Computer Science 111 Lecture 12 - File System Implementation
Jesse Jiang, Matthew McKeen, Reed Wanderman-Milne, and Eric Wong
Symbolic Links
In Emacs, let's say you are editing the file /etc/passwd. Where Emac's buffer contents are not the same as the file contents, Emacs creates the symbolic link /etc/.#passwd -> eggert@penguin-:9371, where penguin is the host name, and 9371 is the process ID of Emacs. This is a locking mechanism: If there is already a symlink with that name, Emacs knows someone else is editing the file and won't let you open it. This way only one person can be editing the file at once.
What can go wrong:
Unfortunately, this locking mechanism isn't perfect. The following things can go wrong:
Text editors other than Emacs can change /etc/passwd. Because they won't create the symbolic link, Emacs can't use it to determine if other editors are editing the file. To get around this, Emacs calls stat("/etc/passwd"). to determine the modification time. If the file is modified after Emacs opened it, that indicates another editor is editing it, so Emacs will warn you before rewriting the buffer contents.
Emacs can crash, causing it not to delete the symlink. Emacs solves this by checking the process ID contained in the contents of the symlink (9371 in the first example). By running the command kill(9371, 0), Emacs checks if there's a process with the given process ID. The 0 indicates we only want to determine if the process exists. Unfortunately, this workaround has its own flaws, as another process can reuse the process id 9371 if Emacs crashes.
Emacs can go into an infinite loop with the lock, so the process still exists but Emacs still will never delete the symlink. A workaround is a different Emacs can steal the lock, by deleting the symlink and creating a new one with its own process id.
/etc/.#passwd can exist for some other reason. The solution Emacs uses is to check if /etc/.#passwd is a regular file and if so, don't lock. We hope this case is very rare.
Another application can remove the lock file, or change what it points to. This will mess up Emac's locking capabilities, and so hopefully other applications don't do this. Since using the lock and not messing it up is purely voluntary, we cannot enforce the locking mechanism.
You haven't change the buffer yet, and someone else locks it before you do. The solution to this is similar to the solution for 1: Emacs calls stat("/etc/passwd") to see the last modification time
The filename part after the last / is at least 254 characters. Since the max filename is 255 characters, Emacs cannot add the '.#' to the beginning of it. In this case, as in 4, Emacs will not lock
Different Emacses running on different host, such as lnxsrv03@seas.ucla.edu and lnxsrv03@seas.ucla.edu, cause multiple problems. Since we cannot kill processes on other machines, our workaround to problem 2 will not work. Additionally, in Microsoft Windows, you need a special permission to create symlinks which many users don't have. One workaround to this is to use regular files. However, in that case, the solution to problem 4 will fail!
With all sorts of problems, we might think that are better ways to lock than symbolic links.
Alternatives to using Symbolic Links for Lock Files
One alternative is to use fcntl system call, by calling fcntl(fd, F_SETLK, ...). This is a voluntary lock on the file. One problem is that this method is not supported in Windows. Another is this postdates Emacs. A third problem is that this method didn't work with NFS until version 4.
Another alternative is using regular files for locks instead of symlinks. This has a couple of advantages and disadvantages.
One thing to be concerned about with regular files is performance. A regular file for the lock will look something like this:
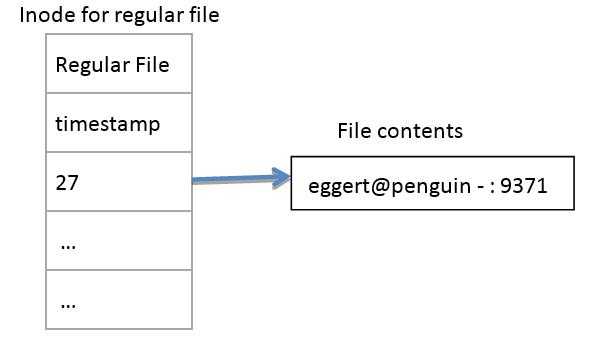
There's an inode for the regular file, and a single data block holding the short amount of data. Short symbolic links look like this:

Here, an optimization is made: because the contents of the symbolic link are so short, they can fit directly inside the inode! As long as the length of the symlink is less than or equal to 48 bytes, it can fit. This means that reading short symlinks takes less block reads than reading the equivalent regular file, since you don't need to read any more blocks after reading the inode. Using symlinks as a locking mechanism will therefore be faster than using regular files in most cases. However, some modern file systems allows the same optimization to be used in regular files. In this case, symlinks lose this advantage over regular files.
Another advantage of symlinks becomes apparent when one looks at the number of system calls used. For regular files, one needs to call the following three system calls:
- open("file", ...);
- read(fd, buf, bufsize);
- close(fd);
For symlinks, only one system call needs to be used:
- symlink("file",buf,bufsize);
Additionally, reading the symlink is an atomic operation, while someone can change a regular file in the middle of a read. The overhead of the extra two system calls and the lack of atomicity in regular files gives a compelling reason to use symlinks instead.
One problem with symlinks is that we cannot modify them. For now, let's assume that the contents of our symlink is not contained in the inode, but instead in data blocks, like a regular file. After running the command
- $ ln -s 'eggert@27' foo
we will have a symlink that looks like this:
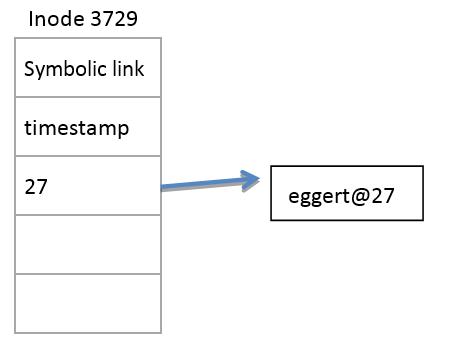
Let's say we next run
- $ ln foo bar
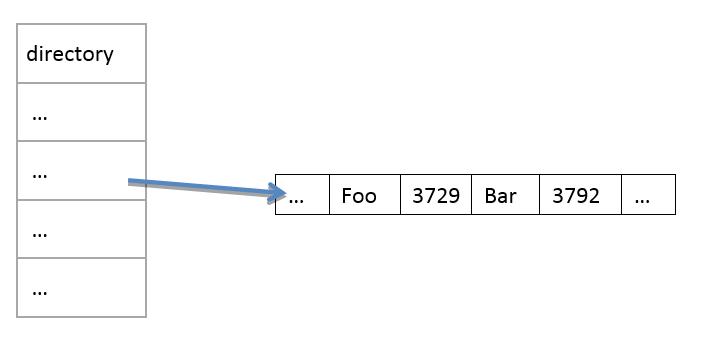
Normally, we would be able to modify foo to change bar, or the other way around. However, since we cannot change symlinks, we can't change one to change the other. It's impossible to get around this by deleting foo and recreating it as a different symlink too, since that still would not change bar.
One way to speed up accessing symlinks is to put them directly in directory entries, as shown in the diagram:
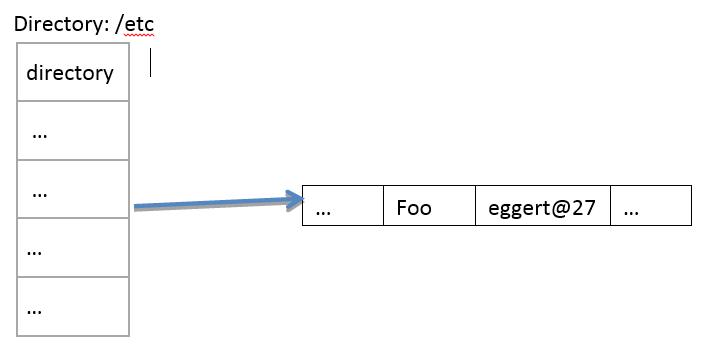
In this case, instead of the directory entry containing an inode number referencing an inode, the entry contains the symlink contents directly. This saves disk accesses, since once we read the directory block containing the entry, we have the symlink data we need. However, this requires a bigger entry size, since symbolic links take more space than inode numbers typically. Also, this prevents us from having hard links to symlinks.
Symbolic Link Security Problems:
Let's say an attacker, Professor Eggert in this case, wants to read some information from another user. He issues the following commands:
- $ ln -s ~eggert/data /tmp/foo
- $ touch ~eggert/data
- $ chmod 777 ~eggert/data
- $ cat ~eggert/data
- $ umask 077
- $ sort -o /tmp/foo
- $ uniq /tmp/foo
- $ rm /tmp/foo
The victim thinks they are outputting the sort command results into a file no one has access to. However, since the file is actually a symlink to ~eggert/data, Professor Eggert will have access to the output of the sort command.
File Name Resolution
Suppose we issue the command:
- open("a/b/c/foo", O_RDONLY |...)
To execute this command, we need to execute the following steps:
- Get the process's working directory, D, from the process table (or if the file starts with a /, set D as /.)
- Get the 1st file name component, C.
- Look up C in D (if C doesn't exist in D, fail and set errno to ERRNOENT)
- We now have an inode entry. Set D to that inode entry, and go back to step 2
Suppose we have the symbolic link a/b -> x/y. Then, in step 4, when we encounter b, we need to substitute it for the contents of the symbolic link. In this case, we would replace b with x/y, so we would be opening a/x/y/c/foo. If the symlink contents start with a /, we must set the working directory to /.
We can get various errors, such as:
- errno == ENOTDIR: this occurs when filename like "a/b" is not a directory but should be
- errno == EPERM: we don't have permission to access the file
- errno == ELOOP: We traversed too many symlinks. Because we want to make sure we don't have an infinite chain of symlinks, we must check during file name resolution. Because it is costly to maintain a data structure keeping track of what symlinks were visited so far, we instead set a limit of a maximum chain of 20 symlinks traversed.
System calls chdir and chroot
chdir("foo") changes the working directory to foo
chroot("bar") changes the root directory to bar
Let's say we have the following program in file main.c
- //main.c
- #include <unistd.h>
- int main(int argc, char** argv) {
- chdir(argv[1]);
- }
Then let's say we execute the following shell commands, assuming we have a file in /tmp/foo
- $ gcc main.c -o mycd
- $ ./mycd /tmp
- $ cat foo
This will not actually output the contents of /tmp/foo. Running mycd will fork a new processes and change the working directory of that process. The working directory of the shell will remain the same as before. To change the working directory of the shell, a program cannot be used, and instead must be implemented in the shell itself.
chroot is a privileged system call, meaning only root can go it. To see why, consider the case where the following file exists:
- /home/eggert/playpen/usr/bin/passwd
Now consider the following functions being called:
- chroot("/home/eggert/playpen");
- system("/usr/bin/passwd"); //utilizes the wrong passwd file
In this case, the wrong passwd file is executed. To avoid this security vulnerability, chroot is a privileged system call.
Link Counts and Hard Links
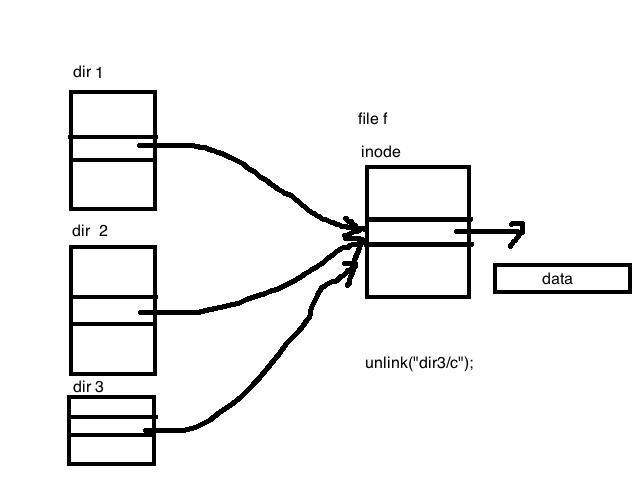
Link counts indicate how many files are hard linked to a particular inode, including the original file. For example, in the above example, file f has a link count of 3. If we run the command:
- unlink("dir3/c")
The link count is reduced from 3 to 2. Once a link count reached 0, the inode and the corresponding data are freed so the disk can allocate new inodes and data to those regions
Problems with Link Counts
-
There can be a bug in the system: A link is removed, but the link count was not decremented
- The file system will leak blocks in this case
- No data will be lost, however
-
There can be a different bug: The link count can be decremented but a link was not removed
- The file system has a dangling pointer in this case, which has undefined behavior
- Data can be unintentially lost in this case, if the file system frees a block with a link count of 0
- This case is worse than case 1.
- Link count overflow: the link count can overflow the size of the integer holding it
- Solution in this case is the set a (high) limit to the number of link counts
- Loops of hard links: Let's say we have a loop of hard links as shown in the diagram:
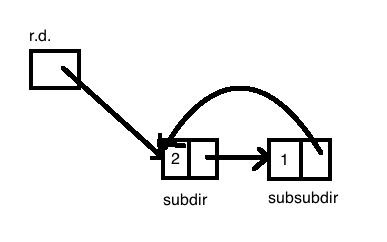
In this case, we can go infinitely deep into the hierarchy of directories. To avoid this, we do not allow hard links to directories.
A Brief Look at other File System Issues
GPFS (an example big-machine file system)
A sample machine using this file system holds 120 PB over 200,000 hard drives (about 600 GB each). This is done for performance: there are more disk arms, and so many seeks can be done at once.
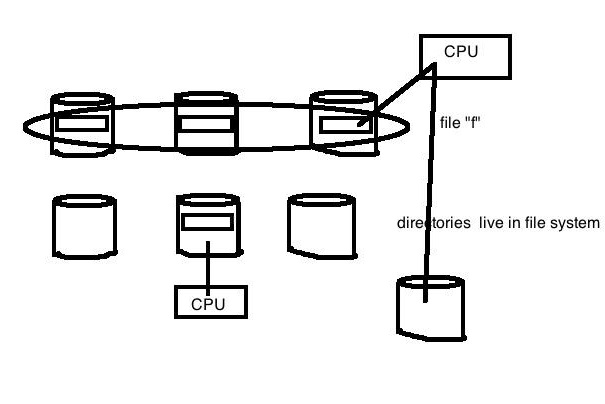
Striping, the process of holding blocks of data over multiple disks, is done to take advantages of parallel I/O. For example, in the above diagram, file f is contained over 3 hard drives, so it can be read 3 times as fast. In this way, the hard drives are relatively small, so there are more hard drives and more parallelism can be used.
Distributed Metadata
Another property is distributed metadata. Files and directories used frequently are put on multiple hard drives, so multiple CPUs can access them at once, and CPUs can access one on a nearby hard drive. For example, /usr/bin is a very frequently used directory. It therefore will be put on many different hard drives, so when a CPU needs to access it, it can choose the closest hard drive.
Indexing
GPFS needs to have efficient directory indexing that is faster than O(N) (for example, using a B-tree). Let's say the physics department takes 10,000,000 images of a physics experiment. They name the files exp1.img, exp2.img, etc, all the way up to exp10000000.img. To look up an entry takes O(N) time, where N is the number of files used. This would take way too long normally, as the file system would have to look up potentially 10,000,000 entries before finding the right file. The diagram below illustrates the issue:
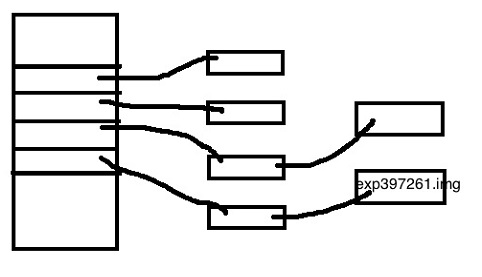
Distributed Locking
GPFS should have a distributed locking system to make sure multiple CPUs won't write to the same data at once.
File System Stays Live During Maintenance
If we run the commands:
- $ cd /gpfs
- $ tar -cf /dev/tape
We might get a wrong copy, since in the middle of the tar command, data can change and we get an intermediate stage of the file system.
To solve this, we assume we have an imaginary command, magic-gpfs-clone, that gets a copy of the file system at a single given point of time. Then, we can run:
- $ magic-gpfs-clone /gpfs /gpfs-feb25
- $ cd /gpfs-feb25
- $ tar