CS 111 Lecture 15 Scribe Notes - March 7, Winter 2012
Scribe notes prepared by Alice Lin
Table of Contents
- Policies
- Improving Performance
- Distributed Systems and RPCs
A bit of code to run when page faulting:
- The pmap function from last time maps virtual addresses to real addresses.
- Each process should get it's own page table, so that isolation is achieved.
->Why doesn't each thread get it's own page table, rather than each process? Threads base their functionality on sharing memory.
We have two functions already provided to us:
- p->pmap(va) - returns the RAM address. Each process has its own pmap function.
- p->swapmap(va) - returns the disk address. The code looks something like:
{return p->disk_origin + va;}
The Mechanism:
pfault(va, p, ...){
if(p->swapmap(va) == FAULT) //bad pointer/address
kill(p);
else{
(op, ova) = removal_policy(...); //magic that picks another function/virtual address. Discussed in the "Policies" section.
pa = op->pmap(ova); //physical address of victim
//We can't actually write the following, this is just a high level description of what's happening.
//write pa block to disk @ other process' swap map [op->swapmap(ova)]
//op->pmap(ova) = FAULT;
//read pa block from disk at p->swapmap(va);
//p->pmap(va) = pa;
}
};
Policies
Question: Which page should we choose as a victim when page faulting?
We'll use a specific requested page sequence - 012301401234 - and see how it compares with the different policies shown. Red numbers in a column indicate a page fault. Our goal is to choose a policy that lowers the number of page faults.
Answer 0: Pick a page at random. This works if memory accesses truly are random, but it rarely is (locality of reference!).
The number of page faults is impossible to determine.
Answer 1: FIFO (First In First Out)
This straightforward method chooses the page that's been in RAM the longest as the victim. It replaces the pages in the order that they come in.
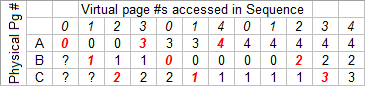
9 Page Faults
Answer 2: Oracle Policy
We use a subroutine to "look into the future" for the page that won't be needed for the longest time, and chooses that as the victim.
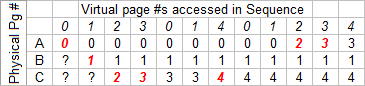
7 Page Faults
Answer 3: LRU (Least Recently Used) - this one works the "nicest" in practice, though in this example it actually performs the worst.
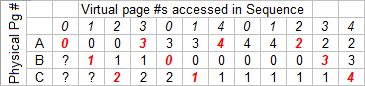
10 Page Faults
Why don't we pretend we have infinite money, and just throw more hardware into the problem?
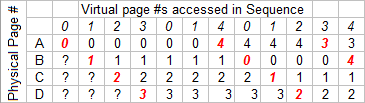
10 Page Faults
....Adding a process (more RAM) doesn't always mean better running! This is called Belady's Anomaly. It doesn't happen all too often, though.
Ways to Improve Performance
Since creating a better policy can be difficult to implement, let's think of other ways we can improve performance.
A. Demand Paging
Demand paging waits until a program requests a page to load it from memory. This is useful and commonly used for many mobile applications.
+ Startup faster (put up a splash screen) - if we don't see anything loading for 10 seconds before the entire program loads (ordinary paging), we don't want to use it.
- More page fault code is executed
- More disk-arm movement in a multiprocess application
B. The Dirty Bit
Have a bit representing if it's ever been written to. If it has not, we don't have to write the victim page to disk. A page is clean if the dirty bit is 0, and has been written to if the dirty bit is 1. This can be done by manipulating hardware, or by using kernel traps to mark the dirty bit on the corresponding page.
- More page fault code is executed
- More disk-arm movement in a multiprocess application
C. vfork()
fork() copies all of the process' virtual memory, which takes time and space. We can speed this up using vfork(). In vfork(), the parent and child share memory and page tables, so no extra memory is needed. Additionally, the parent is frozen until the child exits or executes.
Distributed Systems and RPCs
RPCs differ from ordinary function and system calls.
- Slower
+ Caller/callee have hard modularity because they're not sharing address space
- No call by reference - always call by value
+ Caller/callee may have different architecture, which requires the data format to be known.
The caller must marshal data, while the callee unmarshals data.