CS 111: Lecture 16 - Robustness, Parallelism, and NFS
Scribe Notes for Monday, March 12, 2012
By Rouel Soberano
Table of Contents
- Network File Systems
- Structure of ZFS System
- Performance of ZFS System
- NFS Performance
- Parallel Issues
- Other RPC Issues
- NFS Client
- Concurrency Control
- NFS Reliability/Robustness
- Media Faults
- Redundant Arrays of Independent Disks: RAID
A Network File System, or NFS for short, is a client/server-based file system. The basic idea
behind NFS is that files are stored on a server's marchine (as opposed to a client's local machine)
and clients access these files by interfacing with the server via the NFS protocol, which is a form
of RPC (Remote Procedure Call).
In order to motivate the use of NFS systems, consider the following example specs and performance figures
for the SUN ZFS Storage 7320 Appliance, an NFS to be released in May 2012, via spec.org:
Specifications:
- 2 storage controllers
- 2 10 GB ethernet adapters
- 8 512 GB SSD (read acceleration)
- 8 73 GB SSD (write acceleration)
- 136 300 GB 15k RPM hard drives
- Total: 37 TB total exported capacity split up into 32 file systems, each 1TB large
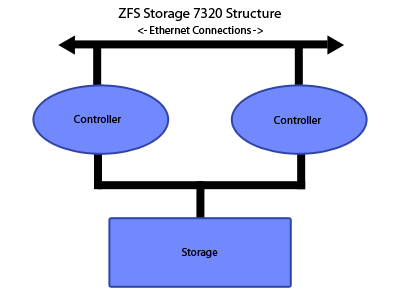
In examining both the specifications and the diagram above, you may wonder why there are two storage controllers, two ethernet adapters, etc. This multiplicity of components exists for redundancy and performance: by using two components to satisfy the same function, the system ensures no single point of failure. If one of the components goes bad, its counterpart will keep the system running until the faulty component can be replaced.
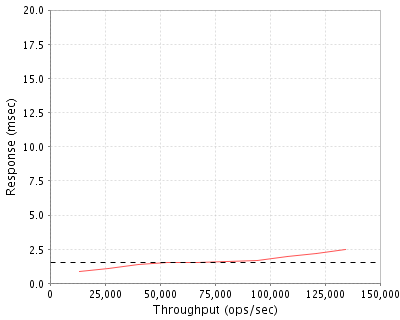
As you can see from this graph taken from the results of the benchmark test, the SUN ZFS Storage 7320 Appliance
operates at an average response time of roughly 2ms, reaching a max of around 2.5ms (assuming you limit
throughput to under 150,000 ops/sec; the response time tends to skyrocket past this operating limit).
Compare this result with the average read response time of a local disk, which is roughly 7-8ms at best, and you
have a system that is about 3 times faster than a local hard drive. For the complete results of the benchmark test,
check out the full figures on the spec.org website.
As mentioned above, NFS uses RPC to interface between the client and server. In general, in serialized RPC, the interaction between client and server is as follows:
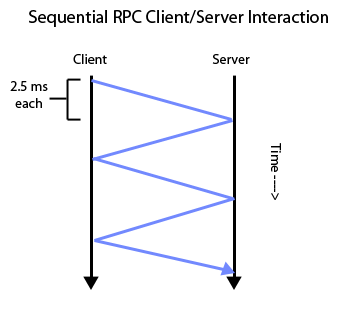
As each of these RPCs takes about 2.5ms, interactions between clients and servers can easily take long amounts of time as the amount of RPCs scales up. To give the issue a bit of perspective, this is the way web browsers (which also utilize RPC) used to work. Everytime a user would open a page, the web browser would issue a request to read an object (such as an image) on the page, then the server would respond with the contents of the object, and so and and so forth in this manner until all of the objects on the page were loaded. As websites increased in complexity and size, this process began to take much too long, leading to long response times from the web browser. This brings up the question: is there a faster way to do this?
The solution utlized by NFS it to parallelize these calls using a multi-threaded client. Under this implementation, operations that are normally done in sequence are run at once in parallel, leading to overlapped reads and writes. This idea works rather well with the use of independent threads. As a result, the interaction between client and server looks as follows:
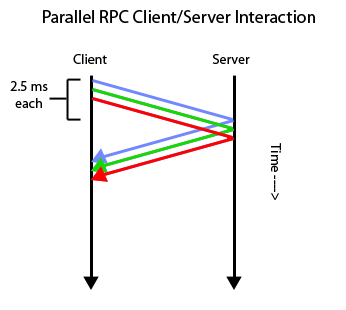
As you can see from the diagram, as all of the operations are done in parallel, the execution is much faster than when the operations are done in sequence. Going back to the web browser example above, modern web browsers nowadays use a derivation of this parallel concept, known as http pipelining to process RPC calls and load a web page. As such, when a page is loaded, all objects on a page are downloaded at once in parallel, leading to a much faster response time than before.
As you would imagine, this approach isn't without its problems. In this case, the issue has to do with failed operations/requests: because requests are performed out of order in parallel, how does the client and/or application know if a certain instruction fails? This issue is important because clients/applications should be able to handle failed read/write applications in a robust manner. In response, NFS answers this question with the following two solutions:
The first solution is to be slow, don't use pipelining, and wait for the actual response. This approach guarantees that failed requests will be notified and processed correctly by the client, but at the cost of serializing a parallelized process and thus increasing overall response time.
The second solution, which is used about 99% of the time, is to be fast, continue to use pipelining even if a request fails, and lie to the user about whether or not the write actually succeeds. While this avoids the performance setback, the issue still remains: when does is the client informed if the request failed? Under this solution, this occurs once the file being written to is "closed". After all the requests have been processed but before the file is closed via close(), the server reports all of the errors and then redoes all of the failed requests in sequence. Only after these failed requests are handled is the file then actually closed.
As a side note: whenevever you close a file, be sure to check the return value of the system call and handle errors accordingly to make your code more robust.
In addition to the performance boosts of parallelizing RPCs, there are a few other plusses as well. For example, RPC is characterized by hard modularity, which allows for the use of different address spaces. However, along with these bonuses there are quite a few setbacks to as well.
Delayed and/or lost messages: current network technologies are inherently lossy, leading to dropped packets and other similar issues.
Corrupted messages: bits can be flipped or missing, etc. This can be countered by using checksums at the end of each sent packet. If a packet fails a checksum (i.e. data is corrupted), ask the server to retransmit the packet. However, there is still a 1 in 64,000 packet error rate, which is a pretty significant figure to have to consider when transmitting packets.
Network and/or server may be down, or too slow: This can be a big problem because the client has no way to tell the difference between the network/server being down or being too slow. As such, there are three ways of dealing with this issue:
- At least once RPC: try sending request again and keep trying until response. Acceptable for idempotent operations (i.e. reads and writes).
- At most once RPC: either the original request executes or it doesn't execute at all. Preferred for non-idempotent/dangerous ops (i.e. renames, transfering money, submitting order requests) which should not be done more than once.
- Exactly once RPC: every call is executed exactly once. While ideal, this is usually difficult and expensive to implement.
In general, the NFS Client is implemented as follows:
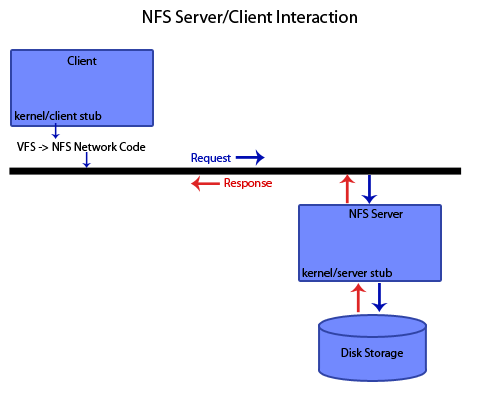
As you can see above, NFS calls interfacing between the client and the server are implemented within the kernel. Within the kernel, the Virtual File System implements a sort of generic file system with the usual read(), write(), etc. system calls. Underneath this generic file system, the VFS implements support for multiple filesystems, such as the usual ext4 filesystem as well as the NFS. In this way, VFS represents a sort of object-oriented design in that each filesystem implementation underneath the VFS exhibit a form of polymorphism. The VFS contains a struct that specifies function pointers for each file-system implementation, and so any read(), write(), etc. calls passed to the VFS in the kernel are then passed along to the appropriate file system, which then executes its own version of read(), write(), etc.
From this point, communication between client and server is handled by the NFS Protocol, which takes the form of RFC version 2, 3, or 4. The following calls are present in the NFS protocol:
- READ(fh, data)
- WRITE(fh, data)
- LOOKUP(fh, name): returns file handle and attributes
- REMOVE(fh, name)
- CREATE(fh, name, attr): returns file handle for new creation
The parameter "fh" mentioned above represents a file handle, which is basically an integer shared between the client and server that is used to uniquely represent files. These are deciphered much like inodes in local filesystems, with the added feature that if an NFS server reboots mid-lookup, the server has the power to bypass the OS and use a special NFS kernel module that allows direct access to inode numbers.
The implementation of the NFS client brings up the following issue: if two NFS clients are accessing the same file, with one client writing to the file and the other client reading to the file, if both requests start at the same time, but the writing client finishes writing to the file before the server can respond to the reading client, then the read requests will return an outdated version of the file. As such, NFS does not guarantee write to read consistency.
However, the NFS client does guarantee close to open consistency. This means that if client 1 issues a close command for a certain file and client 2 issues an open command for the same file, client 2 will open the a correctly updated version of the file. This is due to the overhead induced when closing a file as mentioned above in the Parallel Issues section: when a file is closed, all pending writes are finished first before the file is finally closed (remember closes are "slow"). Thus, when client 2 opens the same file, it will have the correct updates to the file.
NFS systems are rather unique in that they assume a "stateless server". This means that server controller's RAM exists as a cache only and cannot contain any "important" information (i.e. no data is kept in RAM, all data is written to disk immediately). This way, if the NFS server crashes or reboots, no data can be lost in the RAM, and thus the client won't notice and operation continues as normal.
In addition to stateless servers, NFS has the usual behaviors for reliability/performance. If the system is interfacing over a bad network and loses packets, the system will retry the operation. If the system receives corrupted packets, the system will retransmit these corrupted packets. However, if the system comes across a bad client or a bad server (e.g. one that generates request randomly, etc.), NFS has no inherent way of responding to the issues. As such, this must be directly handled by the operator. Last, but definitely not least, when it comes to bad disks, or media faults, the system has a pretty unique way of dealing with this issue, which will be described in the next section.
As mentioned above, the issue of media faults involves dealing with corrupted hard disks and/or bad hardware. If one of the storage disks in an NFS fails, is corrupted, or crashes, how does the system respond?
One possible way to address this issue is to use logging, which was covered in an earlier lecture. Whenever any part of the file system is changed, log the change in a write log/journal and then perform the change. This way, if the system crashes, the system can easily see which changes were being made at the time of the crash and then either complete the change or restore the system. However, this approach only really works in the case of maintaining transcations across power failures and doesn't really address the issues of faulty/corrupted hardware.
As such, in order to deal with these media fault issues, the technique known as RAID was adapted to address faulty/corrupted hardware. As a bit of a sidenote, the technique was originally used as a way of creating cheaper storage solutions; instead of buying one large hard disk, buy a series of smaller (and much cheaper) hard disks and interface them together to create a cheap array of small disks equivalent to the larger disk in storage size without the expensive costs. As you can probably see, the redundancy that can be achieved by interfacing smaller hard disks together to form a larger storage solution can prove useful when it comes to circumventing media faults, and out of this idea, the current concept of RAID was born.
RAID was pioneered by Patterson, Gibson, and Katz at UC Berkeley in 1987. Their original paper defined the following implementations of RAID:
RAID 0: Concatenation/Striping
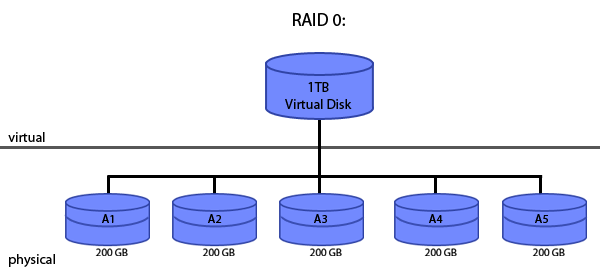
The basic idea of RAID 0 is the same as mentioned above. In order to create a large virtual disk, for example a 1TB disk, use five 200GB physical disks concatenated together. However, in addition to concatenating the disks, RAID 0 also implements striping, which means that contiguous data is split into the separate physical drives. That way, when this contiguous data needs to be read, the data can be read in parallel from the independent drives, thus increasing read performance.
RAID 1: Mirrorinng -> Reliability
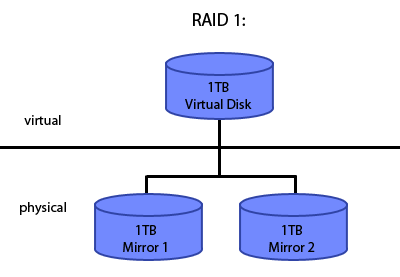
The basic idea of RAID 1 states that mirroring a disk using an array of independent disks creates a reliable system that will not fail when one of the mirrors goes down. Under this method, for example, a 1TB virtual disk is implemented using two 1TB physical disks that are essentially copies of each other. In addition to its inherent relability, this implementation also introduces some performance improvements, as reads from disk are slightly faster than usual. This is due to the fact that because you have two hard drives with the same data, you would ideally read from the hard disk whose disk arm is closer to the actual data, thus decreasing seek time and improving read time. Writes, because they are done on different disks in parallel, take the same amount of time.
RAID 4: Parity
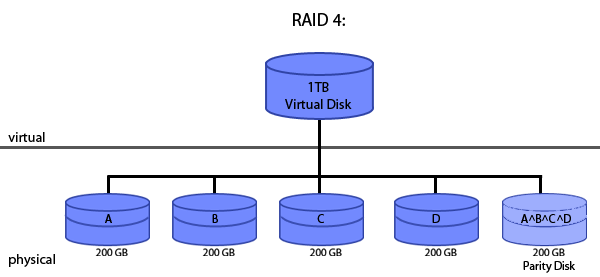
In this implementation of RAID, one of the physical disks is used as a parity (XOR) disk. This parity disk stores a holographic copy of the blocks in the other physical disks in the form of XOR'ed data, thus allowing for easy restoration should any of the disks go bad. Using the above example again, 4 of the 5 disks would be used to store the actual physical data (leading to a virtual disk size of 800GB). The fifth disk would serve as the parity disk, and as thus would store the data from disks A, B, C, and D holographically, i.e. A ^ B ^ C ^ D. That way, if any disk fails, you can compute the missing data by simply recomputing A ^ B ^ C ^ D.
There are a couple of catches with this approach. The first is that if any one drive is lost, extra care must be taken to ensure that that disk is replaced right away at the risk of losing all of the data in the drive should another disk fail on top of that. This requires a robust way of notifying disk failures to system administrators (DON'T IGNORE THAT BLINKING RED LIGHT!). The other issue is that because the XOR in the parity disk must be updated anything anything is changed, the disk becomes a hotspot for activity, leading to possible failure from overuse. RAID 5 addresses this by striping the XOR data across the 5 disks, but this approach makes it harder to add new disks as a result.