Prepared by Mary Chau, Tarry Chen, and Jessica Kain for a lecture given by Professor Paul Eggert on January 23, 2012
Table of Contents
- Hard Modularity
- Application’s Point of View
- Hardware Trap
- Virtualization is Only One-Way Protection
- Why Would a Process Not Run?
- Ways for Applications to Create and Destroy Processes
Hard Modularity
Hard modularity is obtained by breaking the system into separate modules where the modules cannot violate interface boundaries.
Unfortunately, we cannot simply use function calls to form interface boundaries. Instead, there are two methods that are commonly used in which hard modularity is accomplished: Client/Service Organization and Virtualization.
Client/Service Organization
If properly implemented, this structure allows us to achieve parallelism by taking each module and placing them onto separate computers. With the modules completely separated from each other, this ensures interface protection as well as an improvement in performance. To exemplify this organization, we will use the factorial example that was introduced to us in previous lectures. It should be noted that there is no parallelism in the below code since the client does not run another process while waiting for the server to return.
An example of a client/server version of Factorial:
Client code (Caller):
send(fact_name, (m) {"!", 5}); // m is the message type
a = get_response(fact_name);
if (a.response_code = = OK)
print(a,val);
else
return error();
Server Code (Callee):
for(;;){
receive(fact_name, request);
if(request.opcode = = "!"){
n = request.val; // compute n!
response = (m){OK, n!}
}
else
response = (m) {NG, 0};
send(fact_name, response);
}
Summary of the advantages/disadvantages?
| Advantages | Disadvantages |
| + hard modularity: client and server protected from each other | -performance is bad (ie. more CPU cycles) |
| + client and server can be on different hosts -more complicated |
Vitualization
A virtual machine uses one real machine to create another machine and emulate it. This method is used to protect the trusted code in the primary machine by placing and executing untrusted code in the "virtual machine".
How to go about this? Start by writing an x86 emulator, which will allow us to emulate the actions of another computer using our own, right down to the assembly level. A quick note though: The source code to this emulator is not exact and you have to "hand wave" bits and parts of it.
Source code to emulator:
int emul(int start_ip){
int ip;
for(;;){
char ins = mem[ip++];
switch(decode(ins)){
case pop:
}
}
We can then add the factorial instruction to our emulator and run the designated program inside the emulator. From here, the client would be located in the emulated program while the server would be located in the actual emulator. Due to this separation, the client is never in control. In C, this can be done as follows:
r = emul(fact's code addr)
switch(r){
case STACK OVERFLOW:
...
case TOO_MANY_INSNS:
...
case OK:
get return value of 'fact'
}
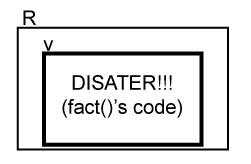
What are the advantages/disadvantages?
| Advantages | Disadvantages |
| + Hard modularity: virtualized code is in a safe box | - Extremely slow due to the emulation process |
| + Real and virtual machines do not need to have the same architecture | - More CPU cycles are necessary to run any virtualized process |
Virtualizable Processor
We can solve some of the performance problems with emulation by using processors that support virtualization. These processors give you control over what an emulated processor can do. In this particular scenario, we assume the emulated machine's architecture is similar enough to the real machine's architecture such that they can use the same processor. Some points about virtualizable processors.- The real machine needs to take over when the virtual machine issues "privileged instructions" such as 'halt', 'inb', 'outb', 'int', etc.
These "privileged instructions" lets you break out of the virtual machine into a real machine which we don't want to happen! - The real machine takes over after a time interval.
- Limiting memory access to locations in the virtual machine.
Application View of Virtualization
An example of a normal computation is as follows:
a = b*b - c*c; // full speed
An example of a system call is as follows:
write(1, "helloworld \n", 13);
If a program tries to issue a system call, the following registers will be loaded with the values shown below:
%eax system call # %ebx argument 1 %ecx argument 2 %edx argument 3 %esi argument 4 %edi argument 5 %ebp argument 6
Hardware Traps
In general, a hardware trap occurs when a privileged instruction is called which then passes control to the emulator. When the hardware trap is performed, the above values are pushed onto the stack. Using these hardware traps offers more transfer of control protection.To implement the write function via a deliberate crash, need to call a privileged instruction! More specifically, use the interrupt instruction, INT. For the implementation of the write function, we need to generate the necessary machine code. NOTE: The following implementation is "hand-waved".
ssize_t
write (int fd, char const *buf, size_t bufsize){
...
asm("int 128");
}
INT 128 causes a hardware trap and pushes onto R's stack the following values:
ss: stack segment esp: stack pointer eflags cs: code segment eip: instruction pointer
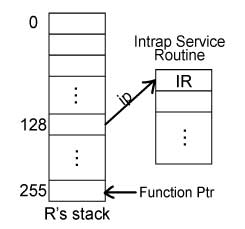
RETI vs. RET
The code in the real machine will invoke RETI. More specifically, ISR returns RETI and it is a more heavy weight instruction than RET. RET runs much faster than RETI.Important Notes:
- The only way for the client/server to talk to each other is via messages
- For the virtualization approach, the client is at the server's mercy.
Virtualization is Only One-Way Protection
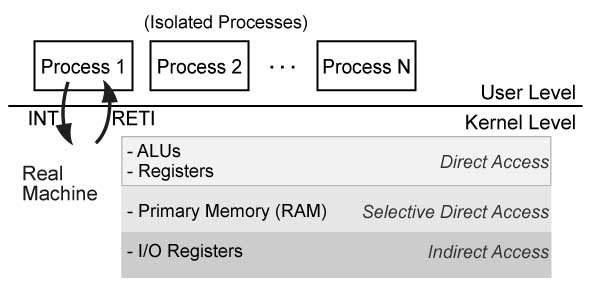
Virtualization, with typical virtualizable hardware, is much faster than the client/server OS model. Modern day operating systems are designed such that each process is independent to each other and each has its own "virtual machine". The process sees its own view of the stack, memory, variables, etc. The OS then takes care of how the real machine handles all these little virtual machines have access to its resources, such as ALU, registers, primary memory (RAM), and I/O registers. The ALU and registers have direct access to the virtual machine whereas primary memory (RAM) only has selective direct access and the I/O registers have indirect access.
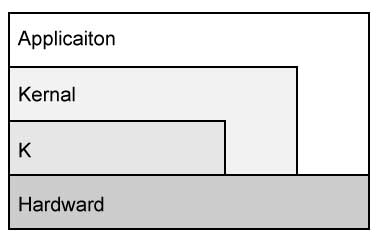
General OS Architecture
Traditional Linux Layering:
Modern Linux Layering:
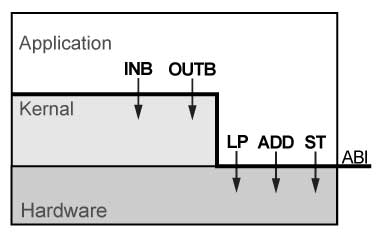
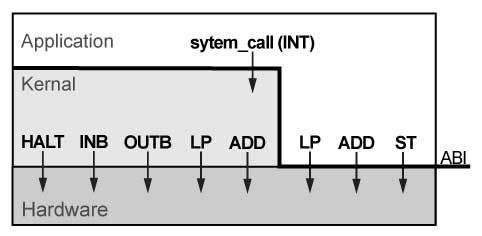
We can have multiple layers of abstraction too! x86 has four layers.
Why Would a Process Not Run?
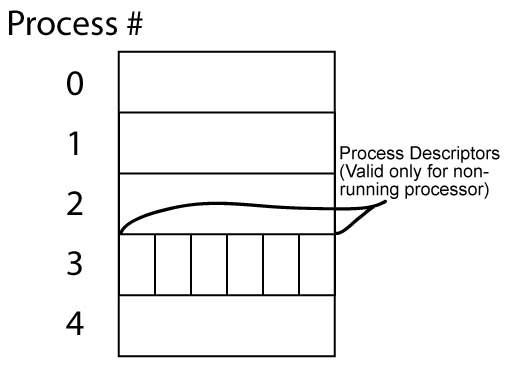
On a single core machine, at most one process can run, and as such, we need to make sure that functions that go between switches of different process contexts are as efficient as possible. For example, the getpid() function should only save to the %eax register and does not need to go through a full context switch (saving state of other registers, etc.), as the function will return to the same process that called it.
The caveat to this is that functions that require the protection of memory is trickier, but for now we will skip this. We will address this later in the quarter.
Ways for Applications to Create and Destroy Processes
To Destroy:- A process can issue a privileged instruction 'halt'
- exit(23)
To Create:
p = fork();This clones the process and has different behavior depending on the conditions.
- returns p = child's pid if the process is a parent
- returns p = 0 if the process is a child
- returns p = -1 if not enough resources allocated
pid_t waitpid (pid_t p; int *status, int options){
int i;
q = waitpid (p, &i, 0);
}
This code:
- Solves the garbage collection problem
- Ensures there are no "orphaned" children (ie parent process exit before child process)