General Memory
Caching Policy
Memory Hierarchy
- registers ← want to use this mostly
- L1 cache
- L2 cache
- RAM *
- disk or SSD *
- backup (slow disk, tape, network disk)
*we will look at these
RAM and Virtual Memory
Which part of disk should we put in RAM?
- policy question, can be answered somewhat independently of Hardware (HW)
- Came up at the end of previous lecture
- Which page should be the victim?
- if you can answer this question at any time, then you’ve solved a lot of the issues of policy and can answer questions about performance
- Suppose we have random accesses to virtual memory (lives on disk if too big)
- we choose small parts of disk to go into RAM. We need to fit more, but what should we write to virtual memory? (victim)
- pick the first page, since it doesn’t matter (you can pick any page)
- however, (1) is rare in practice – you typically see Locality of Reference
- Suppose we have Locality of Reference
- lots of heuristics
- simple one: FIFO == pick page that has been in RAM longest
- way to check how well FIFO works is to run it on lots of apps: get their reference strings (list of pages in order each was needed)
- suppose we have 5 virtual pages, 3 physical pages
reference string: 0 1 2 3 0 1 4 0 1 2 3 4 - -pull 0 1 2 into memory: physical memory full
-replace 0 with 3, replace 1 with 0, etc.
(use * for page faults)
9 page faults0 1 2 3 0 1 4 0 1 2 3 4 A 0* 0 0 3* 3 3 4* 4 4 4 4 4 B ? 1* 1 1 0* 0 0 0 0 2* 2 2 C ? ? 2* 2 2 1* 1 1 1 1 3* 3
buy 1 more physical page, we get:
10 page faults!0 1 2 3 0 1 4 0 1 2 3 4 A 0* 0 0 0 0 0 4* 4 4 4 3* 3 B ? 1* 1 1 1 1 1 0* 0 0 0 4* C ? ? 2* 2 2 2 2 2 1* 1 1 1 D ? ? ? 3* 3 3 3 3 3 2* 2 2
Belady’s anomaly: more memory, but slows program (happens very rarely)
- if you have an oracle that knows the future reference string, what’s the best policy?
7 page faults0 1 2 3 0 1 4 0 1 2 3 4 A 0* 0 0 0 0 0 0 0 0 2* 2 2 B ? 1* 1 1 1 1 1 1 1 1 3* 3 C ? ? 2* 3* 3 3 4* 4 4 4 4 4
registers actually have something like oracle!
- approximation to an oracle: LEAST RECENTLY USED (LRU)
10 page faults! LRU doesn't work well with this reference string0 1 2 3 0 1 4 0 1 2 3 4 A 0* 0 0 3* 3 3 4* 4 4 2* 2 2 B ? 1* 1 1 0* 0 0 0 0 0 3* 3 C ? ? 2* 2 2 1* 1 1 1 1 1 4*
However, LRU usually works better than FIFO- mechanism for LRU?
- Use hardware to store store clock values, using N bits → HW guys don't want to
- Way to simulate without HW help?
- use N=1; initially set pages to inaccessible (r), will get page faults → set those pages to rw (set bit=1)
- choose one of the 0’s as next victim (means it wasn’t used recently)
- (reset clock values every so often)
- mechanism for LRU?
Paging to Hard Disk
The read/write head is relatively cheap to access ⇒
- simple model: cost of I/O is proportional to distance → cost ∝ |j - i|
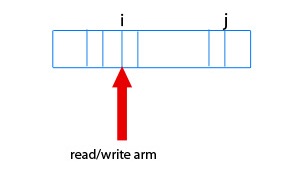
- suppose accesses to disk are random then average cost of an I/O is →
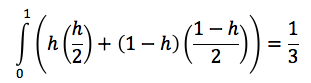
(assuming FCFS)
In reality, the OS has several requests outstanding (a bit of an oracle)
Disk Reading Algorithms
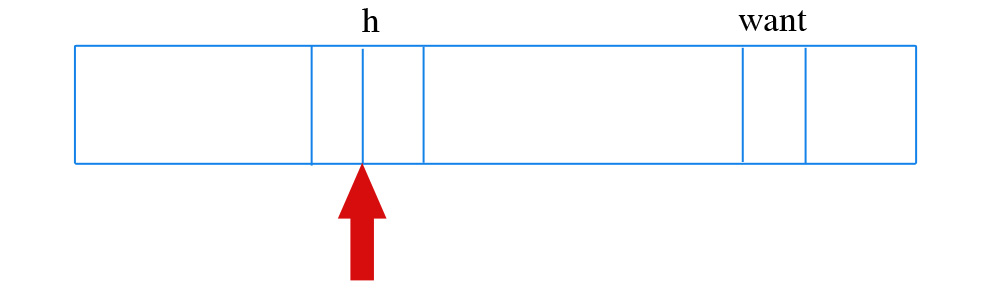
- Shortest Seek Time First (SSTF) → tempting to do work where head already is (h): cheapest
+ maximizes throughput
– starvation possible: while moving head, get another request nearby - Elevator algorithm: SSTF, but stay in the same direction if possible
+ no starvation
– not fair to ends of the disk (middle has least average wait time) - Circular Elevator Algorithm: at end of disk seek to lowest numbered request
+ fair
- additional time to seek from end to beginning - SSTF + FCFS: have request queue, take a chunk and serve that chunk in SSTF then take next chunk
Distributed Systems
- Until now for around 1/2 of the course, we've been talking about virtualization and using virtualization to produce systems
- Another approach is to use distribution.
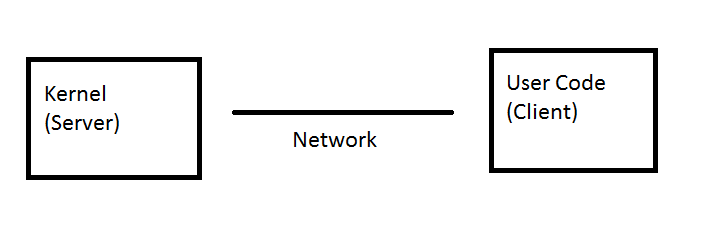
- The caller (client) and callee (server) don't share an address space
+ A distributed system provides hard modularity for free
- Data transfer is less efficient
- Hard modularity means that you can no longer make calls by reference
- Example you may no longer: "read(fd, buf, bufsize)" between client-server
- The caller and callee can disagree about fundamental formats such as:
floating point formats, integer formats, big endian vs little endian, or width size
- Another important thing to consider is that the network protocol must specify data representation on the wire :
e.g: 32 bit big-endian, 2's complement for floating points
- A process called marshalling and unmarshalling is used to resolve differences in data representation
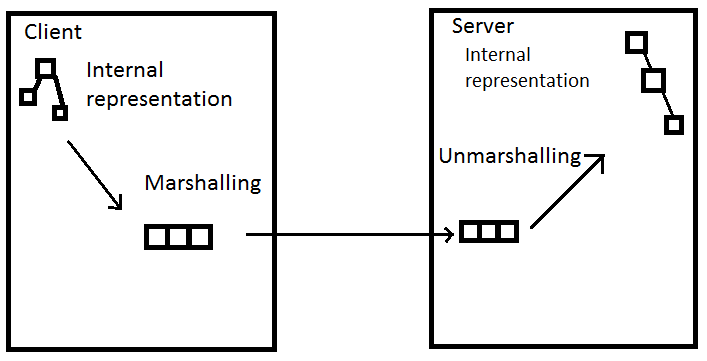
- A common client/server pattern to do this is Remote Procedure Call (RPC)
Remote Procedure Call
- A Remote Procedure call looks like a function call at the client
e.g: we call time_t tod("Casablanca")
- We want our tod function to look like:
time_t tod( char* loc) {
//fancy code to calculate the time
return some_time
}
- However the actual code will look more like:
client code: {
package("casablanca", hd)
setup_IP(hd, serveraddr)
send(hd)
receive()
}5
- The server code will also be similar to this
- Doing this is tedious and error prone, especially if you have lots of functions
- Luckily this process can be automated by programs that handle all of the marshalling and unmarshalling
What Can Go Wrong with RPC
- Messages can become corrupted (RAM suffers from this too), solved by adding a checksum to the packet
- Messages can be lost or dropped
- Messages can be duplicated
- Suppose the client sends "unlink("/~/foo/hw5.txt")", and the client never receives a response, then:
1) Keep trying (100ms timeout), This implements At Least Once RPC
2) Return an error, This implements At Most Once RPC
3) Hybrid, try a couple of times then return error
3) Just try once, This implements Exactly Once RPC
Example of a RPC protocol
Example: X window Protocol
"pixrect on wheels"
- The X window protocol basically draws pixels to a screen using the RPC protocol
ex: client: draw_pixel(x,y,r,g,b)
- The setup for Professor Eggert's X server looks like this:
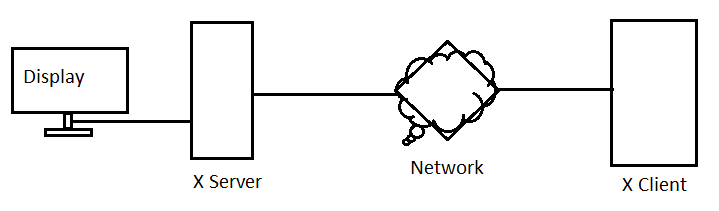
- So what happens if we want to draw lots of pixels at once ?
- Well we could send each pixel at once, wait for a response, however this causes too much delay
- Instead we want to send lots of requests simultaneously
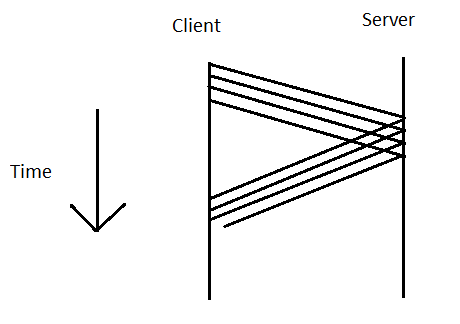
- We'll get lots of responses back, they could even be in the wrong order, but this doesn't matter