File Systems
What We Value in a File System
- Performance
- Organization
- Fast to find stuff (if you know where it is)
- Easy to change things
- Space, lots of it
- Security
- Reliability
History of disk performance
CPU performance has been growing exponentially since the 1960s. Hard disk speeds have only increased from 3600 rpm in the 1960s to 15000 rpm in the present. File systems currently in use were designed in the 1980s, where CPU and hard disk speeds were similar. New designs should predict the change in parameters in the next 1-2 decades.
Hard Disks Structure
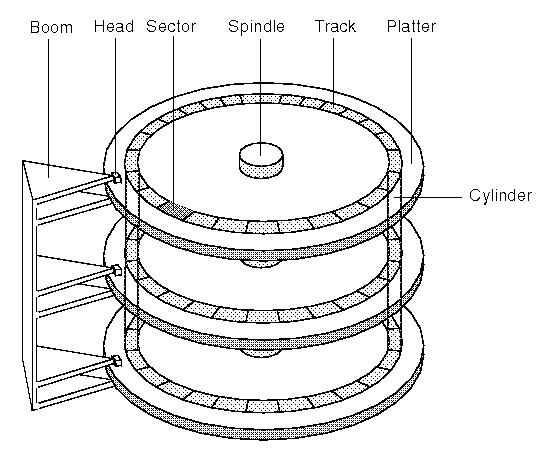
The shape of data that is easiest to read is a cylinder.
To read a different cylinder:
- Accelerate arms in right direction
- Start decelerating arms about halfway, so that they stop in the right track
- Wait for read heads to settle in treads
- Wait for data to rotate under head
Example Hard Drive: Seagate Barracuda LP 2
- 300 Mb/s external transfer rate - disk buffer to bus
- 90 Mb/s sustained data rate - disk read speed: mostly speed of spinning disk
- 32 MB cache - buffer to hold r/w data
- 5.5 ms avg latency - time until half disk rotates
- 10 ms average seek time - one sector of data to another at random (NB: this number is made up)
- 5900 rpm spindle speed = 98.33 Hz
- 50,000 contact starts/stops - number of times you can power hard drive on/off
- 10-14 nonrecoverable read errors/bit
- 0.32% annualized failure rate (for a constantly running disk)
- 6.8 W average operation (performing operations)
- 5.5 W idle without I/O
- 70G operating shock for earthquakes
- 300G nonoperating shock for earthquakes
- 2.5 bels acoustic (idle) - noise primarily from spindle
- 2.6 bels acoustic (operating)
An estimated average of 10,000,000 instructions can be processed (at 1 ns per instruction) in the time it takes to find another sector. This is slow. A faster option is flash, or a solid state drive.
Example SSD: Corsair Force GT
- 3 Gb/s external transfer
- 280 Mb/s read sequential
- 270 Mb/s write sequential
- 1,000,000 hours mean time before failure (not counting electronic wear from writing)
- 1000G shock
- 20W max power consumption
- 50 kilo I/O operations per second
While SSD performs better, at $90 for 60GB vs. $150 for 2TB on a hard disk, they are not entirely economical and thus cannot currently replace hard drives
File System Performance
Strategies to Improve Performance
We can use these methods to increase the performance of a file system without altering the hardware
Speculation (read):
The file system guesses what the application will do and does that work ahead of time.
- prefetching: guessing where application will read from later. This allows us to maximize the disk busy time.
- batching: application asks for 512 bytes, file system reads 8192 bytes at a time. If they ask for the next sector sequentially, then you have avoided latency for that call.
Dallying (write):
The application tells the filesystem what to do, but the filesystem waits a bit before doing it, with the idea of saving work overall by grouping together related tasks. Dallying can also be applied to read.This type of batching is especially useful when the file system caters to multiple applications, as you can then move the disk arm less.
Locality of Reference:
File access is not random in practice. Exploiting various forms of localities allows you to manipulate when you execute reads and writes for maximum efficiency. Forms of locality of reference include:
- spatial locality: data is all in the same area
- temporal locality: if a section has recently been referenced, it is likely that it will be referenced again in the near future.
- branch locality: useful for situations such as loops, the possible outcomes are restricted to a few locations.
- equidistant locality: halfway between spatial and branch, if the spatial/temporal distance between accesses is regular, the next location can be predicted.
Performance Metrics
- latency: delay between request & response
- throughput: how many requests/second can the file system handle
- utilization (of CPU): percentage of CPU devoted to useful work
- utilization (of disk): percentage of disk devoted to useful data
Though you generally want utilization to be high, you may prefer throughput performance over a short latency time. In the perspective of a systems operations administrator, who wants to maximize productivity for all users, a higher through throughput means more work down across all users.
File System Example: Imaginary Machine
- 1 ns cycle time (1 instruction/cycle)
- 1 PIO = 1000 cycle = 1 µs
- 5 PIOs to send a command to disk = 5 µs
- 50 µs disk latency
- computation reads data, 125 cycles/byte = 0.125 µs/B
- 1 PIO/byte to read
We will use the above machine as an example for our file system programs, because of their simple numbers. The following is a slow, basic program to process data in a file system. We can then apply various techniques to attempt to increase the speed and utility.
Initial Method
for (;;) {
char c;
if (sys_read(&c) < 0)
break;
process(c);
}
| send command | latency | inb | compute | total |
| 5 µs | 50 µs | 1 µs | 0.125 µs | 56.125 |
- latency: 56 µs
- throughput: 1/56.125 µs = 17817 requests/sec
- utilization: 0.125/56.125 = 0.2%
Method 0.5: Batch reading
In the first method, the initial latency is per byte. If we batch read in sectors of 40 bytes, we can distribute that value over the entire block:
for (;;) {
char buf[40];
if (sys_read(buf, 40) < 0)
break;
process(buf,40);
}
| send command | latency | inb | computer | total |
| 5 µs/40 | 50 µs/40 | 40 µs/40 | 5 µs/40 | 2.5 µs |
- latency: 90µs
- throughput 2.5 µs/B: 400000 bytes/sec
- utilization: 5%
Method 1: Overlap Input & Computation
If we use device interrupts, we can parallelize the IO and computation time in our batched process.
do {
block until there’s an interrupt
handle interrupt // issue PIOs for next request
// next request
// compute
} while(more data);
| send command | latency (50µs)in parallel with compute (5µs) | inb | total |
| 5 µs/40 | 50 µs/40 | 40 µs/40 | 2.375 µs |
Though we have combined IO and computation time, there is not significant improvement if we use a 40B block because the difference between computational time and IO is too great. In order maximize parallelism, the block size should be expanded to make computational time equal to IO (approximately 400Bytes).
| send command | latency (50µs)in parallel with compute (50µs) | inb | total |
| 5 µs/400 | 50 µs/400 | 400 µs/400 | 1.14 µs |
At this point, our processing latency becomes 455/400 µs/B, which is a significant improvement. This is the most optimized speed for our case, because IO and computing time are equal. The fastest time we could possibly achieve using the above methods is 1µs/B, which is the time it takes for one PIO call. At this point, the PIO speed becomes the bottleneck.
Method 2: Direct Memory Access
We can address the PIO bottleneck by using DMA. Using the optimized 400B sector, we get:
| send command | latency (50µs)in parallel with compute (50µs) | inb | total |
| 5 µs/400 | 50 µs/400 | 0 µs/400 | 0.14 µs |
This method removes the expensive PIO per byte in our process. However, it still retains the overhead required to call the interrupt statement, which could potentially bottleneck as well. In order to solve that, we apply:
Method 3: DMA + polling
This method uses DMA and polls the disk controller after computation has finished. For an optimized block size so that the program is well timed, there is minimal cost to the CPU to use a busywait. We can avoid the overhead of calling the interrupt handler and increase throughput. This increases disk utilization to 50/55, or 91%.
Method 4: Multitasking
In methods 1-3, we assumed that the file system had one CPU and IO device to execute to one program. They are useful for single-minded applications. In practice, we are more likely to have many different applications that we cannot control individually. Instead, we use multitasking.
// input done via this code snipped
while (inb(0x1f7) & 0xc0 != 0x40) { //while disk not ready
continue;
yield(); // invoke scheduler
// give the CPU to a thread that can use it
}
For a system with multiple processes, the best way to maximize utility is multitasking: if one process cannot do anything useful with the CPU, it hands it off to another. This method becomes so powerful that the previous examples become not necessary.