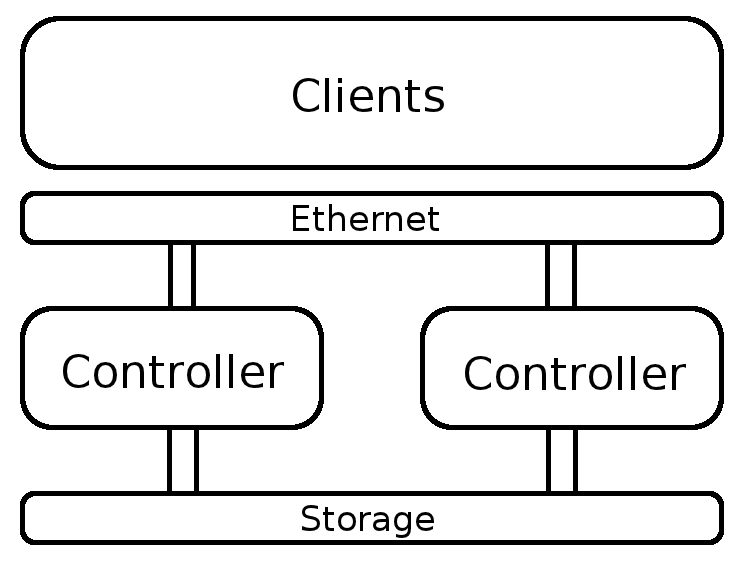
Sun ZFS storage 7320 Appliance (Release Scheduled: May 2012)
| 2 |
x |
Storage Controllers |
| 2 |
x |
10 Gb Ethernet Adapters |
| 8 |
x |
512 GB SSDs (read access) |
| 8 |
x |
73 GB SSDs (write access) |
| 136 |
x |
300GB, 15k rpm hard drives |
|
|
37TB total exported capacity |
|
|
32 File systems |
|
|
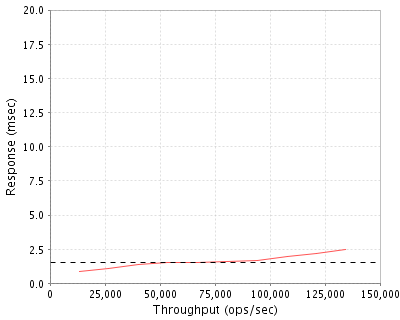
SPECsfs2008_nfs.v3 (spec.org performance measurement)
Throughput
(ops/sec)
|
Response
(msec)
|
|
13316
|
0.9
|
|
26650
|
1.1
|
|
40031
|
1.4
|
|
53505
|
1.5
|
|
66877
|
1.5
|
|
80791
|
1.6
|
|
94472
|
1.7
|
|
107873
|
2.0
|
|
121160
|
2.2
|
|
134140
|
2.5
|
|
|
Problem: Out of Order Requests
| write(fd, buf, 27); |
write(fd, buf, 1000); |
failed, but user doesn't know! |
write(fd, buf, 96); |
2 Solutions
-
be slow; don’t pipeline; wait for response;
-
be fast; pipeline; keep going; report errors on close (close is now slow)
must call:
if (close(fd) != 0)
error();
// otherwise code won't catch NFS errors.
Issues with RPC
- + hard modularity
- - messages are delayed
- - messages can be lost
- - messages can be corrupted
(a. Use checksums: if server detects a bad packet, send a response “?”, ask for a retransmission)
- - network might be down or slow
- - server might be down or slow
a. If no response from network or server:
-Try again: keep trying (at least once RPC)(ok for idempotent operations)(read or write)
-Return an error to caller (at most once RPC)(for “dangerous” operations)
-Exactly once RPC
NFS Protocol (RFCs, NFS v2, v3, v4)
READ (fh, data)
fh = an integer (file inode in actual file system) uniquely identifying a file
WRITE (fh, data)
LOOKUP (fh, name) -> fh+ attribute
fh: for a directory
name = string
REMOVE (fh, name)
CREATE (fh, name, attribute) ->fh
Reliability
Bad network: retry
Bad client/server (operator power off)
Bad disk (Media faults)
Can we address via logging?
Redundant Aarray Inexpensive (independent) Disks (RAID)
RAID 0
Concatenation (or striping)
Bigger virtual disk than physical
RAID 1
Mirroring: reads are faster on average (can read both disks at the same time)
RAID 4
Can restore from XOR disk
B=A^C^D^(A^B^C^D)
*Must notify operator of disk failure in a noticeable way before data is lost
when 2nd disk fails (no little red light in the corner of the server room)
Up to RAID 5 in original Berkeley paper