Here's what would happen if du is called in this example:
Consider the following:
$ du 76 a/b 97 a/c 263 a $ du -s a 263 a $ du -s a a/b 263 a $ du -s a/b a 76 a/b 157 a
Does something seem wrong? Why don't the apparent sizes match up? The thing is, there is no bug. du (and df) reports how much space is actually being used, not apparent size. Similarly, consider the call of ls -l on a large file below. ls reports both the apparent size of 239621721, and the actual size of, say, 2 (in blocks).
$ ls -l bigfile
-rw-rw-r-- 2 user csugrad 239621721 Feb 20 21:49 bigfile
Why do this? Why is the real size greater than the apparent size? One may think that is partially because some data is stored on RAM, while the rest is on secondary storage. However, this scenario is very unlikely, mainly due to the fact that data stored on RAM is not persistent. A file system design that has a high risk of data loss would not last in the real market. In this case, a much more likely scenario is when the system allocates more space than is usedfor a file, as illustrated below.
|
data |
reserved |
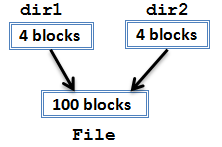
For the case when the real size is less than the apparent size, consider an example with hard links: dir1 and dir2 are two directories that contain a hard link to the same file.
Here's what would happen if du is called in this example:
$ du dir1 104 dir1 $ du dir1 dir2 104 dir1 4 dir2 $ du dir2 dir1 104 dir2 4 dir1
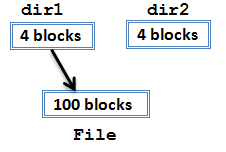
Just as seen earlier, du is doing its job by reporting the actual size of the files on disk. Hard links can lead to real size being less than apparent size because the size of the actual data is only reported once for all hard links to that data. Now for this same example, suppose the file system is 100% full. Here's an attempt to free up some space:
$ rm dir2/File
In reality, the system will still be full. rm did not actually remove the file, it only unlinked it. Here's what the file system looks like now:
What is a file system? To the user, it is simply a collection of files. But to the implementer, it's a bit more complex. A file system supports an abstraction of a collection of files by means of a hybrid data structure that lives on secondary storage and in primary memory. It should support persistence, security, and efficiency.
Perhaps one of the first questions to ask is: how do you know where the files are? Hard coding the locations files doesn't make any sense...
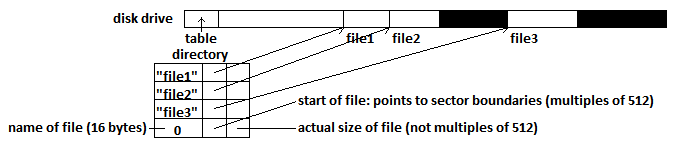
As an example, consider the RT-11 file system. The RT in its name stands for real time, which explains some of its characteristics.
Some downsides to the RT-11:

A defragmenter takes care of external fragmentation by aggregating data together. Note that if you run out of power in the middle of defragmenting, you lose the directory and mess everything up.
![]()
To be more specific, each file starts on a sector boundary, meaning they're stored as multiples of 512 (e.g. a file of size 3972 will be stored as a size of 4096). So how bad can it get? Suppose every file stored on the system is 1 byte. This would mean that every file would waste 511 bytes.
However, the RT-11 file system does have one good upside. It has good, predictable I/O due to contiguous files. That being said, the system still has many issues, as shown by its list of downsides. The two biggest problems are that file size is needed in advance, and it is difficult to grow files.
Now let's consider another file system, which uses something called the file allocation table (FAT).

Remember how it was very difficult to grow a file in the RT-11 file system? As an example, try to grow the file FOO.BAT in the directory. To grow the file FOO.BAT by writing, first find a '-1' in the FAT for a free space. Next, find the EOF block of the file in the FAT. Having found the EOF block, modify the FAT entry so it points to the new block. Also modify the new block to be the new EOF block. Finally, update the size in the directory, and write the data.
Consider the following example of trying to rename a file on a FAT system.
$ mv d/e d/f (easy) $ mv d/e x/y
The operation would be very simple in the first case, as it only involves changing the name in the directory. However, it's a bit different for the second case. If the operation was atomic, there wouldn't be any issues. Unfortunately, it's not atomic, which is why the order of operation can make a difference here. The end goal is to have x/ycontain the original data, and d/eto be free at the end. Do we write to xfirst, then clear out d? Or do we clear dfirst, then write to x? Suppose the power goes out in the middle of the operations. Depending on the order of operations, we could either lose both files, or have two copies of the same file sitting in two different locations.
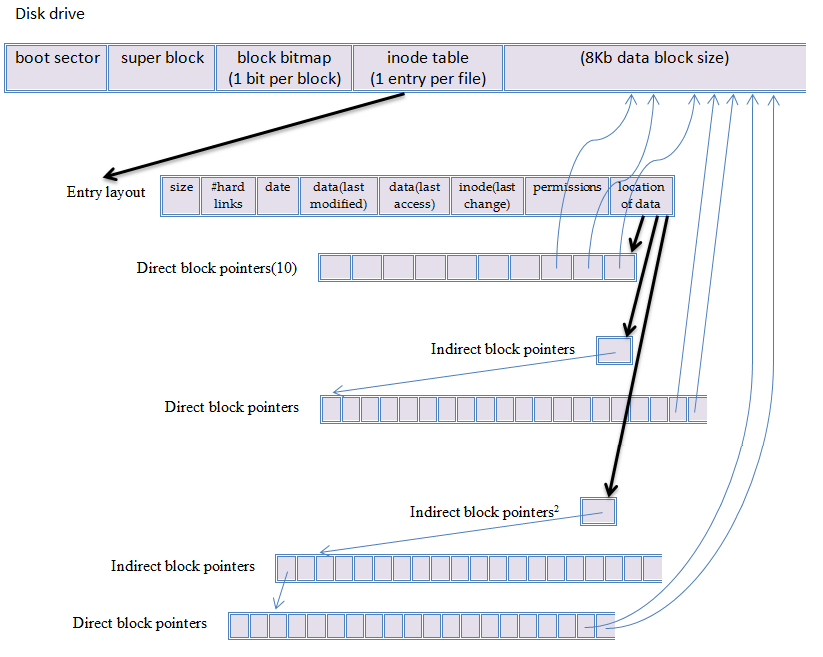
One thing to notice about the BSD-style system is the use of inodes, or index nodes. The inode table, taking up 1/216 of disk, is used to keep track of files. The table contains one entry per file (each file has an inode number), with each entry being a fixed size. Each entry contains information such as size, type, number of hard links, date (last modified - data), date (last access), date (last change - inode), permissions, and location of data. The inode excludes data such as the name of the file, its parent directory, and etc. This was designed to make renaming files easy.
|
permissions |
size |
... |
|
0 |
0 |
512 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
... |
|
The 10 numbers seen near the middle of the inode entry are the locations of the first 10 blocks of file, for files 80KiB or less. Notice that files can have holes, which are not allocated. They are read as zeros, and are created on write. As an example, there can be a file in this system that claims to be 1TB, with the file containing nothing but holes.
Why have holes in the first place? One possibility is lazy writing out of order. Another reason is for external hashing (which lives on disk, not RAM).
Since inode entries are a fixed size, what would happen for files larger than 80KiB? The way to solve this is to use indirect blocks. With this method, later blocks, say, the 11th block, can be used to point to a table of blocks. This can continue on to the next level. If the 11th block is an indirect block, the 12th block can point to a double indirect block, which points to a table of indirect blocks. This can be seen in the diagram at the beginning of this section.
The storage overhead of this method leads to ~1/2000 disk waste. That's not bad, considering lseek() now has O(log log N). This is very fast, just not as fast as RT-11.
|
14 byte name |
2 byte inode # |
|---|---|
|
|
|
|
|
|
|
|
|
The BSD file system has: