Winter 2012
January 30, 2012
Lecture 6: Signals, Scheduling, and Threads (With a Brief Review on Pipes)
Scribe Notes Compiled by: Cameron Solomon, Christina Fries, Ervin Sukardi, Andrew AitchisonPart 1: Pipes
Section 1: Why Pipes?
Why do we use pipes? What is their purpose? Why would we prefer being able to do:
a | b
Instead of something that appears much simpler:
a > /temp/f
b < /temp/f
b < /temp/f
Advantages of Pipes:
The main advantage for pipes deals with being faster, in terms of performance, than that of simple I/O redirections. One reason for this is due to that in I/O redirection a temporary file has to be written in order for the information to be passed from one command to the next. This is not true with pipes in which the two sides of the pipe directly communicate with each other without a temporary file. Also by not having this temporary file pipes will save on memory by using a bounded buffer and just streaming the data between processes. In addition to this, pipes will run faster since there is no need for disk I/O, which results in no associated latency, but this could also have been avoided by using RAM. Lastly pipes have potential for parallelism since they do not rely on disk I/O, so multiple pipe commands could be run at once as long as there were no dependencies.
Disadvantages of Pipes:
The first disadvantage of a pipe lies in that if a pipe fails there is no information left behind by the pipe to see what caused the crash. While during the normal redirection approach the temporary file could act as a log, or as a way to save your intermediate result. Also when using pipes you are limited to using sequential access.
There are also a couple other alternatives to using pipes:
Shared Memory has all of the advantages of using pipes, but also allows you to store a log and have random access to files instead of sequential access. However, this method is also much more complex to implement, as you must synchronize all of your processes. You can also use a socket implementation, where one process (e.g. process b) acts as a server, while the other (e.g. process a) acts as the client. This also allows you to migrate your processes into a network environment, essentially creating pipes that cross machine boundaries.
Section 2: Pipe Implementation
To implement a pipe, we must first create a new system call to deal with it:
int pipe(int fd[2]); // fd is a file descriptor
When piping, you provide two file descriptors into memory, and return the status of the pipe in the form of an integer.
For example, when performing the command:
$ du | sort -n
We will need to invoke the fork() command twice.
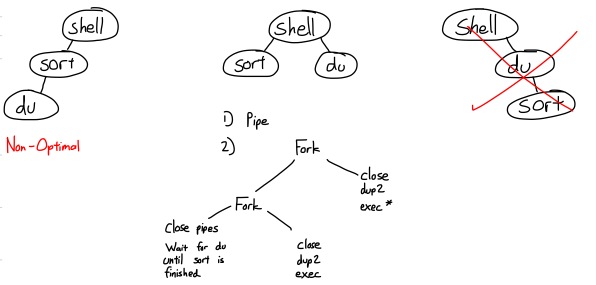
There are several problems when implementing pipes. Common problems that must be considered when implementing pipes:
Race Conditions ľ when executing a pipe, it is possible for the reader or the writer to finish and close their end of the pipe before the other finishes. For example, consider the following command: (a && b) | c In this example if the writer finishes before the reader, the reader should receive the EOF signal. While on the other hand, if the reader finishes before the writer, the write() command then returns -1, and errno is set to ESPIPE in order to tell that a nonexistent pipe is being written to.
Another situation to consider is:
echo hello | :
In this situation, there are three possibilities depending on how quickly the echo command executes relative to the : command, which tries to terminate immediately. The first possibility is if echo executes first and there is space in the pipe, then the write will succeed. Secondly if : executes first, but echo begins executing before the pipe closes, then the write will also succeed. Lastly if : executes first and closes the pipe before echo begins executing, then you will have a write failure, like above.
If you attempt to write somewhere without a reader in a Linux environment, the signal SIGPIPE will be sent and the process will subsequently die. In addition to this when executing multiple pipes, such as a | b | c, what if the intermediate command (b) fails? In this case the commands should actually be executed as such:
(a || touch af) | (b || touch bf) | c
Other command examples:
a > f | b
//b will get an EOF signal (a > f ; b) | c
//b will wait for a > f to completePart 2: Signals
Section 1: What is a Signal?
Say we wanted to execute the command:
gzip foo
When executing, we want to create the file FOO.gz and remove the file FOO.
A basic method for doing this would include:
1. Create the empty file FOO.gz, or overwrite it if it already exists
int fd = open(ôFOO.gz, O_WRONL | O_CREAT | O_TRUNC, 0666);
2. Reading from FOO and writing to FOO.gz3. Close the FOO filestream using close(fd), then check the exit status of write
4. Remove FOO using unlink(ôFOOö)
However, what if we were to be interrupted in the middle of this process, such as through the user interrupt CTRL+C?
Signal Handling is the act of dealing with unexpected or exceptional events. Because of this, we are allowed to assume that these, events are rare, and therefore can be handled less efficiently; therefore, while they still need to execute quickly the need not be as fast as a system call.
Signals change how our abstract machine works due to many reasons. One of which includes that they can arrive between any pair of instructions and therefore we treat them as asynchronous function calls:
movl 0x290, %eax
if(sigarrived) call handler
movl %eax, 0x390
if(sigarrived) call handler
movl %eax, 0x390
In addition to the above reason when a signal is received, all registers must be saved and restored which will greatly affect how other processes are executed by the machine. Lastly in order to specify what function is called in the case of a signal, we use a new API:
handler_t signal(int sig_num, handler_t handler_function)
Here, sig_num is the signal number, while handler_function is a signal handler function that takes the form:
void (*handler_t) (int)
Section 2: Implementing a Signal Handler
Normal Implementation:
#include < signal.h >
int gotpipe;
void handle(int sig){
gotpipe = 1;
}
int main(void) {
signal(SIGPIPE, handler);
}
int gotpipe;
void handle(int sig){
gotpipe = 1;
}
int main(void) {
signal(SIGPIPE, handler);
}
The point here is that should a signal occur within the main function, the handler function will then execute with SIGPIPE as its argument.
Alternate Implementation:
#include < signal.h >
char* gotpipe;
void handle(int sig){
gotpipe = malloc(100);
strcpy(gotpipe);
}
int main(void) {
signal(SIGPIPE, handler);
malloc(3000); // PROBLEM HERE
}
char* gotpipe;
void handle(int sig){
gotpipe = malloc(100);
strcpy(gotpipe);
}
int main(void) {
signal(SIGPIPE, handler);
malloc(3000); // PROBLEM HERE
}
Here, we are able to record our signal in a char*. However, we donĺt use this alternate implementation because if an interrupt occurs within the signal handler, the malloc will assume that everything is fine when it is not. However, there is a safe set of system calls listed in signal_safe calls
There are many different signals that exist; however, many common ones are listed below:
SIGPIPE
SIGPWR Power is being turned off; execute shutdown code in remaining cycles
SIGINT Standard interrupt
SIGHUP Logging out of a session (e.g. exiting a terminal)
SIGTERM Killing a process
SIGKILL Killing -9 a process; this signal in particular cannot be caught
SIGSERV A process is accessing memory itĺs not supposed to
SIGBUS
SIGALARM set an alarm for a particular time
SIGXCPU the process has exhausted the soft limit of its CPU time quota
Of particular interest is the KILL request:
int kill(pid_t pid, int sig)
Here, we specify a particular process ID and a signal number. This acts as a kernel request; we donĺt necessarily kill anything. For example:
kill(1, SIGKILL)
Here, there are three possibilities that can occur in which you donĺt have permission to kill the OS, you kill the OS resulting in a system crash, or you kill the OS but immediately restart it.
Additionally, there is a special signal handler called SIG_IDN that ignores all signals, as well as a default signal handler SIG_DEF.
With our signal handler, we are now able to adjust how we execute gzip:
0. Create the signal handler, which will unlink FOO.gz if it hasnĺt been finished.
void handler(int sig){
unlink(ôFOO.gzö);
_exit(93); // All signal-safe
}
unlink(ôFOO.gzö);
_exit(93); // All signal-safe
}
1. Initiate the signal handler
signal(SIGINT, handler);
2. Create the empty file FOO.gz, or overwrite it if it already exists int fd = open(ôFOO.gz, O_WRONL | O_CREAT | O_TRUNC, 0666);
3. Reading from FOO and writing to FOO.gz4. Close the FOO filestream using close(fd), then check the exit status of write
5. Since FOO.gz has been completed, change the signal handler to ignore signals
signal(SIGINT, SIG_IGN);
6. Remove FOO using unlink(ôFOOö)7. exit();
This also demonstrates the concept of signal blocking, where if a signal arrives, it is delayed and queued until the current process completes.
int sigprocmask(int how, const sigset_t* restrict set, sigset_t* restrict oset);
This command reads to set and writes to oset, and uses how to determine if we are blocking or unblocking. It is useful when executing a critical section of code, which must be executed to completion, or not at all. Afterwards, you do a signal unblock, where all received signals are handled afterwards.
Section 3: Signal Handling Alternatives
Method 1: Read a file that is stored in /dev/signals_received to check if a user did something exceptional. Here, we assume that a process is cooperating, but this is no different than normal signal handling. The difference is, here the process has to actively cooperate, while in signal handling, the process has to actively not cooperate. The developer then has a greater responsibility to do their signal handling correctly. This approach also makes use of polling. However, polling wastes CPU resources because of CPU overhead. Thus if we store this as a pipe, we can get the signals in the order that the signals were sent:
$ mkdir D
$ mkfifo p
ls ľl p
prwxr-xr-x ů p
$ cat p &
$ echo x > p
$ mkfifo p
ls ľl p
prwxr-xr-x ů p
$ cat p &
$ echo x > p
Method 2: Use a blocking record to wait for a signal in a separate thread