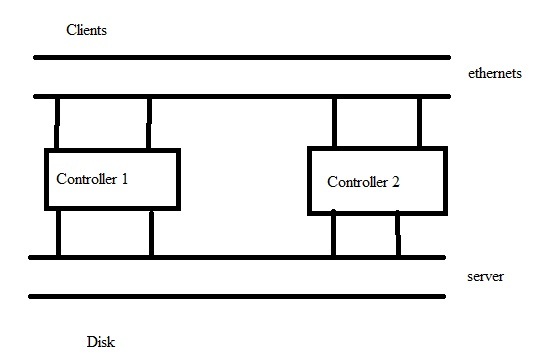
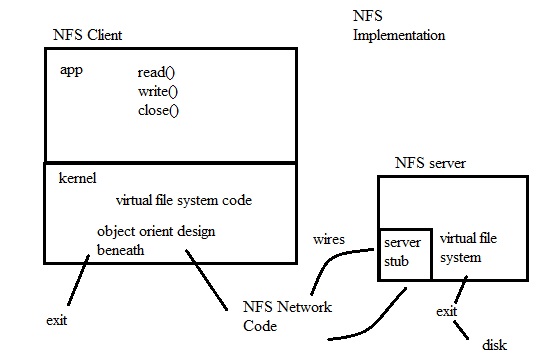
Figure 1. NFS Architecture
NFS - Network File Systems
What
are NFS?
NFS are essentially client server based file
systems.
Example performance figures of a real life NFS from
spec.org:
Sun ZFS storage 7320 Appliance (To be released in
May)
-2 * storage controllers (general purpose computers)
- 2 *
10 Gb Ethernet adapters
- 8 * 512 GB SSD (used for read
acceleration)
- 8 * 73 GB SSD ( used for write acceleration)
Each
type of SSD is tuned to make either reading or writing more
efficient.
- 136 * 300GB 15K rpm HDD
Figure
1. NFS Architecture
Overall
it has a 37TB capacity which is less than the sum of the space of the
hard drives because there is inherent overhead in having to maintain
a filesystem.
It actually has 32 file systems of ~1TB each which
help improve its overall speed.
How does NFS compare to local
disk performance?
8ms response time on local machine
1-3 ms
response time using nfs
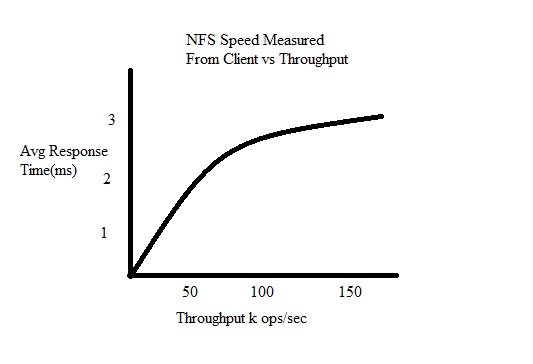
NFS’s
3x speed increase over a local machine is due to the overhead of
reading off an SSD and sending a packet over a network is much less
than waiting for a disk arm to seek to the correct location of the
disk and read the data off of it.
This example of an NFS is
also extremely reliable. There are at least two of every component
present in the system and thus there is no
single point of failure
in the system.
This is an important design property when it is
desired to have a high level of reliability in a system.
This
NFS emphasizes Redundancy
and Performance.
Performance
– how can we make it go fast?
RPC as part of
NFS:
Traditionally, requests between the client and server were
done sequentially, however, this method was extremely slow and now we
opt for the client to communicate with the server in parallel such as
through multiple threads. This parallel communication is known as
Pipelining.
Multiple threads operating in parallel work best if they are
independent and can get responses much faster than if each request
was made sequentially.
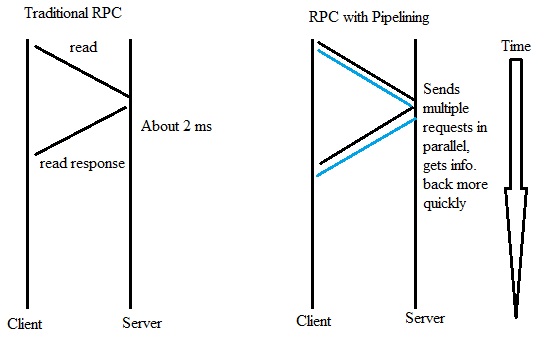
Example:
Old
web browsers used to operate in a sequential manner, but now they
send requests for multiple pages at once and get back responses in
parallel, thus improving the speed at which a user can view all of
the content on a webpage.
Pitfall:
Failed Out of Order(OOD) requests
A downside to sending multiple requests at once is that once several requests are outstanding an earlier request could fail while a later one succeeds. If this occurs, it can cause major problems for applications that were expecting earlier operations to have succeeded.
write(fd,buf,27);
have to notify the user that this operation
failed
write(fd,buf,1000);
write(fd,buf,96);
2
Strategies to overcome Failed OOD Requests:
1.) Don’t
pipeline and make the system slow. In this case, we wait for an
actual response to assure that each request has been processed.
2.)
Pipeline and be fast, but lie to the user about whether or not the
write worked.
Errors are reported when an application closes, and
this process is slow. The philosophy behind this method is that the
benefits of having faster reads and writes outweighs the cost of
being slow to close; since the application reads and writes much more
frequently than it closes, the application is overall quicker.
In
practice, most people choose option 2 over 1 as speed is very
appealing and easy to sell, however, 1 may be used
if correctness is prioritized.
Issues
with RPC
+
Hard modularity because it is run on different machines
- Message
speed is limited by the speed of light
- Messages can be lost
because networks are always lossy
- Messages can be corrupted and
the receiving end may get the wrong information
this problem can
be combated with checksums at the end of packets to check for
errors
- Network might be down or might be slow*
- Server might
be down or might be slow*
*A
huge issue with RPC is that you cannot tell the difference between
the server being down and the server being slow.
Options
if one end receives no response in RPC
1.)At
least once RPC
Philosophy
is that if there is no response, try again and keep trying.
This
method is ok for idempotent operations such as reads and writes (if
they are trying to be performed on the same location), however, it is
not valid for dangerous operations.
2.) At
most once RPC
This
method returns an error to the caller if there is no response such
as, “Sorry, rename failed because the network timed out.”.
This method is preferred for dangerous operations .
3.) Exactly
Once RPC
This
is the ideal case in which an operation is performed one time and
only one time.
Robustness
Constraint in Design:
NFS
assure a “stateless server” which means that if the
server crashes and reboot’s the client should’nt know or
care. The name comes from the fact that what is on the controller’s
RAM doesn’t count as part of the state. The controller’s
RAM is only a cache and cannot contain any information which could be
lost.
How
do we get this to work?
NFS
Protocol RFCS
all have familiar messages including
read(fh,
bytes, data);
write(fh,bytes,data);
lookup(fh,name);
remove(fh,name);
create(fh,name,attribute) -> fh
What
is a File Handle(fh)?
A
file handle is an integer which uniquely identifies a file.
In actuality part of the NFS file server lives in the kernel to make the system work, however this compromises the modularity of the system.
How does NFS operate with 2 Clients?
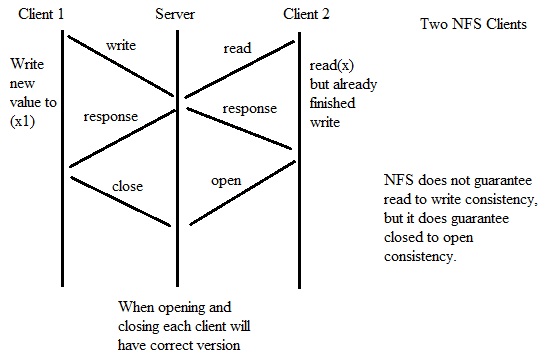
2
NFS Clients:
NFS
no longer guarantees write to read consistency with multiple clients,
but it does guarantee closed to open consistency because closing and
reopening is a much slower process and will ensure all changes are
accounted for.
Reliability:
Issues:
-
Could have a bad network.
- Could have a bad client.
- Could
have a disk go bad (media fault)
If there is a media fault the
whole system is in jeopardy because if there are bad blocks in the
write journal the cell data cannot be properly reconstructed if it is
lost.
RAID
(Redundant Arrays of Independent Disks):
RAID
is a system in which multiple disks are used to comprise a single
virtual drive. The original motivation behind RAID was to provide a
cheaper alternative to the expensive single drives which provided the
same memory capacity. RAID’s current motivation is to provide
increases in speed and/or reliability of a system. There exist
different types of RAID which each are tuned to prioritize certain
system qualities.
Raid
0:
Raid
0 concatenates the disks and forms a virtual disk drive which is the
sum of the capacities of each individual disk.
+ Striping – can spread out data between disks so that contiguous blocks may be read in parallel thereby increasing the read speed
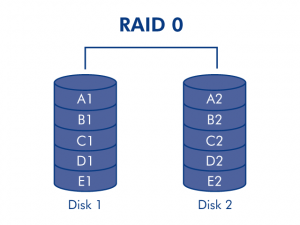
Raid
0 with striping
Raid
1:
Raid
1 has a single virtual drive which is represented by two physical
drives. Both physical drives contain the same data which is called
mirroring.
+ Faster read times because it can choose to read from the drive whose read head is closer to the desired sector to be read
-
Writes may be slower since it must write to both disks in
parallel
With RAID you can stack different levels of striping,
concatenation, and mirroring to obtain the system you desire.
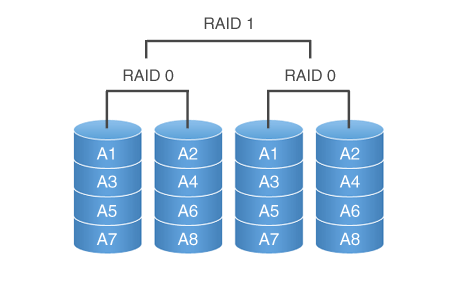
Raid
1
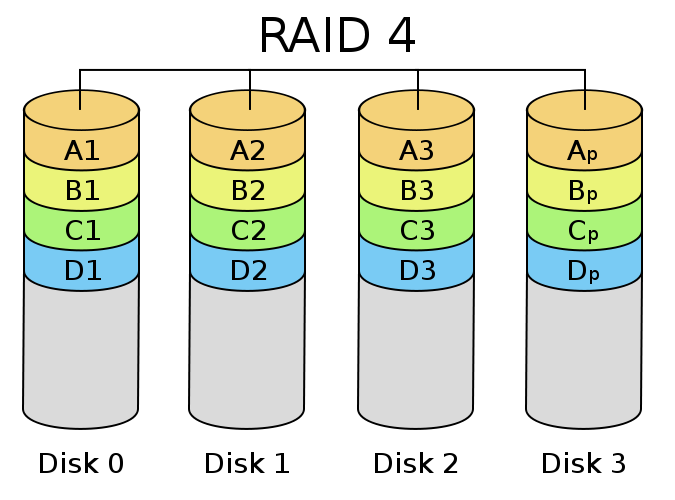
Raid
4:
RAID
4 uses N-1 of its disks to hold data and one disk to hold an XOR
combination of all of the data on the disks. This is advantageous
because if any single drive is lost, it can be reconstructed using
the remaining drives.
For example if Disk 2 in the picture
below dies, we can reconsruct it using 2 = 1^3^(1^2^3)
The
catch is that to gain the benefits of raid 4, one must always renew a
drive as soon as it fails.
If
two drives fail, data will be lost.
Since
the Nth drive is very busy since it has to be updated any time any
disk is written to, Raid 5 stripes the XOR disk across all of the
disks so that no single disk is a hotspot.