The purpose of a commit record is to effectively perform a single low level write that "matters". This simplifies all changes on disk, regardless of the number of
blocks that need to be written, into a single write that guarantees an all-or-nothing state on disk. One method in accomplishing this is, for example:
This shows that with each commit record we keep track of where we can find the most up-to-date, complete version of the data. This implies
a fundamental assumption for commit records: We must be able to create commit records that have the all-or-nothing atomicity property, otherwise
if we can have commit records in unstable states after crashes, then we have broken our problem down to a smaller one, but have failed to
truly fix the problem itself. This issue is usually solved through hardware methods.
The purpose of journaling is to record all changes done to disk in order, so that if there is a crash, you can walk through the changes made in the journal
and put the disk back into a stable state. This is implemented by dividing the disk into 2 sections: cells that hold data, and a tape (journal) that records
proposed changes to cell data (commit records). Because every planned change to the disk is recorded in the journal, the need for the actual changes to
be reflected on the disk is secondary. This means it is very important to change the journal immediately so that the write is recorded. The most important
benefit of journaling is that we can now safely perform optimizations such as batching and dallying without risking all-or-nothing atomicity. Other benefits include:
2 implementation methods for journaling are:
-Write-ahead logs, and
-Write-behind logs
| Implementation | Benefits/Tradeoffs | |
Write-ahead Logs |
|
|
Write-behind Logs |
|
|
A more complicated approach to journaling is to allow processes to look at pending writes. This allows for better performance and parallelism for applications,
but results in complications when a pending write that an application has read to is aborted instead of committed. All processes that read from the pending data
must be notified that the data they read from was aborted (ex. a signal).
The problem that virtual memory is trying to solve is when unreliable programs have bad memory references. If such programs are run on a bare machine
(one without compensating mechanisms such as virtual memory to resolve this issue) the while system will fail.
Solutions other than Virtualizing memory:
if all programs run on the machine are written perfectly, bad memory references will never be an issue
This works but involves a software solution that implies a fairly heavy run-time cost
This is a hardware solution, so it will be much faster. The hardware
checks that all memory references are within the range
of a process' bounds and if not will trap to kernel. This has many issues
such as fragmentation if a process asks for more RAM,
and makes communication between processes extremely difficult, if not
impossible, since that requires multiple processes having overlapping
bounds.
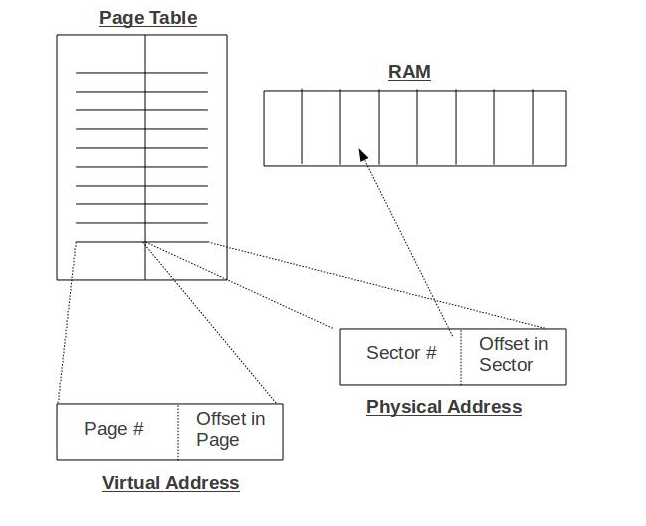
Virtual Addresses split up ram into segments called pages, which are the same size as a block in physical RAM (usually 4 KiB). Although pages and blocks are
the same size, a block in physical RAM can contain any arbitrary page associated with it. This allows for processes to believe they are dealing with contiguous
pages of memory while the memory manager can move around and allocate blocks as it desires. A virtual address consists of a pair of numbers describing the page # and the offset
within the page that contains the requested byte. This is translated by the virtual memory manager with the page table to the corresponding block number where the page is held.