NFS stands for Network File System which is a file system that resides on the network as opposed to on the hard drive in your computer. This allows client computers to access files over a network the same way it accesses the local disk allow comparability with nearly every application. This allows you to easily access remote storage, share files across computers, and provide a centralized redundant file system for easier administration.
Performance
One of the many benefits of having a NFS is performance. Let us take a look at a Sun ZFS Storage 7320 Appliance:
|
Qty |
Type |
Vendor |
Model/Name |
Description |
|---|---|---|---|---|
|
2 |
Storage Controller |
Oracle |
7320 |
Sun ZFS Storage 7320 Storage Controller |
|
2 |
10 Gigabit Ethernet Adapter |
Oracle |
Sun PCI-E Dual 10GbE Fiber |
Dual port 10Gb Ethernet adapter |
|
4 |
Short Wave Pluggable Transceiver |
Oracle |
10Gbps Short Wave Pluggable Transceiver (SFP+) |
Short Wave Pluggable Transceiver |
|
2 |
Disk Drive w/Shelf |
Oracle |
J4410 |
SAS 20x300GB 15K,HDD |
|
4 |
Disk Drive w/Shelf |
Oracle |
J4410 |
SAS 24x300GB 15K,HDD |
|
8 |
SSD Drive |
Oracle |
512GB Solid State Drive SATA-2 |
SSD Read Flash Accelerator 512GB |
|
8 |
SSD Drive |
Oracle |
SAS-2 73GB 3.5-inch SSD Write Flash Accelerator |
SSD Write Flash Accelerator 73GB |
That's some serious hardware. The 136 300GB hard drives add up to a whopping 37 TB of total capacity. As you can see, no components are alone, including the storage controller. This is for reliability. Should one component fail, there is still another to continue doing the job. The SSD's are used for read and write caching. Since SSD's have very limited amount of write cycles, cheaper 73GB ones are used to cache writes.
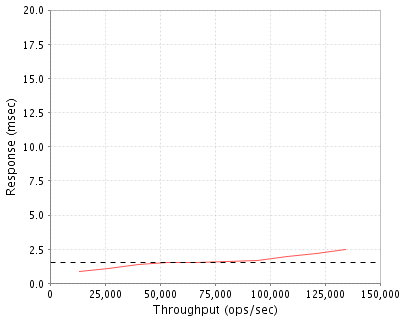
The hardware definitely shows how high performance it is. With over 130,000 operations a second, it still provides a low 2.5 ms response time. However, despite the linear looking line on this graph, the scaling is not linear and response time exponentially rises outside the graph.
NFS uses RPC's or Remote Procedure Calls to communicate between client and server. These are just messages that are passed to execute a procedure on another system. Essentially a client-server messaging system. I send a request, you give back a response, whether it's a "I finished my job" or a "Here's the data you requested".
Here is a diagram of what communication usually looks like. The client sends a request, the server sends back a response, and the client sends its next request.
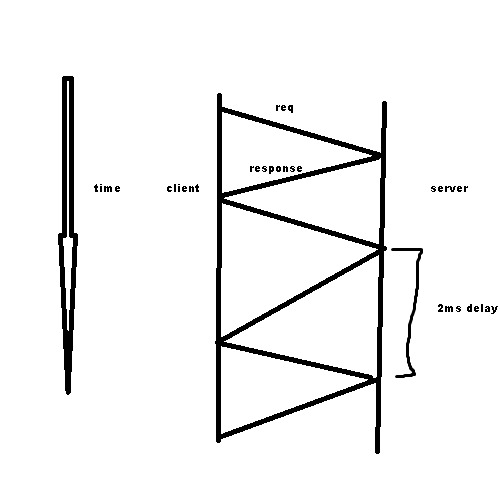
As you can probably see, this is rather slow going. The client has to wait for the server to send the next request. While a 2ms delay is used in this example, often times on the Internet, there will be delays of over 1000ms. If you have 60 requests, that's over a minute of just waiting for responses. We can instead, pipeline our requests and send them all at once instead of waiting.
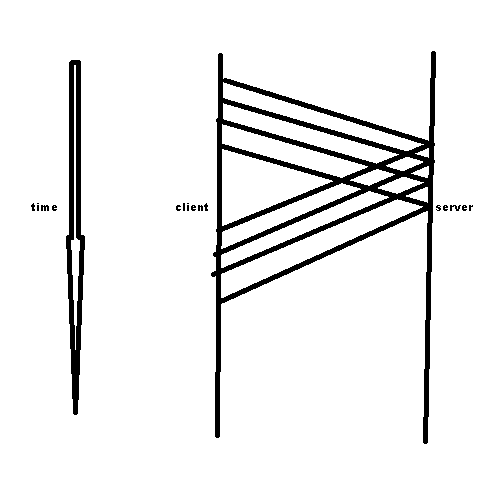
This is clearly much faster than having to wait for responses to come back. However, this leads to some issues. What if you sent multiple writes and one fails or goes out of order?
There are two solutions to this:
1) Don't pipeline and wait for responses (Slow)
2) Pipeline and ignore errors. Lie to the user about write failures. Instead, report errors when the file is closed. (Close is now slow)
Having close be slow is OK, since it's done considerably less than writes are.
Other issues with RPC
+Hard Modularity
-Messages can be delayed
-Messages can be lost
-Messages can be corrupted
-Network can be down
-Client cannot tell the difference between down and overloaded
Solutions:
We can checksum messages to ensure they are not corrupted and retransmit corrupted messages. If the network is down we can try two things:
-Try again until you get a response (At least once RPC) - Works for idempotent operations like read
There are issues with this as if the server is overloaded, having all the clients bang on the server until it responds won't make it respond.
-Return error to caller (At most once RPC) - Works for dangerous operations like write
-Exactly once RPC - Not exactly a thing to try, but optimally you would like your calls to execute once and only once and not question whether it ran or not.
The NFS server itself also tries to be more robust by remaining stateless. This means, even if the server crashes, since it maintains no state, clients will not notice if the server crashed and rebooted between operations. The RAM does not count as part of the state since it works just as cache.
The NFS Client and Server
Client:
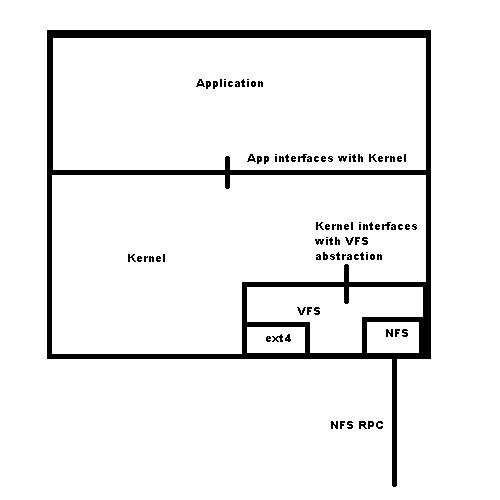
Server:
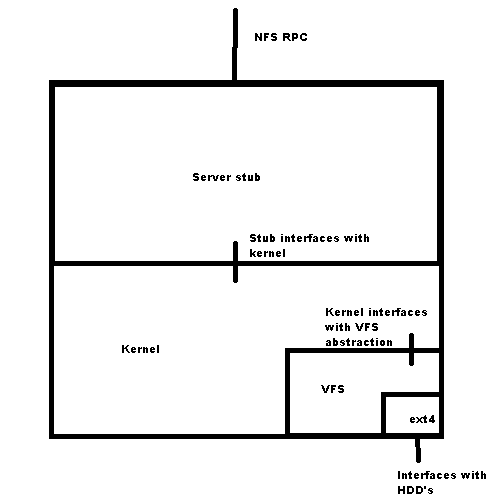
NFS Protocol:
read(fh, data)
write(fh, data)
lookup(dirfh, name)
remove(dirfh, name)
create(dirfh, name, attrib) -> returns fh.
Filehandles are just integers shared between the client and server. Inode numbers are also used, but NFS cheats with a kernel module that directly modifies the disk.
With multiple NFS clients, write to read consistency is not guaranteed, but close to open consistency is. This has less overhead than write to read, and ties in with error checking on close.
Security
File handles are tied to the UID of the user. However, on multiple machines, UID's may vary from machine to machine. Solutions include using the name of the user instead of the UID and/or authenticating the user using an authentication system such as Kerebos. Since files are passed as plaintext over the network, to prevent tampering or snooping, encryption may be used on the whole packet to prevent snooping and tampering, or just the checksum to prevent tampering.
Reliability Issues and Solutions
Bad Network - Retry
Bad Client - Retry or ignore
Bad Server - Retry
Bad Disk - RAID
RAID originally stood for Redundant Array of Inexpensive Disks as a way of having a large filesystem without having to pay exorbitant amounts of money for a large drive by concatenating many cheaper smaller disks into one big virtual disk. In modern times, RAID more often stands for Reduntant Array of Independent Disks as focus shifted from having larger filesystems to performance and reliability.
Raid Types:
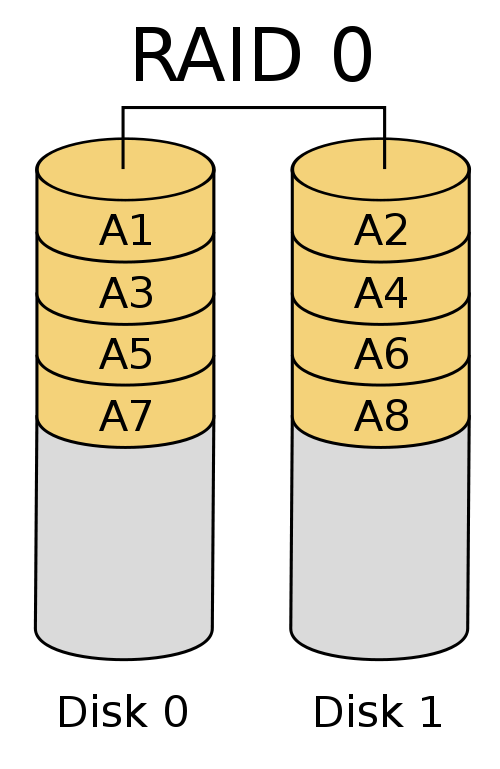
RAID0 - Concatenated disk. ie Disk 1 represents blocks 0-1000, Disk 2 represents blocks 1001-2000, to form a virtual drive with 2000 blocks. Alternatively, the disk can be striped instead, having alternating blocks on each disk which can increase performance on larger reads and writes as the disks can work in paralel. If one disk fails with a non striped RAID, you lose the data on the dead disk. If you lose a disk on a striped system, then you're likely to lose ALL data since much becomes unrecoverable when small chunks of every file are missing.
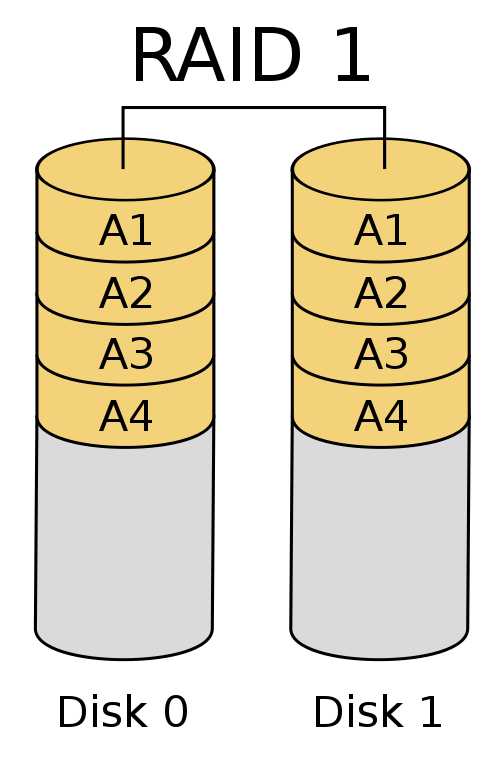
RAID1 - Mirrored disk. Exactly as it sounds, both disks are identical copies of each other. This puts reliability over disk space. If one drive fails, you still have the exact same data on 1 or more other drives. Reads can be done in parallel.
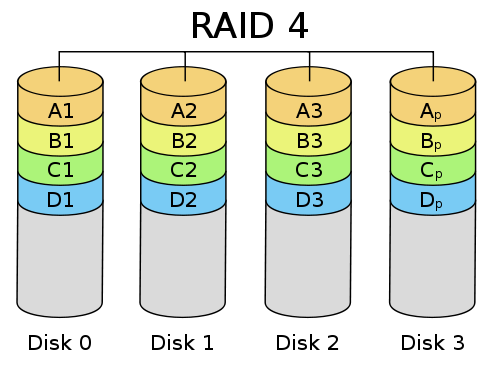
RAID4 - N-1 disks for data and 1 disk for parity. This tries to get the best of both worlds of having large filesystem and having reliability. The parity disk stores the XORed bit of every other drive. Upon a failure of any single disk, the data can be recovered by XORing the remaining disks with the parity. However unless the failed disk is replaced, data loss can occur if another disk fails. This also leads to a hotspot on the parity disk as for every write done on ANY disk, the changed bits have to be XORed and placed on the parity disk.