CS111 Lecture 16 Scribe Notes
By: Eric Wei
Network File System
NFS utilizes a Client service based architecture
Performance
- benchmarks obtainable through www.spec.org
- companies run older benchmarks like SPECsfs2008_nfs.v3 to obtain better results
- Example NFS - Sun ZFS storage 7320 Appliance (To be released May 2012) specs
- 2 storage controllers
- 2 10 Gb Ethernet Adapters
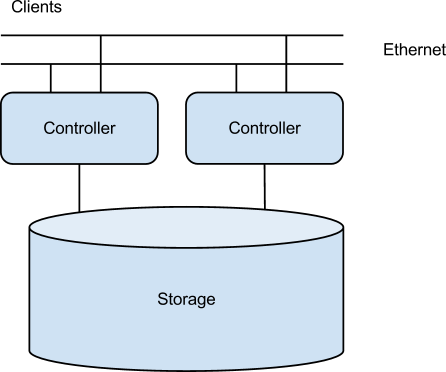
- 8 512 GB SSDs (for read acceleration)
- 8 73 GB SSDs (for write acceleration)
- 136 300 GB 15 kRPM harddrives
- Split into 32 filesystems

- The system has no single point of failure because of redundancy, multiple copies of the same components
RPC is part of NFS
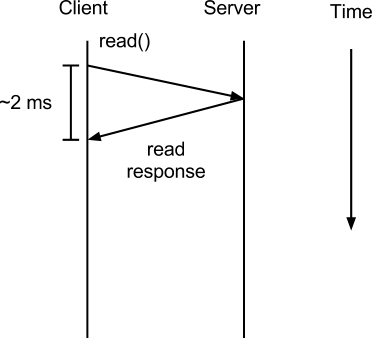
* 2 ms isn’t too bad, but we want to speed this up. How can we do this?
* Let’s do multiple reads at once

* If the threads are independent, this words well
* Web browsers basically use RPC
- originally, web browsers (client) issued requests to servers sequentially
- now, web browsers issue multiple requests in parallel through HTTP pipelining
- This brings up new issues. The client must deal with failed out-of-order requests
- Also, what if the client issues multiple writes and some of them fail? Here are 2 solutions:
1. be slow: don’t pipeline; wait for response
2. be fast: pipeline; keep going. Lie to the user about whether write() worked. Although, at some point, you need to fess up at report what really happened.
* Conventionally errors are reported on ‘close’
* ‘close’ now becomes slow because it needs to wait for all responses to come in, but files aren’t closed very often so this is usually acceptable.
* This is why you should always check the return value of close()!!! (since you only discover the truth then)
Issues with RPC
(+ = the good, - = the bad)
+ hard modularity (client and server have different address spaces)
- messages are delayed
- messages can be lost
- messages can be corrupted
- the network might be down, or slow
- the server might be down, or slow
How do you tell the difference between being down and being slow? (big issue)
* We can usually deal with corruption by using checksums (use them liberally)
If the server detects a bad packet, it should send a response “huh???” and ask for retransmit
* If no response, we have a few options:
- at-least once RPC - we try again and keep trying until it succeeds
- okay for idempotent operations (read/write)
- at-most once RPC - return an error to caller. Let the caller choose how to handle it.
- for “dangerous” operations (like changing the balance of a bank account)
- exactly-once RPC - do nothing
Robustness
* NFS assumes “stateless” server
- stateless - controller’s RAM doesn’t count as part of the state, so if the power cuts out, nothing vital is lost
- RAM is cache only
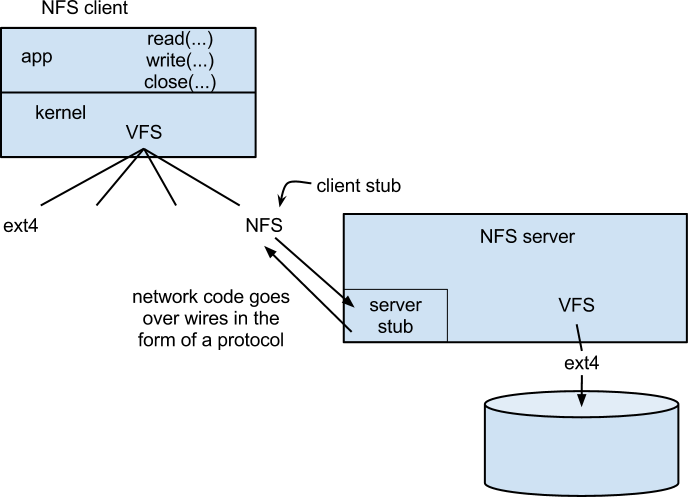
- This is essentially mounting
- NFS protocol goes over the wire
- READ(fh, data)
- WRITE(fh, data)
- LOOKUP(fh, name)
- REMOVE(fh, name)
- CREATE(fh, name, attr)
- fh = file handle
- What is a file handle?
- an integer (actually a little more than than) uniquely identifying a file
- these are like inodes in the actual file system
- To have the file system be fast, we need a module in the kernel that allows the file system to fiddle with files directly through via inode numbers
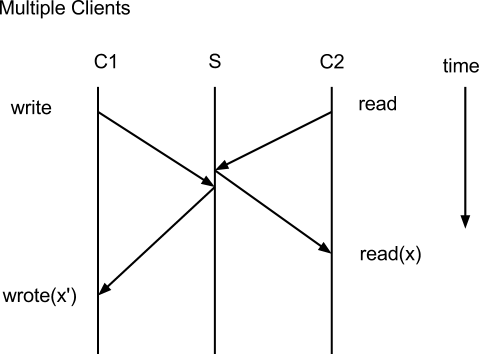
- NFS does not guarantee write-to-read consistancy
- It does guarantee close-to-open consistency (because close is much slower)
Reliability
Main issues
- bad network
- bad client (operator powers off machine)
- bad server
- bad disk (Media Faults)
Let’s focus of Media Faults
- can we address this issue via logging?
- no, because the journal used for logging could be corrupted
- RAID( Redundant Arrays Inexpensive Independent Disks)
- the original purpose of RAID was to get a bunch of cheap, smaller disks to act like a larger disk because disk makers were overpricing larger disks (i.e. A 1 MB disk would be $100 but a 5 MB disk would be $2000)
- nowadays, key feature from RAID stems from the R (Redundant)
- The various flavors of RAID
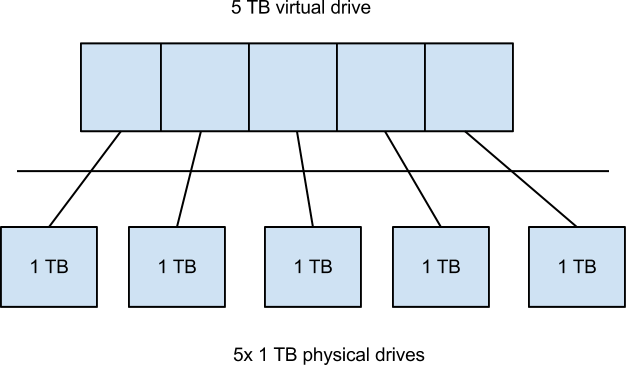
- RAID 0 - concatenation
- make a larger virtual disk by stringing together a bunch of smaller disks
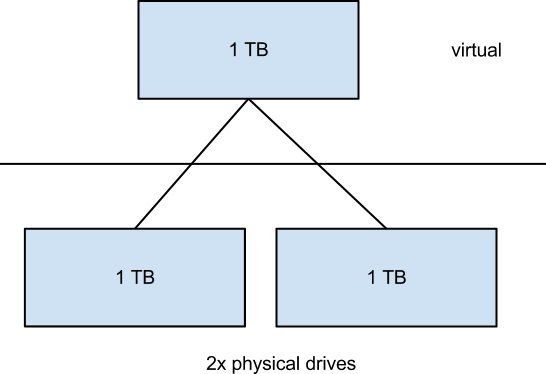
- RAID 1 - mirror
- multiple physical drives for a single virtual one
- reads are faster
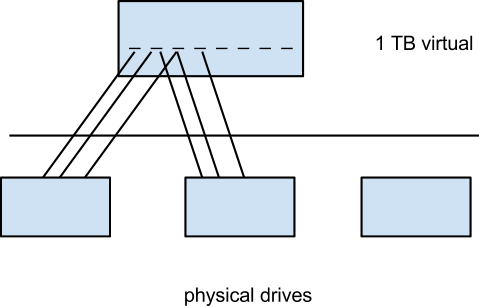
- Striping - a combination of RAID 0 and RAID 1
- overlapping regions of virtual memory across the physical disks
- There are more types of RAID, but we’re going to focus on RAID 4

- XOR disk is a bit parity of the other disks which allows data on another disk to be recovered if it fails
- example: if disk B dies, to resort the bits on B, we use the following equation
- B = A ^ C ^ D ^ (A ^ B ^ C ^ D)
- you can lose any single disk and still run, but if you lose 2 disks, you won’t be able to recover their data anymore so MAKE SURE THE SERVER GUYS GET NOTIFIED IF A DISK FAILS
- Of all the drives, the XOR drive is the busiest
- every write to any of the other disks = a write to the XOR drive as well