contents, we simply search the FAT to find an entry with value -1
Initially, data blocks are allocated sequentially (since all blocks are empty and sequential)
However, later on, when early blocks are removed, and we are trying to fit a new file (which is larger than the size of the block we freed), the file might be saved non-sequentially (depending on the implementation of the file system)
Directory:
In FAT, a directory is a file, but the content of this file is interpretated differently
The content of the directory file is array of directory entries
Each entry will points to a different file
Problems with FAT file system:
To have a first impresion of what the unix file system is, see the below diagram
| boot sector | superblock | inode table | <--------------------data--------------------> |
The boot sector and the superblock have similar usage as FAT file system. The big improvement of the unix
file system is its use of inode structure.
An index-node (inode) as a data structure to stores all the information about a regular file, directory or other file system object.
The following graph sketches its basic structure:
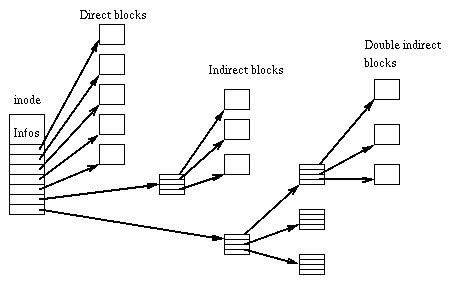
The infos area stores the file's attributes such as the size of the file, the type of the file and link count.
In a typical inode, except for file attributes there are:
Side problem: Assume disc blocks are 8K bytes and that disc addresses are 32 bits: - What is the largest possible file using above inode? As a disc block is 8 kB (8192 bytes), and disc addresses are 32 bits (4 bytes), each disc block can hold up to 2048 (8192 / 4) disc address entries. This means that the singly indirect block can reference up to 2048 * 8 kB bytes of file data (16 MB). Extending this, we find that a doubly indirect block can reference up to 2048 * 2048 * 8kB of file data (32 GB).
To conclude:
Up to 80 kB of file data can be accessed using the direct blocks. This translates into file offsets 0 through (80 kB - 1) inclusive.
Up to 16 MB of file data can be accessed using the singly indirect block stored in the inode. This translates into files offsets 80 kB through (16 MB + 80 kB - 1) inclusive.
Up to 32 GB of file data can be accessed using the doubly indirect block stored in the inode. This translates into file offsets (16 MB + 80 kB) through (32 GB + 16 MB + 80 kB - 1) inclusive.
We can even add a triply indirect pointer which extends the max file size to 64 TB.
The Berkeley filesystem adds a block bit map into the file system.
| boot sector | superblock | block bit map | inode table | <--------------------data--------------------> |
Block bit map contains an array of bits. Each bit indicates whether corresponding data block is free.
This can be used to realize the problem of contiguous allocation.
Now we have the idea of how files are stored in the Unix file system.
Each directory entry is represented as:
| 14bytes name | 2bytes inode number |
That is, a file is actually a name and an inode number!
For example, a dirctory can be represented as follows:
| "foo.txt" | 27 |
| "gah.txt" | 48 |
| "hello.txt" | 27 |