Our goal is to determine priorities as a function based on the system and user: f(c,e).
We can create a multilevel priority queue, for example:
-3 System Processes (must be run)
-2 Interactive (good response time)
-1 Batch (good throughput)
-0 Student
We can use different algorithms for each of the different type of processes, and processes can switch categories as they are being run.
Hard real-time schedling is a "hard" promise or deadline. The system can't miss a deadline, for example, vehicle brakes or a nuclear reactor.
Predictability and simplicity trumps performance. Some ways to do this include:
Turn off caching.
Disable interrupts, use polling instead.
Some deadlines can be missed, scheduler decides which. An example is video streaming, where the deadline is the refresh rate. If you miss the deadline, you just drop a packet. Some ways to decide include earliest deadline first or smallest work amount first (rate monotonic scheduling).
We want to be careful how packets are dropped or deadlines are missed. We want them to be sporatic, not continuous. Example:
The Achilles heel of threads. Threaded code is unsynchronized by default, so it is easy to write buggy code.
struct qpids {
struct qpids *next;
pid_t pid;
};
struct qpids *q; //head
struct qpids **qe = &q;
void append (pid_t p) {
struct qpids *new = malloc(sizeof(&new));
if (!new) error(...);
new->pid = p;
new->next = NULL;
*qe = new;
qe = &new->next;
}
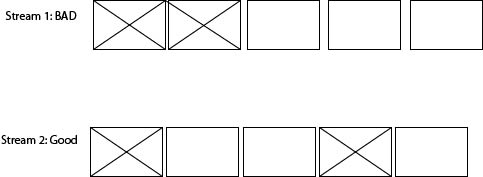
Problem: Two threads can assign qe/qe->next at the same time. This type of problem is hard to debug as it will not consistently occur. Each rectange below is qpids, with the left being the pid and the right being the pointer to next.
The requirements of coordination are:
isolation: Action X cannot interfere with anything
Sequence coordination: Action X must run before action Y, this is natural in sequential programming.
Atomicity is a technique to implement isolation.
An action X is atomic if for any other action Y: either X finishes before Y starts or Y finishes before X starts.
One possibility:
1. Every action is atomic - loses performance but maintains sequentiality. We can cheat with observability (what parts of the system can you see?). For the user, we do not see what occurs while the program is running or in what order the action are run.
SERIALIZABILITY principle: System executes actions in parallel, produces output, must be consistent with some interleaving of actions.
*qe = new;
qe = &new->next;
This data structure can be temporarily wrong.
enum {N = 512;}
struct pipe {
char buf[N];
size_t r, w; //read, write
};

void writec (struct pipe *p, char c) {
while (p->w - p->r == N)
continue;
p->buf[p->w++ % N] = c;
}
void readc (struct pipe *p) {
while (p->w == p->r)
continue;
return p->buf[p->r++ % N];
}
However, the above two functions do not parallelize well.
A critical section is a sequence of instructions such that atomicity is reserved if at most one thread's ip is executing within that sequence.
We need a way to enforce a criticacl section
1. Mutual exclusion (safety)
2. bounded wait (fairness)
An example using locks.
void writec (struct pipe *p, char c) {
lock();
while (p->w - p->r == N)
continue;
p->buf[p->w++ % N] = c;
unlock();
}
void readc (struct pipe *p) {
lock();
while (p->w == p->r)
continue;
p->r++;
unlock();
return p->buf[p->r% N];
}
However this does not work, we need to modify it as so:
void writec (struct pipe *p, char c) {
for (;;) {
lock();
if (p->w - p->r == N)break;
unlock();
}
p->buf[p->w++ % N] = c;
unlock();
}
void readc (struct pipe *p) {
for(;;) {
lock();
if (p->w == p->r) break;
unlock();
}
p->r++;
unlock();
return p->buf[p->r % N];
}
We do not want to make critcal sections too large (hurts performance) but we don't want to make it too small (introduce bugs and race conditions).
To do this:
A. Find shared states
B. Find writes to shared states
C. Expand horizon to include dependent read (reads whose results feed into writes)
D. Identigy minimal regions containing the above
void writec (...) {
size_t w;
...
if ((w = p->w)...)..
unlock();
...
}
p->w = w+1;
p->buf[w%N] = c;
unlock();
}
Coarse-grained locking
Simple, easy to explain and implement but has bottlenecks.
E.g. 1 core machine:
+cooperative threading ->lock(), unlock() = NUL ops
+preemptive threads -> lock() =block all traps, unlock() = unblock
Multicore machine:
-bottlenecks get you
Finer-grain locking
Lock just the data structure.
struct pipe {
char buf[N];
size_t r, w;
lock_t l;
}
Each pipe has its own lock.
writec ...
for (;;)
lock(&p->l);
bool isempty (struct pipe *p)
{
return p->r == p->w;
}
So far, we have been assuming atomic read. However, if we have an operating system with a 32 bit size_t and a 16 bit memory bus, when we look at p->r, we might get a mixture of old and new data i.e garbage.
Watch out for reads of large objects, need to know ABI.