Last time in lecture we began to discuss distributed file systems and how they are implemented. A file system which is distributed over a network is called a Network File System (or NFS for short). Today's lecture will start with a discussion of performance in such systems, and continue to cover topics on robustness as well.
To start the discussion on performance, we will first look at an example system. Our example machine will be the Sun ZFS Storage 7320 Appliance, Sun's new system being released in May 2012.
All of the following benchmarks were found on www.spec.org under SPECsfs2008_nfs.v3
The system will have the following components: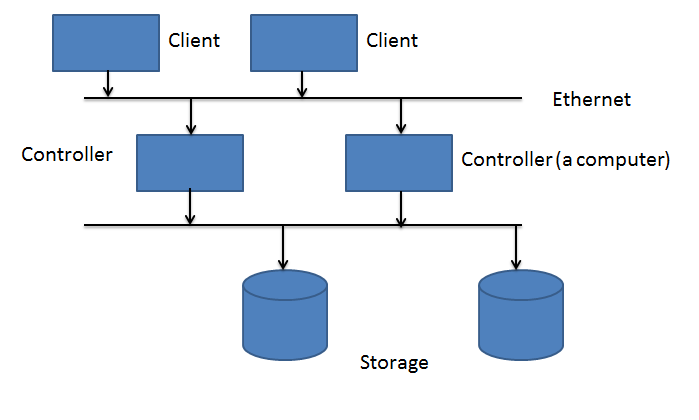
Note that the system has two Controllers. Controllers are the devices responsible for receiving messages over the network and actually accessing the storage and responding. Why does this system have two? Mainly for redundancy, if one were to stop working, then another one would still allow the system to function. This type of redundancy is found in many parts of this machine (the two adapters, two ethernet cables, extra drives etc.).
Typically machines such as these are benchmarked in terms of the response time (measured in milliseconds) vs. the number of operations being run each second. As can be seen in the graph, this system averaged around 2ms response time while running 100,000 operations every second.
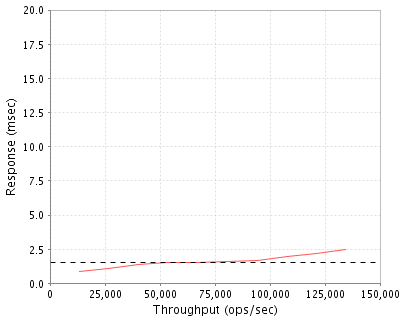
This means that if an end client attached to the NFS system requested to read a file, under a load of 100,000 requested operations every second the system would respond in 2ms.
For comparison, typical read/write operations on a normal machine to a random spot in memory takes about 8ms, so this machine is able to communicate over a network and perform read/write operations in a distributed manner about 4 times faster than a machine in which the hard drive is present.
Why is it so much faster? Largely because of the SSDs, which are much faster than traditional hard disks. In short, this means that the read/write times on SSDs plus the time it takes to communicate over an ethernet network is much less than the amount of time it takes to internally move the disk arm in a traditional hard disk.
Recall from last lecture that NFS and other distributed systems are typically implemented using Remote Procedure Calls (or RPCs).
Communication is normally accomplished through messages, which are sent between client and server. As Previously discussed in the example system above, if we assume that each response takes approximately 2ms, then we can model a simple read request as follows:
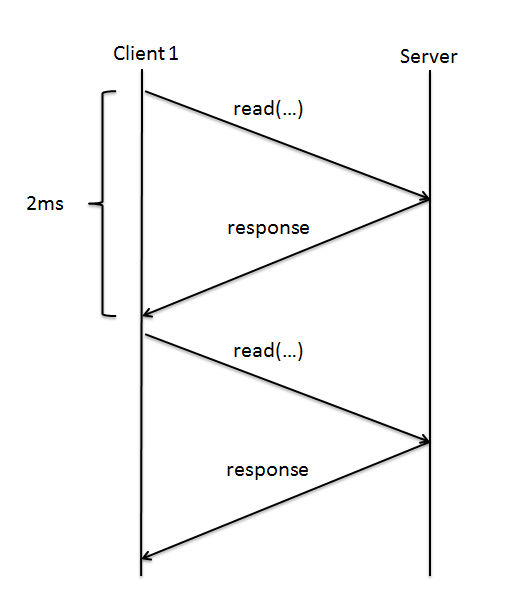
While 2ms is fast enough when issuing a single request, typically multiple read/write requests will be issued at one time and this overhead of 2ms becomes too slow too quickly. For example, issuing 10 read requests would take 20ms! The solution to this is to modify our RPC interactions to allow multiple RPCs to be sent at once.
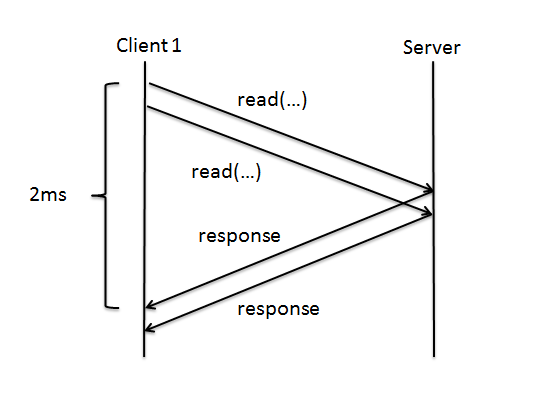
This greatly improves our performance, however only if our requests are independent, that is, if they can be done in any order and the results of one request aren't necessary to issue the next.
An example of this behavior with RPCs is in Web Browsers. Web pages are typically loaded using a number of GET.. calls to the hosting server requesting the page and the elements contained on it. It used to be that web browsers would issue these RPC like messages one at a time, waiting for the response each time before proceeding. This meant that loads were very slow, because if a page had 10 pictures on it (each of which needs to be downloaded from the server separately) then 10 sequential RPCs would have to be issued to the server one at a time, and the browser would wait for the result of each before issuing the next.
Now each element on the page which needs to be downloaded is requested at once, because each image is independent and downloading one has no effect on the other. As a result, the overall time it takes to load a web page is much much less.
So far this seems too good too be true, so what problems can we get into using parallel RPCs? Take for example the scenario when we have 3 writes we want to issue somewhere in our application.
write(...)Because we were using a policy of "charging on ahead" and issuing multiple RPCs at once, our program has continued its execution but until we receive the response from the server we won't know whether or not the write has succeeeded. So when we receive a failure once we're already far past that point in the code how do we handle it?
There are 2 Solutions to this problem.
As expected, most developers choose the second option. However there is one additional problem with the second solution that wasn't mentioned above. Many programmers don't check the return value when closing out a file descriptor. Because the second method communicates errors when closing the file, if the return value goes unchecked then the program won't ever know that a write failed. As a result, programmers must use syntax like the following:
if(close(fd) != 0) error();** These last two are a big problem because to our client the server being down and the server being slow look identical! Either way it receives no response.
Additionally, an issue of using RPCs and NFS systems as a whole is that you lose read-write consistency!
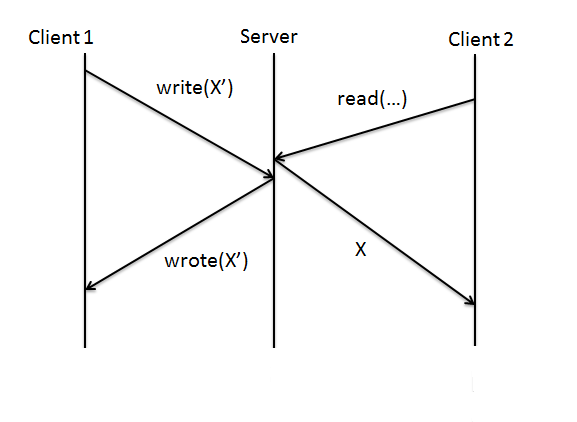
In the above example, even though the write request was issued before the read request, read will return the old value instead of the new one, so we can't be sure that read will always give us the latest version of the file.
NFS does provide, however, close-to-open consistency, meaning two different clients still can't open the same file at the same time. It accomplishes this by doing additional checks which result in a larger overhead, which is acceptable for open/close which only are called occasionally but not for read/write which are frequently called.
Corruption -> use checksums.
Attach a checksum to the end of each message, upon receiving one the client/server calculates the checksum of the message and ensures that it matches the one appended to the RPC. If it doesn't then send a message reporting an error and request a retransmit.
No response from server/client -> 2 Methods
So why don't we use sequence numbers like we do for TCP (transfer control protocol, the protocol used for many network transmissions)?
NFS always assumes a stateless server. Therefore each operation is received in complete isolation, so sequence numbers would be useless because the server can't be assumed to remember which sequence number it got last/expects next.
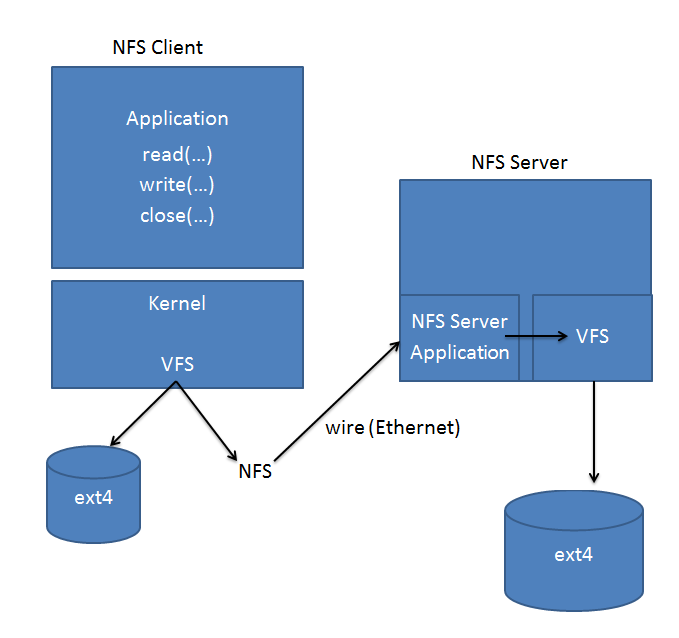
In the typical NFS Client the application sits on top of the kernel. It issues typical requests such as read, write etc. to the kernel. The kernel (which may have more than one filesystem mounted, in the above example it has two) sends it to over the ethernet wire to the NFS Server Application. The server then issues the approrpiate request to its kernel, which then uses its own native file system to handle the call. Remember that in NFS the actual NFS server has its own filesystem on the local machine (above it is an ext4 filesystem).
Below is the protocol used when implementing an NFS system. Most of the commands are self-explanatory.
READ(fh, data)
WRITE(fh, data)
LOOKUP(dir_fh, name) -> returns the fh for the file and its attributes
REMOVE(fh, name)
CREATE(fh, name, attr)
...
What exactly is a file handle though? Usually it is an integer, kind of like an inode number, which uniquely identifies a file.
It is important to remember that the NFS file server behaves just like an application running on top of the kernel (as opposed to inside of it, such as is the case with other file systems such as ext4), therefore it doesn't naturally have the ability to directly interface with inodes (although many have a kernel module which allows their application to directly modify and access inodes).
How do NFS systems respond to the following occurences?
bad network -> retryWhen discussing reliability in other file systems we used a Journal to protect ourselves against data loss, however Journals are just as vulnerable to media faults as the data which they log, and if you can't always trust the Journal then it's useless.
So how do we solve the problem of media faults? The answer is RAID.
RAID, or Redundant Arrays Independent Disks, was a methodology published in a paper by Berkeley a number of years ago. Interestingly enough, it wasn't originally intended to address the issue of ensuring reliability of disks against media faults. Instead it was created to solve the problem of hard drive costs. It used to be that a single, large hard drive was many times more expensive then a number of smaller hard drives, the sum of whose capacity equaled the larger one.
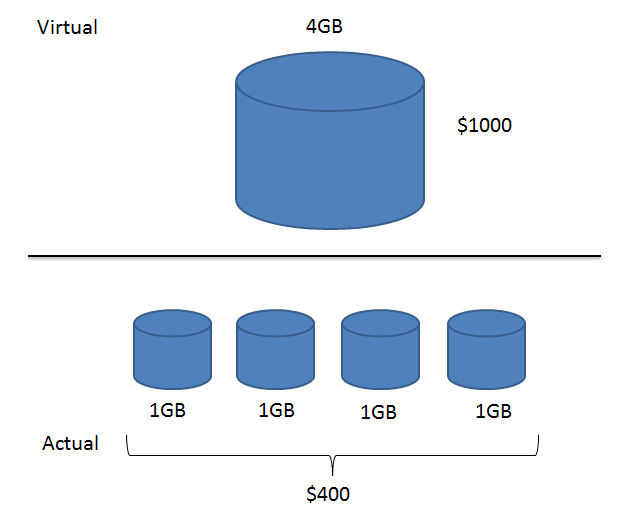
RAID solved this problem by proposing ways in which multiple, smaller disk drives could be used to simulate a single larger disk drive, allowing programmers to save money (hence its original name, Redundant Arrays Inexpensive Disks). It consisted of originally 5 different setups, numbered 0-5 (there have been many more published since).
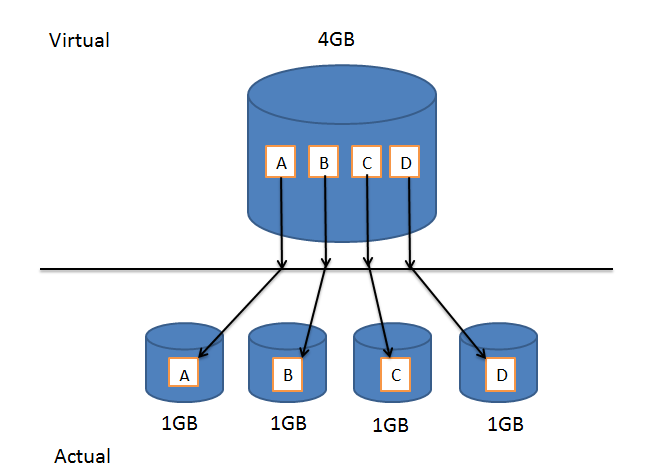
The idea behind RAID 0 was essentially the one described above. A number of smaller drives would be used to simulate a larger drive. If, for example, we had 4 1GB drives simulating a single 4GB drive, then the first drive would store the first 1GB of data, the second would store the second 1GB of data etc.
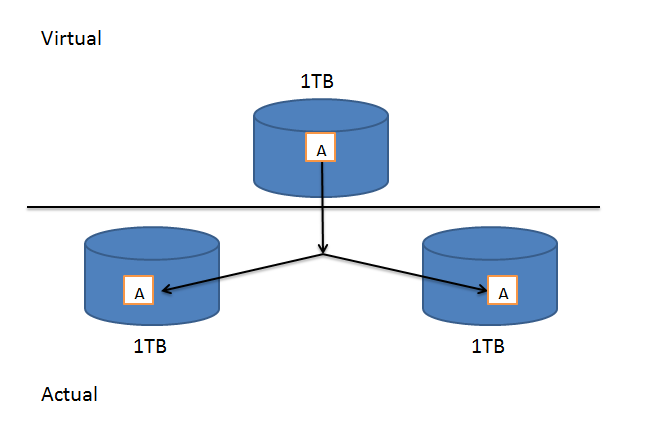
In RAID 1, two drives are used to reliably simulate a single drive. Each drive is the same size and all of the data that is allegedly written to the single drive is actually written in parallel to both of the actual drives. Therefore if one of the drives goes bad, the other one has a copy of the exact same data and nothing is lost.
Striping, although not actually one of the RAID propositions itself, is an alternative implementation which can be used in both RAID 0 and 1. To take RAID 0 as an example, we previously described it as concatenation, where each drive stores the first x amount of data. With striping, however, data is spread out over all the disks.
For example, if we break up the total data stored by the virtual drive into a number of segments, drive 1 may have the first segment, 2 the second, 3 the third, 4 the fourth, then 1 may have the fifth, etc. The result is faster read times because assuming the user wants to read a chunk of data spread out over disks 1, 2 and 3. Instead of having to wait for it all to be downloaded from disk 1, each part of the data can instead be read simultaneously from disk 1, 2 and 3, resulting in a faster result.
Striping can be used both when implementing RAID 0 and 1, and usually some combination of the three is used for optimal performance.
It is worth noting, however, that striping won't always provide a significant speedup, as it performs best when memory accesses are sequential and this isn't always the case.
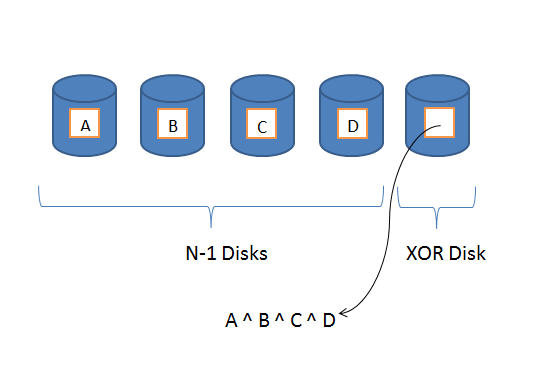
Skipping RAID 2-3, RAID 4 is the method that is particularly useful for us when implementing reliability in NFS systems. The idea of RAID 4 is as follows, assuming N disks are being used to simulate a single larger disk, then the first N-1 disks are used for normal storage. The last, however, is called an XOR disk (after the binary XOR operation). If the first N-1 disks contain, at the exact same location on disk, files A, B, C and D, then the XOR disk will, at that location, contain the value of A ^ B ^ C ^ D.
This is useful because if, for example, disk 1 (containing the file A) goes bad and all its data is lost. If we want to recover file A, all we have to do is take A = B ^ C ^ D ^ (XOR value or A ^ B ^ C ^ D). The result will be the file A! Essentially the XOR disk acts as our backup, simultaneously backing up all the data on each of the disks without actually having N-1 times as much storage.
There is one problem with this approach however. Assuming only a single disk fails, then it is never a problem, if it is one of the N-1 disks then the value is recovered as mentioned above, if it is the XOR disk itself then the XOR values are just recalculated. If more than one disk is lost though, then all of the data on each lost disk will be forever lost. As a result it is very important that a disk is replaced and restored as soon as it goes bad, because as long as it is not working the entire system is insecure.
While the approach initially described is the simplest, other variations on the same idea are also used. Especially because the XOR disk tends to become a "hot spot" (every write to any disk also requires a write to the XOR disk) many implementations take a striping approach to this as well, where the actual XOR data is distributed among the various disks so no single disk is under such heavy use.