Performance specifications for network file systems can be found at spec.org, a handy site that publishes benchmarks for a variety of programs. To get an idea of what a Network File System has to do, we'll start by examining the specs for a Sun ZFS Storage 7320 Appliance.
-2 storage controllers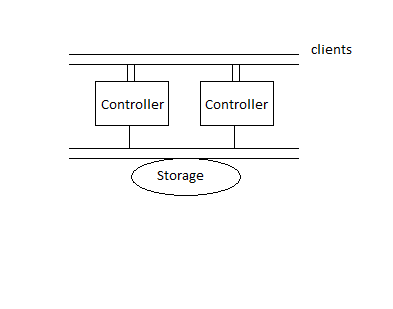
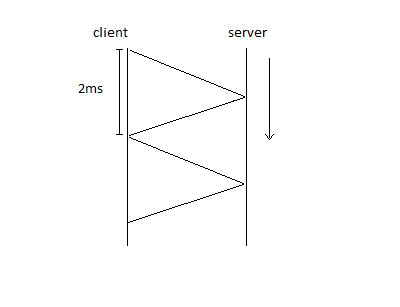
RPC is part of NFS and it stands for remote procedure call. It is a network programming model for point-to-point communication within or between software applications. The client sends a request and waits for the server response, before it sends the next request. This could take about 1-2 ms and is not good performance if there are many requests in sequence.
One solution to this is to work with a multithreaded/process client so they can issue multiple requests in parallel; this allows for a faster response time. This works well if the threads are independent, for example in a web browser.
Initial attempt of sending requests one at a time was too slow, so http pipelining was created. The client can send out multiple get requests and the server sends multiple files back. The client then handles any out of order or dropped packets.
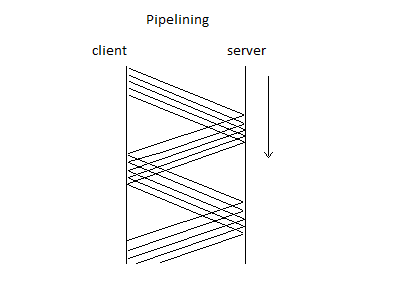
Suppose we attempt to write multiple buffers
w1 = write(fd, buf, 27)If this is implemented with pipelining, w1 or w2 can fail while w3 succeeds, or the requests arrive out of order. The file system must tell the program that a previous write has failed while being treated as a success.
Two solutions to this problem in NFC
1) Be slow: don't pipeline, and wait for each response.
2) be fast: pipeline, keep going and lie to the user about whether 'write' worked
Most people choose the second option because the first solution is too slow. Somehow the file system still has to alert the user about write failures later on. The convention is that errors are reported in the close operation. This makes the close operation slow, since it has to make sure all previous writes have succeeded. Close then returns a value showing whether or not there were errors while performing operations. This means programmers must now check the close return value to make sure everything was done correctly.
If(close(fd) != 0)
error();
Although RPC gives us the benefit of hard modularity, there are still some issues to deal with. Messages can be delayed, lost, or corrupted. These are all issues to deal with, but some solutions to corrupted messages can be solved with checksums. If a server then detects the bad packet, they send a request for retransmission.
If there is no response we try again, and keep trying at least once. This is okay for idempotent operations such as read and writes. However, it fails for operations such as rename(a, b) and should return an error to the caller (at most one RPC).
NFS Assumptions
How does the NFS operate at the programming level? And how can the NFS upgrade without breaking applications that depend on it? The design is to use an object oriented approach, giving the code the modularity it needs.
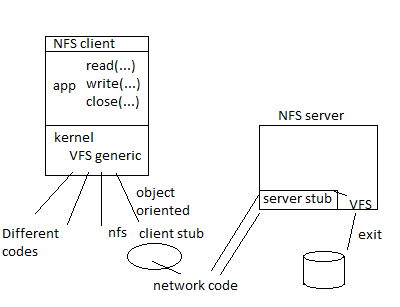
In the picture above, the application has its usual set of file operations, but the kernel below has a peculiar setup. It uses a generic file system where NFS code is loaded by passing pointers to NFS functions. The system calls invoked by read, write, and close by the app will eventually call these NFS virtual functions, which can then access the network. Additionally, an NFS can be mounted using the mount command, just like regular VFSs.
To access the files over the network, the NFS sends messages according to an NFS protocol, the messages look like these:
READ(fh, data)
fh is a file handle, which is just an int shared between the NFS client and server. Although, it is an integer that uniquely identifies the file on the server. But how should you create these file handles? Should they be created in inodes? Now suppose you're writing this as an application, the NFS has to bypass system calls and mess with the inodes directly. A part of the NFS has to run inside the kernel now and must run as root to modify these inodes, which is a big security hole.
There's another problem, suppose we have multiple clients. one doing a write and the other doing a read right after:
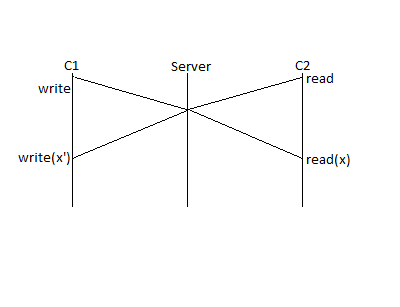
What happens in the user's point of view? The read finished after the write did, so we expect it to read the new value of x. But the read was handled before the write, so we read the old value of x, and wrote the new value after. We no longer have read/write consistency across multiple users, so NFS does not guarantee it. Instead, it guarantees close to open consistency. Users hoping to transfer files through an NFS must close the file on the sender before opening it on the receiver. The situation above does not occur with open and close due to significant overhead.
Can we address the bad disk problem via logging? (assume that cell data and the write journal are on the same journal)
No, because the write journal is on the same disk, the write journal can also be corrupted. Write journals are only for maintaining data across power failures, not against disk failures.
RAID was originally redundant arrays of inexpensive disks, which was then changed to redundant arrays of independent disks.
Started with inexpensive disks because big disks used to be much more expensive than smaller disks.
(5*1TB = $500, 1*5TB = $2000)
Many RAID versions were first developed by Berkeley students
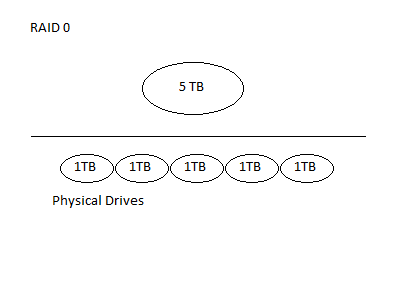
RAID0 consists of many physical disks concatenated to form a bigger disk. For example we take 5 1TB disks and concatenate them together to form one 5 TB virtual hard disk.
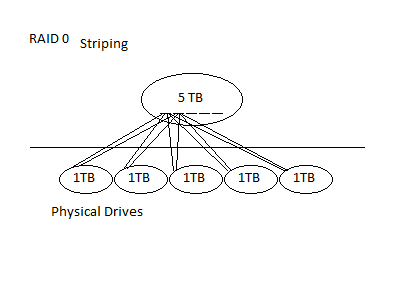
RAID0 can also be done via striping, where data is mapped non-contiguously, so reading contiguous data will involve many physical disks, allowing for parallelism. This can increases total throughput on large data transfers.
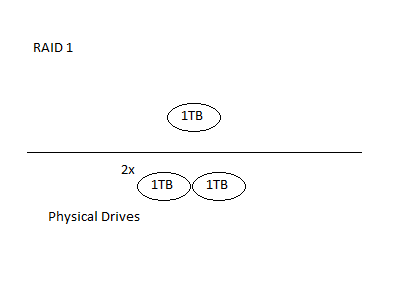
RAID1 creates a mirror, where the virtual drive is represented as two physical drives with the same data. This means that each write results in two physical writes. Each read can access either drive, such as reading from the arm closer to the data you want, or possibly splitting the read from both drives. Striping, concatenation, and mirroring can all be used in combination.
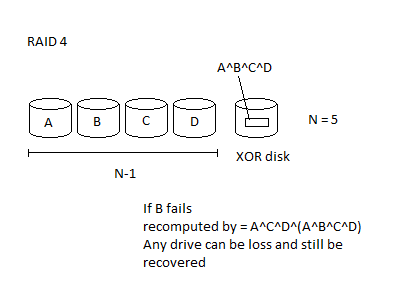
RAID4 is a good way to keep backups. With N drives, there are N-1 carrying actual data, while the last is a parity. If a drive fails you can recompute an entire drive using the other ones. In this case there are N-1 regular disks, and one XOR disk. The problem with this is that a robust way of notifying the operators is needed. One failing disk is recoverable, but two will result in all the data being lost. Naturally the busiest disk would be the parity disk.
RAID5 is just like RAID4 but with XOR's striped across all disks.