-
Client:
-
package("Casablanca",hd)
-
setup_ID (hd, server add)
-
sent (hd)
-
receive()
CS111 Operating Systems (Winter 2013)
Lecture 15: Virtual Memory and Distributed Systems
Note Takers: Yiqi Yu & Yang Lu
Table of Contents
Virtual Memory
Memory hierarchy
- Registers -> fastest, want to use this as much as possible
- L1/L2 Cache
- RAM
- Disk/SSD
- Backup (slow disk, tape, network disk) -> slowest
In the above hierarchy, each level has a caching problem. Our focus is on the problem of caching disk data into RAM.
Question: Which part of the disk should we put into RAM now?
Remark: This question is a general policy question, so we should be able to answer it independently of the choice of hardware.
Recall that
1. RAM can be thought of as a cache for a much larger disk where the memory of the program actually resides;
2. When a program tries to access a virtual memory address that is currently not (cached) in RAM, it needs to throw an exception and gives control to kernel to load the physical page. This is called a page fault;
3. The page table maps virtual addresses to physical memory addresses.
Normally a page fault happens when all the virtual pages are utilized. In this case the kernel will have to find a victim page to replace.
The victim page it chooses should be one that is not needed at the moment.
Pick the Victim: Removal Policy
There are a couple of removal policies. But before proceeding, let's consider why the choice of removal policies matters.
Suppose we have random access to virtual memory
Which page should we pick? The answer is, since any page can be accessed next with equal probability (this is what makes the access random), it doesn't matter which page we pick. So we can just pick the first page! That is, removal policy is not an issue here, since we are not better off no matter which policy we adopt.
However random access to virtual memory is extremely rare in practice, since you typically see locality of reference, i.e., memory is often accessed in some previously accessed area.
So let's get into the real world.
Suppose we see locality of reference
We will consider several heuristics here: FIFO, LRU, etc.
First In First Out (FIFO)
If FIFO is implemented, the page that has been in RAM the longest will be removed.
Note that FIFO makes sense since the page that has stayed longest in the memory is probably what the program has lost interested in.
Or does it?
To evaluate how well an algorithm works, we want to run it on lots of applications. For purpose of simplicity, we don't run the entire program here. Instead, we get its reference string and see how well the algorithm performs on the given reference string.
A reference string is a series of virtual page indexes that the program requests on the fly. Using this log we can simulate the behavior of the page table using many different removal policies. The best policy will be the one that minimizes the number of page faults.
For example, suppose we have 5 virtual pages in virtual memory and 3 physical pages in our very small machine. Then "0 1 2 3 0 1 4 0 1 2 3 4" is a reference string. The program makes 12 access requests at run time. At t0 it requests virtual page 0. At t1 it requests virtual page 1, etc.
The following is a simulation of FIFO on the sample reference string with A, B, C being the physical pages. In this example and the ones that follow, bold cells indicate page faults. The policies will be compared based on the total number of page faults that occur in the simulation of this particular string.
It is clear how FIFO handles page swaps if we look at the 5th column. The program wants to access virtual page 3 but at the moment it is not loaded in the physical memory. Among the 3 virtual pages 0, 1, 2 that are loaded, page 0 has stayed the longest, for 3 time units. So we load page 3 into A where virtual page 0 resides.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
| B | - | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 2 |
| C | - | - | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 3 | 3 |
Total page faults: 9
In the example we see that in a total number of 12 requests, 9 page faults have occurred. This is terrible. We definitely want to shrink the number of page faults!
Let's try to increase the amount of RAM. We will now simulate the same reference string using FIFO, but with four physical pages of RAM.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 3 | 3 |
| B | - | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 4 |
| C | - | - | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
| D | - | - | - | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 |
Total page faults: 10
Usually with more space we expect performance gains. But here quite counter-intuitively, we see an increase of page faults even though we now possess more memory. This phenomenon is called Belady's Anomaly.
Fortunately Belady'sAnomaly does not happen that often in practice, but it is possible with FIFO.
Next we let us attempt to come up with a software solution (HW solutions are dumb…). That is, we seek a better algorithm that decides which page to replace. But with this next algorithm, we would like to have more information about references to improve performance. We might think that if somehow magically we can predict the future i.e., know what the entire ref-string is, things will be much easier. This might sound too good to be true, but let's see how well things work out under this assumption.
Furthest In the Future (Input: the entire reference string given by an Oracle)
The algorithm removes the page that won't be needed for the longest amount of time. Again we simulate the algorithm on the same string.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 3 | 3 |
| B | - | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| C | - | - | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 |
Total page faults: 7
For example, when the program requests page 3 for the first time (5th column), it sees that page 3 is not in RAM. Comparing 0, 1 and 2, we see that 0 and 1 will be immediately used, but page 2 won't be needed until the 10th request. So we load page 3 into C where page 2 currently resides. The total number of page faults in this case is 7, improved from 9 when FIFO is used.
After a moment of thought, one realizes that this algorithm achieves the optimal performance. However, it is rare that the kernel has the foreknowledge of future memory accesses.
Side note: in what part of memory hierarchy could we assume that we have an oracle?
Answer: The compiler sees the whole chunk of instructions and decides which variables to store in registers in compile time.
Since an oracle is good but not possible in most cases, we would like an approximation to an oracle. The next algorithm is based on this idea.
Least Recently Used (LRU)
When running LRU, the page that was least recently used would be chosen as the victim page. The idea is that the future might resemble the past. So the page that was requested the least will probably not be requested often in the future as well. This is clearly not a reliable assumption, but it turns out that LRU works well in practice. Again an example helps us see how it works.
| 0 | 1 | 2 | 3 | 0 | 1 | 4 | 0 | 1 | 2 | 3 | 4 | |
| A | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 | 4 | 2 | 2 | 2 |
| B | - | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| C | - | - | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 4 |
Total page faults: 10
Note that in the 11th column, when the program requests page 2, the kernel sees that page 0, 1, 4 are currently in RAM. Page 1 was just accessed and page 0 was accessed immediately before that. So an LRU algorithm will replace page 4 loaded in A. In the end, 10 page faults have occurred, which is worse than FIFO. This shows that LRU indeed relies on a vulnerable approximation scheme. Nevertheless it is better than FIFO in normal cases.
LRU is more complicated than the previous heuristics in that it requires the kernel to have a way to know how often a particular page is accessed recently.
Intuitively, we would like to add an N-bits field to each entry in the page table, counting the uses of that page, as the picture below suggests. Of course the kernel will need to refresh the field every now and then. Alternatively, we can store a timestamp in the field which tells the kernel exactly when the page was last accessed. However, these solutions are too inefficient as they require the page table to be a lot larger. They also slow down memory accesses as we need to write a timestamp into the page table every time we access memory. Moreover, they are too complex for the hardware guys…
page table
|
page# |
count uses |
|
→N bits← |
We want a simpler solution. Say let N=1. Initially all fields are set to 0, which means the page is inaccessible. So a page request will incur a page fault, after which the field is set to 1, which means the page has been requested at least once. When we need to replace a page, we pick randomly from the table as long as the victim has its field value equal to 0. Every so often, the bits are reset to 0, so the algorithm can continue. For example, suppose at time t the table looks like the following:
| A | 0 |
| B | 1 |
| C | 0 |
| D | 1 |
| E | 1 |
Since the first and third entry has the last bit = 0, the kernel will pick one of these 2 pages.
Remark: This solution is clearly too simplistic as an approximation to LRU implementation. But as engineers we often have to make trade-offs between effectiveness and other metrics. In this example, we choose to have the desired functionality implemented at its bare minimum but nonetheless save up valuable resources.
Disk Request Scheduling
A disk can be viewed as an array of pages.

We need a model to evaluate the cost of I/O instructions. Here is a simple one. We mark the beginning of the disk as position 0 and the end of the disk as position 1. We further assume that cost of an I/O instruction is proportional to |i-j|, the distance between positions i and j.
Suppose disk accesses are random, then if the header is at the start of the disk, the average cost would be proportional to 0.5, or just 0.5 for simplicity. If the header starts from the middle, the average cost is 0.25, for the request will be on the left side of the header with probability 0.5 and the average distance given a request is on the left side is 0.25. The average cost 0.25 is obtained by doubling the average cost of requests appearing on one half of the disk.
To calculate the average cost in general, we need to recall calculus:
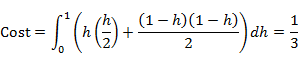
But we were assuming we handle disk requests in a first come first serve (FCFS) basis. However in practice, we will often have several outstanding I/O requests. Note that this is valuable information as we can see it as a small fraction of an oracle. In scenarios like this, there are several scheduling heuristics available to consider.
Shortest Seek Time First (SSTF)
Description: Say the disk head is now pointing to page i. We have outstanding requests {1,2,…,n}. The next page we will handle is the request that is waiting and has its page number closest to i.
Advantages: SSTF is especially good at achieving high instant throughput.
Downsides: Starvation is Possible.
Imagine that 2 processes keep sending requests that are close to the head. The head then is kept just busy dealing with requests from these two processes, ignoring other requests that arrive much earlier. To understand this, think of an elevator analogy. You are in an elevator which is currently on the 5th floor. On the 4th and 6thfloor, there are people pressing the button. On the 10th floor, there is also a person pressing the button. Suppose the elevator uses SSTF and the number of people on the 4th and 6 th floor is large enough(and unfortunately every newcomer will press the button once just in case other people haven’t), then the elevator ends up coming up and down between the 4th and 6th floor, never going anywhere else.
Elevator Algorithm
Intuition: Because of the analogy described above, a real elevator never uses pure SSTF. We can implement our read head to behave like a real elevator.
Description: Same as SSTF, except that the head stays in the same direction if possible.
Advantage: solves the starvation problem
But it has its downsides:Firstly it has lower throughput than SSTF.
More importantly, it is unfair. Suppose you are a process. Which part of the disk do you want to send your requests to? Since the middle of the disk is visited more often than the ends of the disk by the read/write head, a process takes advantage against others if its request is sent to the middle.
Side note: Some OS actually implements mechanisms that encourage processes to send requests in the middle!
Circular Elevator Algorithm
Since Elevator Algorithm is unfair, we want an algorithm which solves starvation as Elevator Algorithm does and is also fair.
In Circular Elevator Algorithm, the head always handle requests in one direction, but when it reaches the end of the disk, it immediately seeks back the start of the disk and then continues.Note that the throughput produced by Circular Elevator Algorithm is even lower than by Elevator Algorithm, but it is tolerable as we prefer the extra fairness to its cost.
Combination of SSTF and FCFS
Description: Suppose the outstanding requests are stored in a request queue. Let a "chunk" of requests be the first k requests in the queue. The kernel always pops a chunk off the queue, and then applies SSTF scheduling on that chunk before proceeding to the next chunk. This way we enjoy the throughput due to SSTF and also avoid starvation.Distributed Systems & Remote System Calls
Until now, we have focused on virtualization to enforce modularity. Now we shift our attention to another approach: distribution.
The Client-Server Architecture
In a distributed system, a server and a client play the analogous role of the kernel(callee) and user code(caller) in virtualization respectively.
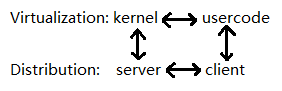
The main difference is that the caller and the callee are physically separate in distributed systems, and therefore don't share the address space. One good thing about this is that we get hard modularity for free. The downside is that data transfer is much slower.
A more subtle implication is that call-by-reference does not make sense when the client makes a function call to the server. Since they don't share address space, the address passed by the client is garbage from the server's point of view. So instead of call by reference, the client is forced to use call-by-value, call-by-result, etc.
The caller and callee may also disagree in computer architecture. For example, the floating point format, integer format, width of integers might differ from one machine to the other. So we must be careful with the interactions among members of the system.
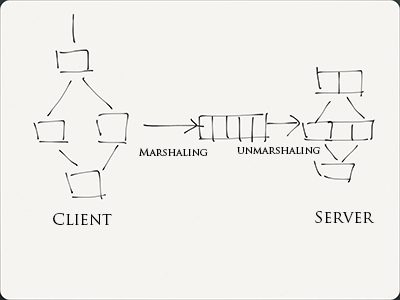
To solve the issue, we have to come up with a protocol that specifies how data are represented in the wire, so that the client and server have expectations of how to pack and unpack datagrams when sending or receiving data. For example, we can use "32-bit big-endian 2's complement" as a format for integers.
In presence of a protocol, each process has to package, or marshall the data before sending and unpack, or unmarshallthe data that arrive. As the figure shows, marshaling is a procedure where the data "get in line" on the wire; unmarshalingis a procedure where the data assemble according to the server's data structure. It is entirely possible that the resulting data look structurally different from the original data
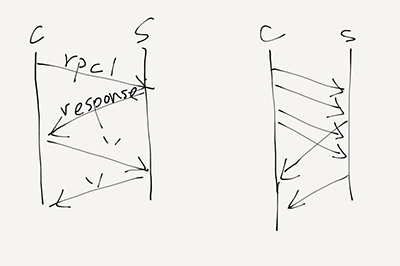
Remote Procedure Call (RPC)
The most common client-server communication pattern is Remote Procedure Calls or RPCs in short. They differ from ordinary function calls in that one machine makes the call(request) to a remote machine and waits for the result(response) to come back.
From the client's point of view, however, RPCs look like an ordinary function call. The following pseudo-code for an RPC is what a client executes. It asks a remote server (e.g., located in Europe) what time it is in Casablanca. The server on the other side must have a corresponding procedure that handles this type of request.
-
Client:
-
time_t t = tool ("casablanca") //client code
-
Server:
-
tod(char* loc){
-
/*fancy code here*/
-
return 1093726317;
-
}
We omitted the server code since the same idea, i.e., package/unpacke before doing real work applies to the server as well.
As programmers, we may find this constraint makes coding more tedious and error-prone. For this reason, in practice, the packaging codes are usually automatically generated.
What can go wrong with RPCs?
RPCs can go wrong in a number of ways because data transfer is not reliable.
1. Messages can be corrupted. Note that corruption may happen in virtualization too. It's just less often than in distribution. A common solution is to add checksums to detect errors.
2. Messages can be lost.
3. Messages can be duplicated.
For example, a student may understandably want to delete the specification of lab5 in the professor's home machine. He makes an PRC call to the professor’s remote machine.
unlink ("home/eggert/hw5.txt")
But the problem is that he may never hear back from the server, because either the request or the response can be lost on the wire. What should a client do when it detects a possible loss of messages?
At least once RPC: The client can keep trying sending requests if it does not hear back from the server after a set period of time.
At most once RPC: The client simply returns an error (e.g., errono = ESTALE) to indicate that something may have gone wrong. (Note that even if the response does not come back, the client may have successfully deleted the file on the server).
We would certainly want an approach which is "exactly once RPC", but in principle it is just too hard to achieve.
What's the catch?
The client has to wait for a response to come back before sending the next request. If the number of requests is large, RPCs can be quite slow because of this. To circumvent the issue, the client may want to send multiple requests at a time. In this case, we don't have a call-and-return pattern with ordinary function calls anymore, but something fancy like call-call-call-call-wait-return-return-return-return...
More things about RPCs will be talked about next time.