UCLA, Computer Science 111, Winter 2012
Lecture 13 - February 29th, 2012
By: Kevin Takeshita, Yoshi Osone, Megan Johnson, Suzanna Whiteside
Table of Contents
1 - Real time Unix file systems
1.1 - The Price of Indirection
2.1 - Creation of Special Files
3.1.1 - Problems with read-only file systems
5.1 - Save Problem Introduction
5.2 - Golden Rule of Atomicity
5.4 - The Lampson-Sturgis assumptions
7 - File System Correctness Invariants
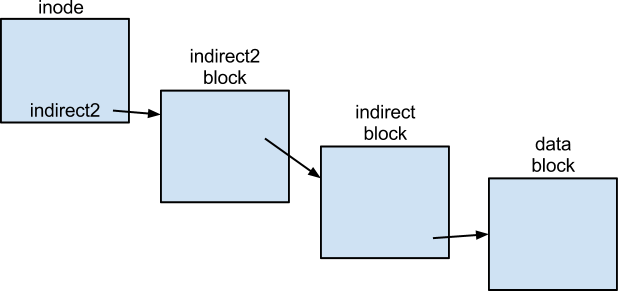
Our current file system has this issue with its later blocks:
In our code, when we call lseek(fd, ….)and then read(fd, ...)we think we are doing one seek when we could actually be doing three. In the worst case, we must first go to the indirect2 block, then the indirect block, then finally seek to the actual data block. The application could run three times slower. That’s the price of indirection!
Problem: This is unpredictable; we might have to do three lseek()s instead of one. In real time systems, we want our programs to be more predictable.
Solution: Use contiguous files. There is a special flag set in an inode that says that the file is contiguous.

Having one contiguous set of data blocks allows reads and writes to a file to always be sequential, allowing us the consistency we need for a real-time system. You only have to do one seek!
The flag to create a contiguous file is O_CONTIG, and you might call it as follows:
open(“file”, O_CREAT | O_RDWR | O_CONTIG, 0644,(off_t) 624*1024*1024);
The downside to this is that you must specify the size of the file when you create it.
/dev/null is a special file. When you read from it, you always get EOF. When you try to write to it, the data goes nowhere!
How do you make a file like this?
Bad boot script:
$ /dev/null
$ chmod 666 /dev/null
This would work if no one writes to the script and everyone just reads. However, writes the file are allowed. It would no longer behave as expected because the file would have non-null characters. We need a better way to make special files.
Instead, the correct way to create a special file is to invoke mknod. This creates a node rather than a regular file.
$ mknod(“/dev/null”, …, magic number)
Good boot script:
$mknod /dev/null c 3 19
$ls -l /dev/null
crw-rw-rw- /... /dev/null
The inode has a special signifier saying that is a character special file. Only root can run mknod (it is privileged). If this were not the case, any user could wreak havoc with their own nodes controlling devices.
It is possible to created named pipes.
$mkfifo /tmp/mypipe
$ls -l /tmp/mypipe
prw-rw-rw- /tmp/mypipe
$cat /tmp/mypipe >foo & #creates a reader to the pipe
$sed s/a/b/ /etc/passwd >/tmp/mypipe & #creates a writer to the pipe
In this example, the first process (cat) waits for a writer to write to the pipe. If we had created the writer process first, it would have likewise waited for a reader process to start reading.
The pipe in this example has an inode, simply because it has a name and exists in the file system. It is not really a file and has no data associated with it, but it has an inode.
A more general subject: We view the world through this directory structure even though what we’re looking at aren’t really files. We look at file names as a way of addressing objects in general. This is a powerful idea!
Suppose we have two different file systems. For example, the root file system (/) and the user file system (/usr), which is read only.
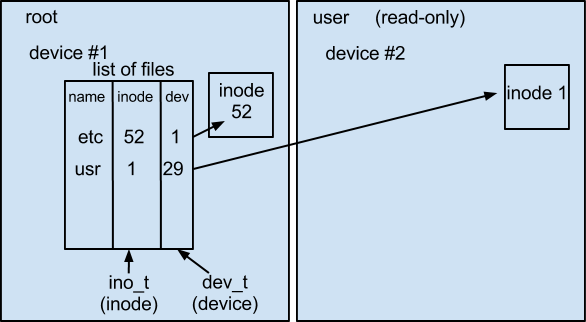
Example use:
$ ln /usr/bin/sh bin/sh
This command would create a file in root’s list of files, called sh, and link it to the executable file “sh” within user’s file system.
Inside the kernel, there is a mount table in main memory:
dev_t | ino_t | devt |
1 | 2090 | 29 |
This table tells whether the disk is currently mounted, and what backup disk to use if the disk is not mounted. The mount table is relatively small.
Unfortunately, these are competing goals. For example, if you want high performance, you could simply dally. While performance is great with dallying, you’ve lost atomicity and durability. This is because dallying tells the user that it has written when it has not yet, so the disk is not in the state you may expect at any given moment.
It’s very tempting to cheat. Why? For many applications, some of these goals don’t matter. If your iPhone battery dies, you’ll just have to re-do whatever action you last took. It can even be lucrative to cheat, because most users just do not care about tiny problems like this.
Some applications CAN’T cheat. Server applications that deal with people’s money or personal information HAVE to be robust.
Suppose we have a text editor that has a save operation. We have a file on disk that contains the old contents (10 blocks). A 10 block memory buffer contains the new contents of the file that we want to save to disk.
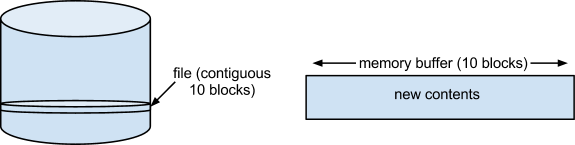
To save, we want to write the blocks out to disk. If block writes are atomic writes, this works. Note: We make the assumption that the changes are all in one block.
What if blocks aren’t atomic writes? We start writing out to disk over the old contents of the file, and then we crash. The file will now contain old and new contents. This is not desirable.
Another idea: Pick a different area of disk to write new contents out to! Then if you crash while writing, the file will contain only old contents and not a mix of both.
Never write over the last/only copy of data on a disk!
We can do this on a file system basis. When you reboot, you might not know which file contains the old contents and which file contains the new contents. Which is right?! We need to keep track by having a switch that records which one is which; we can have the switch on disk. Meta information will point to the correct version.
We assume that we have underlying support for atomic updates of meta information. We better know what these assumptions are!
This is how we assume block writes to look on a low level:
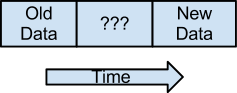
To begin, the old data is there. Then the write begins, during which time the data is not guaranteed to be correct until the write finishes, at which point the new data is there.
With this model of a block write in place, we can now figure out how to perform atomic block writes. One way that works is to use three copies of the same data:

If any of the block writes fails, we can recover the correct block data by following these two rules:
1. If two blocks have the same data, use that data
2. If all three blocks have different data (column 4 in the image), use copy 1 (the new data)
(This method is obviously an inefficient use of disk space, and isn’t really used)
1. Storage writes may fail, but a later read will detect the bad block
-Failed write to a block may corrupt another block
2. Storage blocks can spontaneously decay
3. Errors are rare
rename(“a”,”b”) - we want this to be atomic

This is easy - just overwrite the old directory entry block with the new one atomically
The first example works with atomic block writes, but consider something like: rename(“d/a”, “e/b”)
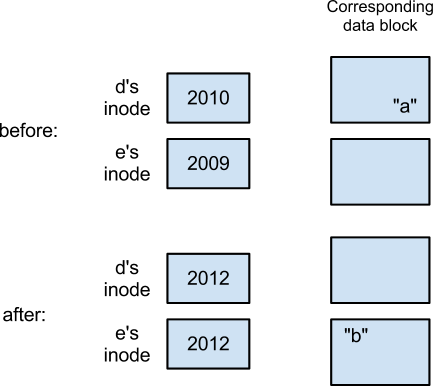
The link count is a problem in this example, because if a write error occurs after “b” is written to one of directory e’s data blocks but before d’s data block erases “a”, then there will be an inode link count of one even though there are two directory entries for the same file.
The proper operations to perform is:
1. increment link count
2. write destination directory data block
3. write source directory data block
4. decrement link count
A write error can still occur between steps 2 and 3, but this will be okay because the link count was incremented. If an error occurs between steps 1 and 2 or between steps 3 and 4, there will be a link count greater than the number of directory entries for the file, and the result is a simple data leak - not a big deal.
1. Every block is used for one purpose
2. All referenced blocks are initialized to data appropriate for its type
3. All referenced data blocks are marked as used in the bitmap
4. All unreferenced blocks are marked as free
Invariants 1, 2, and 3 are very important. If one of them does not hold, it will result in DISASTER. If invariant 4 does not hold, it can be easily fixed with a program such as fsck.