Dealing with Unreliable Processes
Lecture 14, Spring 2013 CS 111
Prepared by Paul Botros
I. THE PROBLEM
Running code is inherently error-prone, and one of the most common errors is referencing "bad memory" -- memory that is either reserved by the operating system or that has not been allocated to a particular process. Since the 50s, subscript errors and dereferencing bad pointers (NULL, uninitialized, or freed pointers, for example) have been a known and troublesome problem.
Referencing "bad memory" has undefined and possibly dangerous ramifications. Without any type of checking, a process can access any range of memory, including those reserved for the operating system or reserved for another process (the kernel’s global variables, I/O buffers, arbitrary positions in the heap, etc.). Any modification of "bad memory" will have undefined effects and lead to corrupted memory, process errors, or kernel crashes.
The first possible solution is to simply fire the programmers responsible for the unreliable code. With sufficient checking and error handling, referencing bad memory can always be prevented. However, it is unrealistic to have such high standards; it is nearly impossible to engineer a large software project without a single memory error, and so this paradigm cannot scale.
Another possible solution is to change the way the code is run. Instead of running a program directly on the operating system’s physical memory, adding a layer capable of runtime checks enables these bad memory references to be caught. Java compiles its code into bytecode instead of traditional machine code and uses a Java Virtual Machine (JVM) to translate this into machine instructions at runtime. This allows the JVM to perform runtime checks for referencing bad memory; if an invalid subscript is requested or a bad pointer dereferenced, the JVM will catch this at runtime and throw an exception.
ASIDE
The Burroughs B5500 avoided the issue of code trust by enforcing the compiler as a part of the operating system; assuming the compiler itself is trustworthy in checking for bad memory references, the resulting machine instructions should be safe and reliable.
While Java’s paradigm of an additional "manager" layer works to prevent referencing bad memory, this approach is often slow and inapplicable. While each performance hit might be negligible, these overheads can add up, since all bytecode instructions need to be both checked and translated before being run on the hardware.
More importantly, runtime checks fail in the large majority of cases because there is no "interpreter"; the user will (almost) always have the option to run machine code directly and bypass any runtime checks. This then boils down to a matter of trust; there is no guarantee this machine code only references valid memory. Our operating system must be fault-tolerant, even in the absence of any form of trust.
Because a user can, in effect, bypass any operating system checks, we will need help from the hardware to catch these bad memory references and consequently notify the operating system of some sort of exception.
II. APPROACH 1: BASE / BOUNDS
For each process description, allocate 2 extra registers for storing "base" and "bounds" addresses; denote these as "base" and "bounds" registers, respectively.
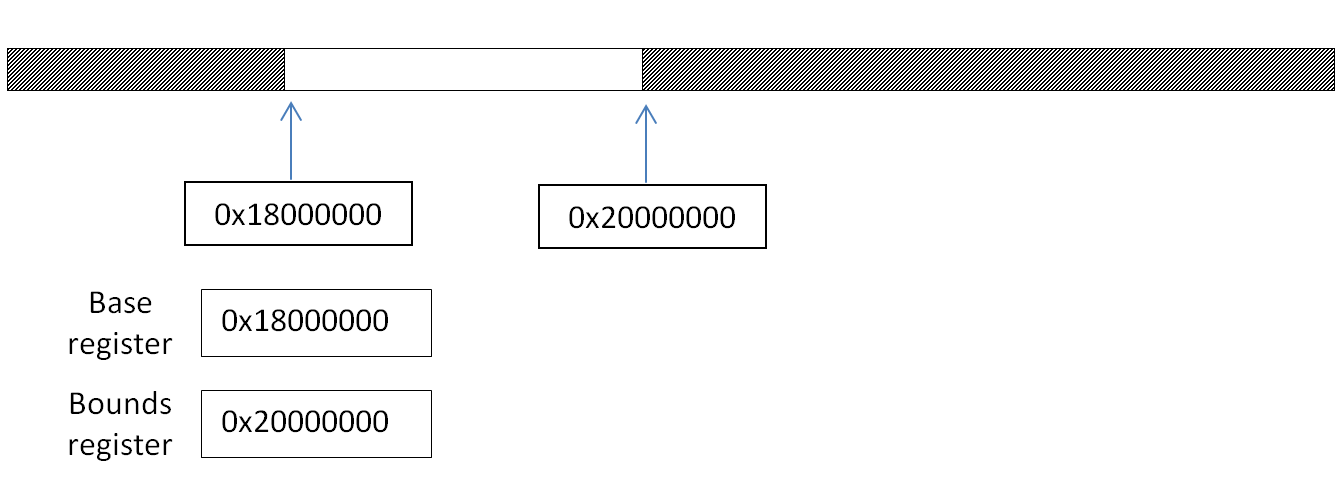
For each new process, the operating system will allocate a range of memory dedicated to this process and store these values , and on each load or store, the hardware will consult the base and bounds register to check if the requested address is valid for this process. If it is, execution will continue as normal, but if it isn’t, an exception will be thrown and the appropriate kernel handlers will be run.
Pseudo-C for a load instruction
char load(void *addr) { if (addr >= BASE && addr < BOUNDS) { return *addr; } else { throw memory exception; } }
This approach requires that each process receives exactly one contiguous region of memory, since there is a single base and single bounds value. While this problem can be alleviated with multiple base-bounds pairs, this is more of a "band-aid" fix, and the number of base-bounds pairs will always be wrong (too few and the problem isn’t solved, but too many base-bounds pairs and it will be a waste of space).
Another problem is exemplified by the fork call. A call to fork on a process copies the currently running process’s stack, text, and data regions of memory to a separate piece of memory. Consider a process that sorts a given set of numbers, and assume it forks a child process somewhere in its execution.
In our implementation, this means that the child process will be given its own base-bounds pair for memory access, as follows:
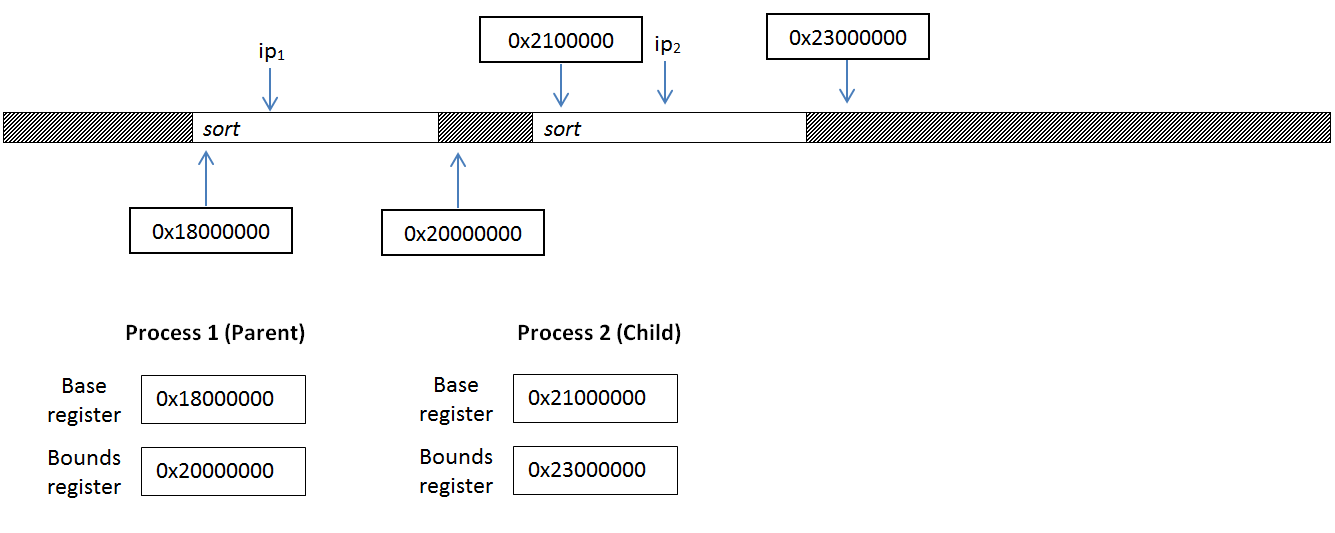
One immediate problem with this is in memory references. Both copies of the sort program (one starting at 0x18000000 and another at 0x21000000) will contain exactly the same set of instructions. What if the program contains an instruction such as jmp 0x19000000? The fork will copy this instruction exactly, and the child process will execute this, jumping outside of its base/bounds memory range.
The above problem is a problem on our base/bounds implementation because of absolute addresses.
How can this be remedied?
- Disallow programs from containing absolute addresses; only relative addresses can be used. Every relative address will have the base value added to it in order to determine the absolute address for the hardware to access.
- Mutate the program as it is loaded into RAM, appropriately changing all absolute addresses to ensure the correct memory is accessed. In the above example, this would change all instructions such as jmp 0x19000000 to jmp 0x22000000, since the two copies are offset by 0x03000000. This means that copies of a particular program that exist in memory (like the two copies of sort as above) are in fact not equal.
ASIDE
Code without absolute addresses is called position-independent code, or PIC. This means that a program can run regardless of its absolute position in memory, and so PIC is suitable for both shared libraries and older computers that lack any form of memory management. gcc allows compilation into PIC via its -fpic and -fPIC flags.
Another problem with our base/bounds implementation is in security; what if a process tries to change its base/bounds registers? Allowing arbitrary access to these registers will allow a process to access arbitrary memory regions; imagine if it changed its base and bounds to cover the entire span of memory. A solution to this problem is to make these registers privileged; on every instruction that would try to store into the base/bounds registers, the hardware should first consult the current process’s privilege, ensuring only "root" can change these two registers.
The final nail in the coffin with this base/bounds implementation comes in sharing memory between separate processes. In the implementation as it stands, if two processes want to access the same piece of memory, the operating system needs to determine the base/bounds pair such that the ranges overlap over the appropriate shared address.
Consider the following solution to sharing memory location 0x39000000:
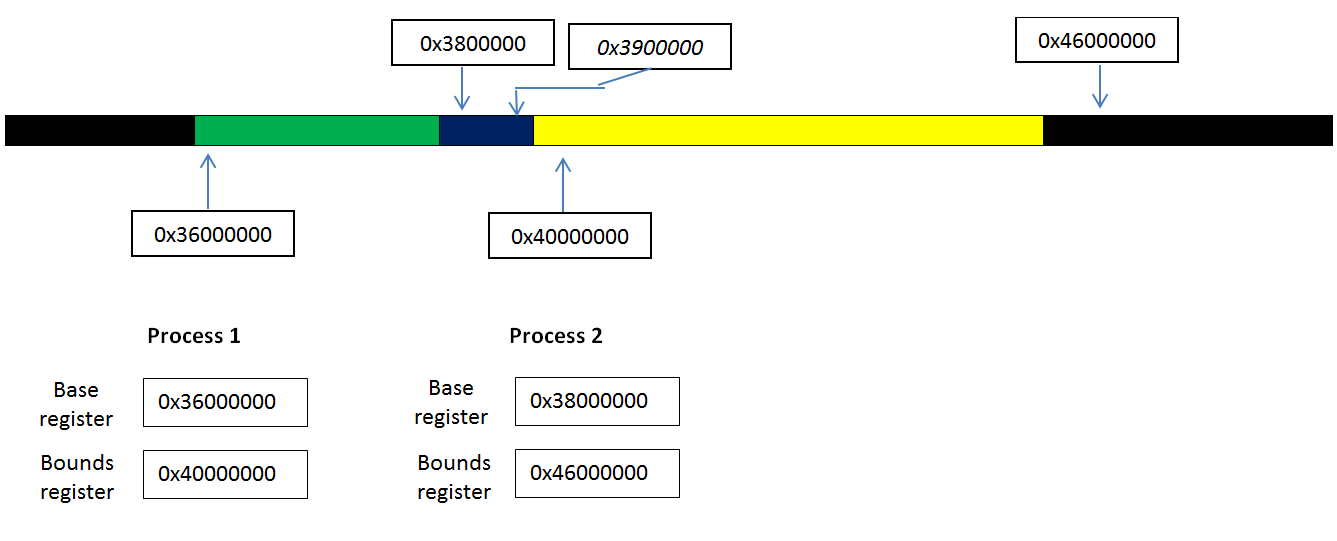
Thus, in order to allow multiple processes to access a particular piece of shared memory, we simply overlap their base/bounds pairs. However, with more than two processes but only a single base/bounds pair, a given block of shared memory cannot be shared while guaranteeing proper process isolation; there will be stretches of memory shared between two processes that shouldn’t be shared.
III. APPROACH 2: DOMAINS
However, we can approach this problem of shared memory by using multiple base/bounds pairs. Define a memory domain as a memory "start" address, a size, and a set of permissions; this is simply a small extension of our typical multiple-base/bounds implementation of memory allocation). In reality, a domain simply maps to three registers: the two "typical" registers for base and bounds address and a third permissions register. The allocations of such domains can be implemented as a system call: map_domain(size, perms). A given request for a domain will consist of a size and permissions, and it is up to the operating system to find the proper chunk of memory. Each process is allowed to have multiple domains as determined by the particular hardware.
The implementation of domains works the same as the previous implementation of multiple base/bounds pairs; the hardware will check each of the base/bounds pairs to validate every load or store. However, with the addition of "permissions" to a domain, the hardware will also check for appropriate access, depending on the context. If the domain is set with read permissions or write permissions, then loads or stores (respectively) will be allowed; the execute bit will allow jumps to occur into a particular domain.
Pseudo-C for load in domain implementation
char load(void *addr) { for (base, bound in base-bound-pairs) { if (addr >= base && addr < bound) { return *addr; } } throw memory access exception; }
Thus, a given process can allocate different domains with different permissions, in order to further prevent malicious code. The text of a program can be allocated into a read-only domain, while the stack of each process will be marked as read/write. However, a problem with using domains to implement memory reference protection is the vast number of domains a particular process could require.
Possible uses for domains include:
- text of a program
- data of a program
- heap
- stack
- I/O buffers
- memory
In our current implementation of domains, we only have a fixed number of base-bounds-permissions pairs, which is a number governed by the number of registers dedicated to these base/bounds values. The number of required domains can exceed the number of allowed domains, and the program will crash. Our next implementation will change our concept of domains in order to allow for a more dynamic range of memory.
ASIDE
Some permissions are unusual and left out in some hardware implementations. Permissions such as write-only or no-permissions (read/write/execute denied) have few applications to real-world code, and so not all hardware supports this. In fact, x86 hardware only supports read and write permissions and decided to forgo the execute bit, leaving the operating system in charge of the instruction pointer. However, this unfortunately makes buffer overflow attacks easy, since a given memory domain can be filled with arbitrary executions and then jumped to by a single instruction. More current x86 implementations enforce the execute bit in order to prevent these buffer overflow attacks.
IV. APPROACH 3: SEGMENTATION
The approach of segmentation "segments" memory into dynamically allocated blocks, and parcels out these segments to each process accordingly. Thus, the implementation of segments is very similar to domains, in that both divide up memory into a base address, bounds address, and permissions, but in segmentation each process gets its own segment table, which stores the various base, bounds, and permission information for each segment. When the operating system allocates a particular segment to a process, that process’s segment table is simply updated accordingly and a reference to that particular segment is parceled out.
In segmentation, memory "addresses" are neither pure relative nor absolute addresses; each "address" is composed of an index into a process’s segment table and an offset into that particular segment. Take the layout shown below, where a memory "address" is 64 bits, with 16 bits dedicated to the segment number and 48 bits to the offset. Because the segment number serves as an index into the segment table, this means the segment table must have 216 entries. Each entry contains the usual information: a base address, bounds address, and permissions for that segment. Individual segment size is limited by the size of a given offset; a 48-bit offset corresponds to a 248, which is equivalent to a whopping 256 TB of memory.
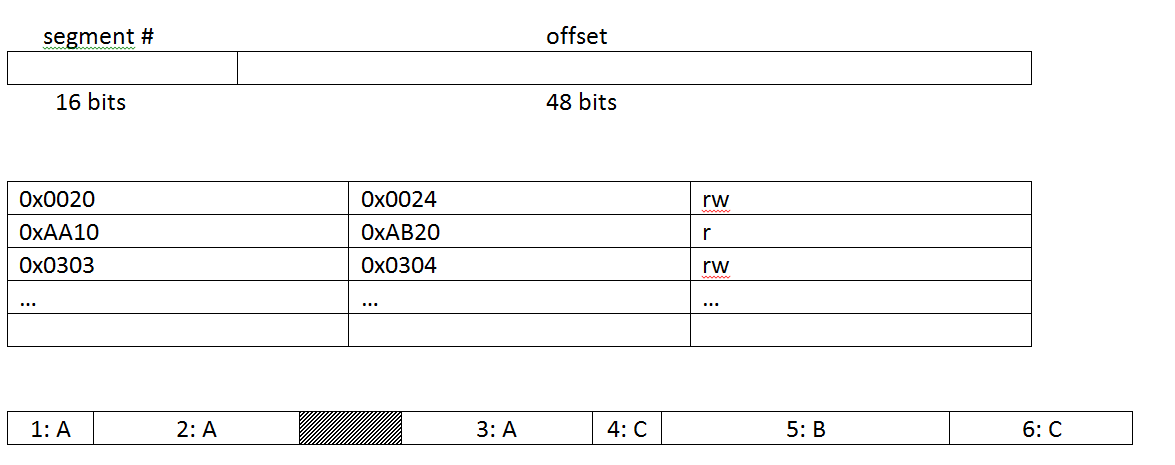
Note that the ability to change the segment table for a process is restricted; the memory address of the segment table can only be written over by a privileged process.
Thus, in segmentation, pseudo-code for a load with 64-bit memory addresses and 64-bit registers:
Psuedo-C for segmentation load
char load(void *addr) { uint16_t segmentno = (addr >> 48) & ((1 << 16) -- 1); uint48_t offset = addr & ((1 << 48) -- 1); if (current->segment_table[segmentno]->permissions include read) { return *(current->segment_table[segmentno] + offset); } throw memory access exception; }
However, a major problem with this implementation of segmentation is growing a segment. In the above example, imagine growing segment #4 that belongs to C; suppose this segment corresponds to C’s heap, and C gets repeatedly calling malloc(). While growing segment #2 would be as simple as changing the bounds value in the row corresponding to segment #2 in A’s process table, growing segment #4 in this manner would allow unsafe memory access. Just as in the previously mentioned RT-11 filesystem, we could move the various segments around to make room for segment #4 to expand, but this is cumbersome and slow. Because we allowed our segments to be of variable size, it becomes much harder to find a way to grow a particular segment.
V. APPROACH 4: PAGE-BASED MEMORY MANAGEMENT
The problems in segmentation arose because of the dynamic size of each segment, making growing and allocating segments to a process cumbersome. The next logical progression is to remove the dynamic size of a segment and simply make the size of every segment a constant number, determined by the operating system. This is the core of page-based memory management.
Let a page simply be the same as a segment with a constant size, i.e. it consists only of permissions and a start address -- the "bounds" address is not needed because of the fixed size of all pages. (In most Linux implementations, page size is set as 8 KiB). Thus, every memory address will correspond to a particular page and an offset. In the following diagram, 32-bit addresses were used, with 19 bits corresponding to a particular page number and 13 bits of offset into that particular page.

These types of addresses, split into a page number and offset, are known as virtual addresses, and these virtual addresses map to a particular physical address, which is the actual location into RAM.
This implementation is thus very close to segmentation, but differs in several key ways:
- Page sizes are typically much smaller than segments, while the number of pages is usually greater than number of segments.
- With segmentation, additional memory needs were handled by growing a particular segment; with pages, more pages are allocated to the particular process.
Thus, similar to a per-process segment table, page-based memory management requires a page table to map virtual addresses into physical addresses. This page table will translate a virtual page number (VPN) into a physical page number (PPN). VPNs are unique to each process, while PPNs are unique to the hardware. Once the physical page number is obtained, the given virtual address’s offset can then be used to appropriately offset into this physical page.
One benefit of page-based memory management is that the size of the actual physical memory is "hidden" from processes by this page table; indeed, the size of the virtual memory address space (219 bytes in the above case) does not have to be equivalent to the size of the actual physical memory. The hardware simply translates one to another, and as long as the page number is valid, a valid physical page number will be returned. However, for the following examples, we will assume that the virtual and physical address spaces are equivalent, for simplicity.
Assuming 32-bit virtual addresses with 19 bits for page number and 13 bits for offset, each page table will need 219 rows, since the VPN is used as an index into the page table. This will translate each 19-bit VPN into a 19-bit PPN, with the offset remaining constant. Thus, each row needs to be a minimum of 19-bits, but to preserve memory alignment these rows are usually expanded to a full 32 bits. This enables the storage of parameters, dirty bits, and various other metadata about a particular page.
Psuedo-C for a load in page-based management:
int pmap(int vpn) { return (PAGE_TABLE[vpn]) & ((1 << 19) -- 1); } char load(void *addr) { int vpn = (addr >> 13) & ((1 << 19) -- 1); int offset = addr & ((1 << 13) -- 1); int ppn = pmap(vpn); /* check for read permissions as well */ return *(ppn * PAGE_SIZE + offset); }
Because page tables consist of 219 rows of 32 bits each and are assigned per-process, each process will receive a 2 MiB page table. This number can become troublesome. Consider an old machine with 128 MB of RAM; the page tables alone of 64 processes will fill up the entire memory space. No matter how much memory a process consults, it receives this 2 MiB page table; if it does not address much memory, the page table will be largely sparse, and the majority of the rows will be filled with zeros (unused).
In order to alleviate this problem of page tables being too large, we can use a similar structure to filesystems and use multi-level page tables. Consider a "2-level" page table, in which a virtual address now consists of two page numbers and an offset (as pictured):

One page number (pageno_hi) will be used to index into a top-level page table, which, instead of mapping to a physical page number, will map to the address of a second-level page table. The 2nd page number from the virtual address (pageno_lo) will then be used to index into this second-level page table, which will contain the expected physical page number and its associated metadata (permissions, etc.). These second-level page tables are allocated "lazily"; initially each process has an empty top-level page table, and only as pages are requested second-level page tables are allocated and updated. The size of the virtual address space remains the same (219 bytes), but the amount of memory allocated to page tables is decreased.
With a 10-bit pageno_hi, each top-level page table will be 210 rows, and, since rows are 4 bytes each, each top-level page table will occupy 4 KiB -- a huge decrease from the original 2 MiB page table. Each second-level page table is only 29 rows of 4 bytes each, making each second-level page table 2 KiB. Since these second-level page tables are only allocated when needed, there is a very slight overhead incurred, but the memory usage of each process is vastly decreased.
Pseudo-code for the modified pmap in a 2-level page table implementation:
int pmap(int vpn) { int hi = (vpn >> 9) & ((1 << 10) -- 1); // upper 10 of 19 int lo = vpn & ((1 << 9) -- 1); // lower 9 of 19 bits void *p = PAGE_TABLE[hi]; if (!p) return 0; // error catching return p[lo] & ((1 << 19) -- 1); }
Because the virtual and physical address space do not have to be equivalent, the operating system kernel has the ability to "lie" to the process by blocking out regions in a process’s page table as being used, even when no physical memory was allocated. Consider a program that requests a large amount of memory, like 3.5GB. Due to a shortage of physical memory, the operating system can only allocate 1.0GB in pages normally and then mark the remaining 2.5GB as used (mark with 0) in the process’s page table, without assigning any physical page numbers. The process thus believes it has a 3.5GB range of memory. However, we need to be able to deal with the program accessing part of the 2.5GB range, when no main memory has been allocated for it.
VI. SWAP SPACE
Swap space can be seen as an extension of physical memory, in that virtual memory can map to data stored on some kind of secondary storage (typically a hard disk) when physical memory runs low. In the previous section, we marked off a portion of a process’s page table as used, when in fact there was no physical memory backing it. Whenever a process will try and access some of this marked portion, the kernel will take a "victim" page of physical memory, copy it to disk, and then erase this page in memory. The accessing of a "marked off" page is known as a page fault.
If a page is part of this "marked off" section and is attempted to be accessed, the hardware sees a 0 in the page table, thinks it is simply a bad memory access, and will trap into the kernel. At this point, if the kernel deems the page being accessed as valid, the kernel will pick a "victim" page to swap with the requested page on disk. The kernel will copy this victim page to disk and then copy the initially requested page from disk to main memory. The page tables of both the current and victim processes will be updated, and then the memory access will be retried. This time, the requested page is in main memory, and execution should continue as normal.
Pseudo-C for managing a page fault:
void pfault(int vpn) { // swapmap takes a VPN and process and returns a pointer to a region // on hard disk that should contain the data for the requested page if (swapmap(vpn, current_process) == FAIL) { kill(current_process); } // we have a valid page number that wasn’t in physical memory // pick a page in physical memory to swap out to disk (victim_process, victim_vpn) = removal_policy(); // determine the physical page number of the page we’re swapping out int victim_ppn = vpn2ppn(victim_process, victim_vpn); // mark the page in the victim as paged out in victim’s page table setppn(victim_process, victim_vpn, FAULT); // get a pointer to the victim’s page in main memory void *victim_data = ppn2data(victim_ppn); // get a pointer to where on disk we’ll be writing void *disk_target = swapmap(victim_vpn, victim_process); // copy victim’s page to disk write(victim_data, disk_target); // get a pointer to where on disk we’ll be reading the requested page void *disk_source = swapmap(vpn, current_process); // read into victim_data, which is the page we just swapped out read(disk_source, victim_data); // update the current process’s page table with the location of the newly read page setppn(current_process, vpn, victim_ppn); }
ASIDE
What if the victim selected in pfault is the location of the memory manager itself? This would page out itself and would crash the operating system. So, pages belonging to the memory manager are wired down, which means they are invulnerable to paging out. In addition to the memory manager, the top-level page table is wired down as well, since it would not make sense to page out the memory that keeps track of pages. Second-level page tables, however, can be victims.
VII. TUNING VIRTUAL MEMORY PERFORMANCE
- Demand paging: when you start a particular program, load only its first page of text/data. If a program is particularly large and its text/data portions required multiple pages, only the first page can be loaded, and accessing of subsequent pages will page fault. This increases startup speed, since only a single page is loaded initially, but it only pushes the loading of the rest of the pages until later. Performance can degrade if disk arm moves around more, which is especially likely with multiple processes starting simultaneously.
- Dirty bit: by storing one bit per page to mark it as "dirty", the operating system can track when a particular page is inconsistent from its copy on disk. If a page is not modified and is being swapped out, then the write to disk can be skipped, and performance will increase.
A naïve implementation of the dirty bit would set the dirty bit to "dirty" for every store into the page, but this entails two hardware writes for each requested write. One way to do this is to clear the "write" bit in the permissions for a page when loading it from disk into main memory. This way, the first attempt to write into this page will trap into the kernel, and the kernel can take this opportunity to flip the dirty bit. The page will then be marked as modified, requiring only a single write.