Prepared by Arash Sepasi Ahoei for a lecture given by Professor Paul Eggert on March 12, 2012.
You can check the performance of your NFS on spec.org; the current standard is the SPECsfs2008_nfs.v3 benchmark – even though version 4 is out, it gives lower grades, and so version 3 has remained the more popular choice.
* The reason for multiple controllers and adapters is that the redundancy ensures that there is no single point of failure on the device.
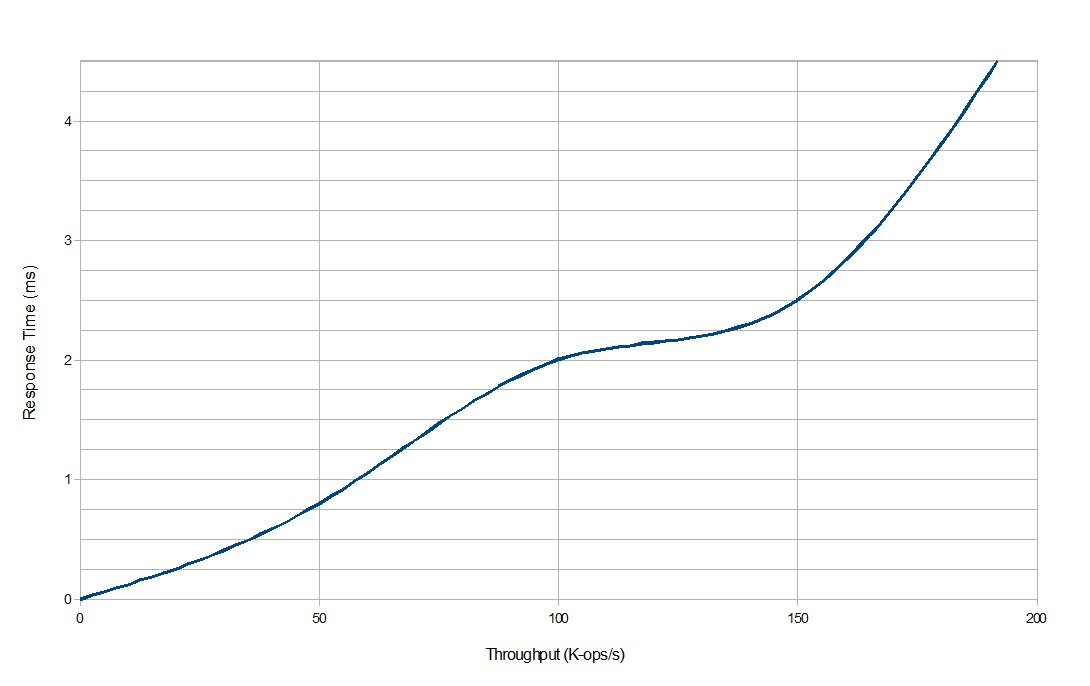
Performance is measured by the average response time of the system when it is put through varying amounts of operations per second—response_time = ƒ(K-ops/sec). Normal hard drives have around an 8 ms response time, but this particular NFS has a response time of about 2 ms due to the SSDs.
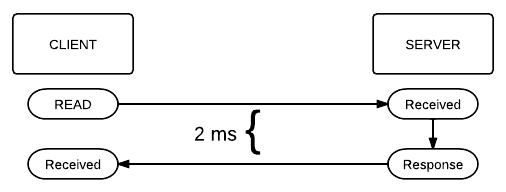
The system is made up of a client and a server, which talk to each other via RPC. So for example, if the client wants to read something on the NFS, the client's Kernel will form and send the read as an RPC request to the server, and then the server responds to the request and acts accordingly by sending the data back to the client.But if each read takes 2 ms, it will take way too long to process large amounts of the requests. One way to improve upon this is to parallelize the process, and handle multiple requests at the same time. This works well, however some problems arise when the requests being sent by the client are not independant of each other.
Web browsers used to work via RPC, where the browser (client) would sent an RPC read request to the website (server), and the website would in turn feed the browser the data it needed to be displayed on the screen. However this process took too long, and so browsers now use HTTP pipelining, which is basically a parallelization of that process. However some problems may occur because of this; for example, what if one of your earlier requests fail, while a later one succeeds? The client must deal with a failed out of order request response (imagine if 3 write requests are sent, and a bit later when the responses come back from the server, you realize the 2nd write request failed, which in turn would make your successful 3rd write invalid). There are two ways to deal with this:
Looking more closely at the 2nd
solution, we should keep in mind to still let the client know if any
of the writes failed (since we initially lie to the client and claim
all writes succeeded). This reporting can be done during "close"
time, which makes that process take way longer, since it now has to
check to make sure all the writes were done correctly; this is not
that big a deal since most applications simply read and write, and
don't really 'close' that often. This is also a good reason to always
call the close(fd) command inside an "if" statement, so if
it fails you can send an error to the user.
+ Hard Modularity: The caller and the callee are on different address spaces, so they can't mess with each other.
- Delays: Since you have to send each command through the network, there is some delay with getting your message to the destination (speed of light problem).
- Lost Data: Messages may be lost during this communication over the network. Almost every networking technology is at the core capable of losing data!
- Corrupted Data: Messages may be corrupted during the network communication. The underlying technology may cause bits to flip while they're going through the wires! There are16-bit checksums at the end of each message to try to catch this if it happens.
- Network Performance*: The network may be down, or very slow.
- Server Performance*: The server may be offline, or very slow.
* From the client's point of view, these two events are indifferentiable!
So now, how do we, as the client, remedy these issues? First of all, we can use checksums to make sure all the data packets we are receiving from the server are uncorrupted. If we catch a bad packet, we should ask the server to resend that data. The server should also use this system, and ask the client for any bad data packets it receives to be resent. However if no response comes back, we have a few options:
“At Least Once” RPC, i.e. “Try Again!”: Keep trying until you finally get a response. This is OK for idempotent operations, such as read and non-appending writes.
“At Most Once” RPC: Return an error to the caller ("Callee timed out!"). Preferred for more dangerous operations, such as renaming a file, or transferring money.
“Exactly Once” RPC: This is the user's preferred behavior for the client, where a single request is sent through and executed perfectly. We aim to provide this experience to the user.
We can also use TCP by issuing an ID number to each request, and
then having the server check that ID to see if a request was missed,
corrupted, or otherwise skipped for some reason.
NFS assumes a stateless server, which means that the client doesn't care about what is in the controllers' RAM. Therefore the client doesn't care if the server reboots, because even though the server's RAM will be emptied during a reboot, none of that lost data should have mattered. This is why the server doesn't keep track of any "sequencing numbers", such as a client's offset into a specific file, and this responsibility is instead the client's. So then, how do we get this to work? We will need to handle the details in the client, with a generalized interface to the filesystem: Virtual File System, "VFS". So then we interact with the VFS, which translates our requests to the NFS format and sends them to the server, where they are extracted by the server, fed to its VFS, and ultimately executed.:
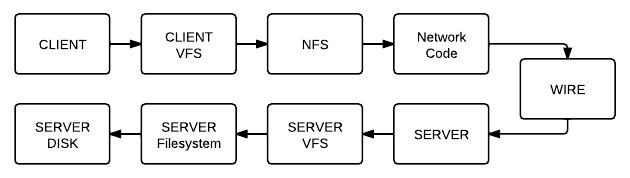
In Linux, the mapping of a VFS to a server is made easy with the following command:
# mount -t nfs server_dir /u/class
Now the server has an API with which to communicate to our file
system, and this API is how you design a file system; the API differs
from a protocol, which is what we will look at next.
|
Function ( parameters ) |
Return Value(s), if any |
|
READ ( file_handle, data ) |
Data Content |
|
WRITE ( file_handle, data ) |
|
|
LOOKUP ( file_handle, name ) |
file_handle, attributes |
|
REMOVE ( file_handle,
name ) |
|
|
CREATE ( file_handle,
name, attributes ) |
file_handle |
So now, what is a file handle? It is an integer, unique to a file,
which is shared between the client and the server, and is used to
identify that file. Next, let's explore this concept in more detail.
Stateless servers handle files via their file handles, and so file
handles may be thought of as inodes of a regular file system. But if
someone wants to write to a file handle right after the server
reboots (RAM is empty), how can the server know which file is being
referred to without having the relationship mapped in its RAM? The
solution would be to create some map between the file handles and the
files they refer to, but that would take too long! So the controller
cheats, by ignoring the filesystem system calls, and instead working
with the inodes directly. These operations need to be carried out in
the Kernel in order to have direct access to inode numbers, which
results in parts of the NFS server being run with root privileges.
This brings up a lot of security concerns, which is why the server
needs to be very well programmed.
Suppose we have two NFS clients communicating with the same server. Client 1 wants to overwrite some data currently on the server, call it X, with some new data, say X'. Client 2, however, wants to also read that same data. This introduces data concurrency issues, an example of which is displayed below:
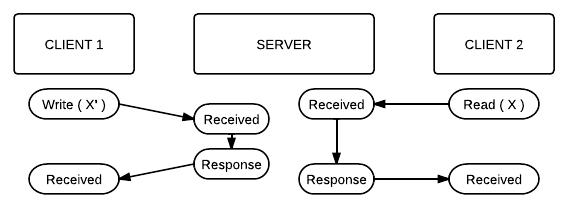
As you can see, Client 2 reads out X, even though X' is the newer
version of that data block. This example demonstrates how we no
longer have read/write consistency; we still maintain open/close
consistency, mainly because of the overhead associated with the close
operation.
Here are some reliability issues, and how NFS addresses them:
|
Reliability Issue |
NFS Solution |
|
Bad Network |
Simply try again, this usually works. |
|
Bad Client |
NFS doesn't address this issue! |
|
Bad Server |
NFS doesn't address this issue either! |
|
Bad Disk (Media Faults) |
We can attempt to combat this by logging (keeping a journal), however the journal itself may be corrupted, and so logging doesn't really solve this issue. |
We will now look at the standard technique to deal with media
faults.
RAID stands for Redundant Arrays of Inexpensive/Independent Disks. This is the process of linking up multiple data disks together to create a virtual disk that has a larger capacity than any of the physical disks alone. This idea was originally motivated by the economic advantages to buying multiple small disks as compared to a single large disk; however as disk prices have stabilized to a more fair distribution with respect to disk space, the 'I' in RAID was changed to reflect this fact. Originally developed in U.C. Berkeley, RAID is divided into categories, and we'll look at a few of them here:
|
RAID 0: |
Here we concatenate the disks to form a single virtual disk which is as big as all the physical disks combined. We can also allow striping, which is the process of storing sequential chunks of data in the virtual disk across multiple physical drives, allowing you to turn sequential read and write commands into parallel operations across the different physical disks. This will introduce some latency, but results in much better throughput. |
|
RAID 1: |
Here the goal isn't to make a bigger virtual disk out of a bunch of physical disks, but to instead increase reliability by mirroring our main data disk to the others. This way we end up with multiple data disks which are essentially clones of each other, and so we can perform operations in parallel on all the disks. This on average means faster reads and writes, up to twice the conventional speed. |
|
RAID 4: |
In this configuration, all but one of the disks contain the raw data, and the last disk is left for parity. The parity disk contains an xOr of all the other disks, which essentially acts as a backup. The reason for this is that A ^ A = 0, and 0 ^ A = A; this means that if any one of the disks needs to be restored, you can simply xOr all the remaining disks(including the parity disk) to get back the data that was originally on the lost disk. But this also means that only 1 disk may go bad at a time, and so if a disk does go bad, you will need to restore it ASAP, otherwise if just 1 more disk goes bad, your parity disk can not be used to restore either of them. |
|
RAID 5: |
Same as RAID 4, however takes into consideration the fact that the parity disk will be the busiest (as every write to any disk also needs to write to the parity disk). Here we remedy this situation by striping the parity data across all the drives, but this makes RAID 5 much more complicated than RAID 4. |
RAID configurations can also be combined, so for example RAID 0+1 is both concatenating and also mirroring the data across the disks. You can also build different RAID systems on top of each other, though this introduces unwanted complexity and overhead.