When talking about NFS security, a typical setup is an NFS client and NFS server that communicate to each other over a network. There are a few general methods in which a malicious client can attack a server.
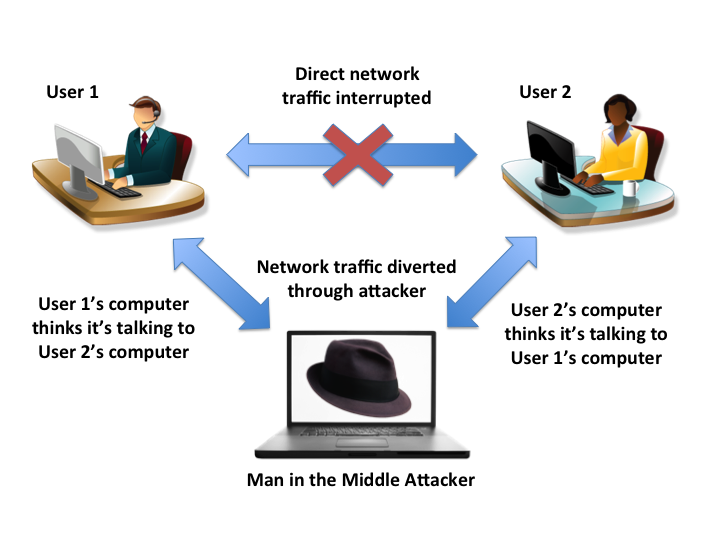
A Man-in-the-Middle (MITM) attack is when network traffic between two computers, call them A and B, that normally travels directly each other and instead reroutes traffic of both A and B to the attacker. In general, a MITM attack does not have to be between a client and server and can happen between any two computers. At this point, the attacker has a few options which he/she could do with this power:
MITM uses a technique called ARP (Address Resolution Protocol) spoofing in order to execute the attack. ARP spoofing works by faking the ARP table of a network's router into associating the attacker's MAC address (a network card hardware identifier unique to each card) with an IP address in the router's local area network. For example, if an attacker associates his MAC address with the local IP address 192.168.1.10, then any message destined for that IP address is rerouted to the attacker.
MITM attacks often occur in public locations with unsecured network communications. Some examples would be libraries, cafes, and other public locales with free Wi-Fi.
Some ways to prevent MITM attacks:
Using private networks is the most popular choice today, mainly because this was the first solution for protection and because it's cheaper to implement.
Assuming there's no snooping going on, an attacker can pretend to be a valid client by spoofing their user idea. Many NFS servers identify clients through their user ids and not their usernames. So even if an attacker's username is different, if the IDs match then the server could mistake the attacker for someone else. For example, the school chancellor's ID could be 1009 but the attacker could also have the same ID can gain access that way. Some solutions to this:
Finally, an attacker can pretend to be a server. A clean user would communicate with the attacker, and the attacker can sniff the information the user sends in order to gain valuable data like username, password, etc. In addition, the attacker could also send malicious data back to the user.
In the real world, security is used mainly to combat:
Likewise, typical security in cyberspace mainly involve protecting:
How hard is it to test these goals?
The takeaway is that positive testing (what you want to allow) is much easier than negative testing (what you don't want to allow).
In order to design a security system, you must model the system that you are trying to protect and what all the components are that need to be accounted for:
Of course, threats are the hardest to identify.
What are some of the most common threats that can be identified off the bat?
There are some constraints that need to be taken into consideration when designing a security system:
There are two major ways to access resources:
Direct: Access by mapping directly into the address space and use ordinary loads and stores. Each access is checked by ahrdware rules. When you get a fault, the fault handler (which is typically under software control) can do much more fancy things to deal with the faults. For example, the function
char *p = mmap(fd, offset, etc...)
creates a pointer directly into virtual memory.
Indirect: Service requests via handles. Handles are opaque objects. Each request is handled by software, and you cannot access files directly. For example,
fd = open (file, ...) read (fd, ...)
This accesses the file through its file descriptor, not the file itself, a method of abstraction.
In a fairly straightforward way to control permissions, we can store permissions by using a large 3D boolean array with the users, files, and permissions in the x, y, and z axes, respectively. The 3D boolean array would work like this:
for each user for each file for each type of access permissions allowed (boolean true) or disallowed (boolean false)?
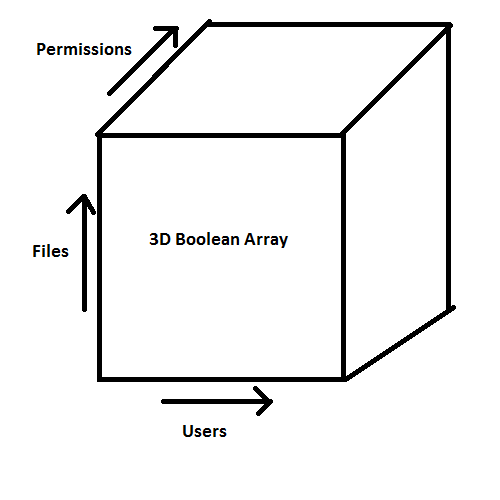
Though this would work, it would take a giant array in memory and it's just not very efficient. An access control list compacts this cube in this way:
for each file list of user permissions
This essentially attaches a list of permissions to each file. For example, a file called "foo" could have something a permission like (Bob, read) which would give permission for the user Bob to read the file, but nothing else.
ACLs are an example of an effective authorization model, but it is not the only one. We want the model to fit with the needs of the system. Some needs could be capturing rights accurately or letting ordinary users specify rights. ACLs in general are not flexible enough for large organizations. A better model would be role-based access control - though this model is more complex but more secure than ACLs.
Role-based access control (RBAC) has to keep distinction between users and their roles. For example, the user "eggert" could have multiple roles assigned to him:
Each role would constrain eggert to specific tasks. As a cs-faculty, he could change grades. As a sys-admin, he could make changes to other users' permissions. But these permissions are usually mutually exclusive. There could sub-roles. For example, a role could be "faculty" and sub-roles could be "cs-faculty" and "english-faculty". cs-faculty and english-faculty could have some mutual permissions because they both belong to the faculty role but could also have mutually exclusive permissions that apply only to their sub-roles.
ACL and RBAC: each file lists permissions for each user
Capabilities: Each descriptor lists permissions! Multiple descriptors could point to a file, but each of these descriptors would have their own separate permissions. Example:
fd = open ("abc", O_RDONLY) <--- code
r-- rwx <--- permissions
read-only read, write, execute <--- description of permissions
This means that the file "abc" has the permissions rwx attached to it, but opening the file and obtainng the file descriptor fd means that any action done with fd can only read the file it points to and nothing else.
What if instead of O_RDONLY, the argument was O_PATH? O_PATH essentially gives no permissions, it only shows the existence of a file that fd points to. What can you do with this fd? You could duplicate the file descriptor using dup or dup2, but then you'd have 2 useless fd's instead of 1. What would be useful is to run:
fstat (fd, dst)
fstat would be able to return information about the file that fd points to, and that would definitely be useful in some cases.
This is possible. Capabilities are essentially inverted file permissions. Some things you can do with capabilities:
You could forge capabilities, but this could be solved using encryption.
When you type "ls -l" in the UNIX command line, you can see your permissions for the files in your current directory. We could see something like this:
-rwxr-x-r-x
So far this seems normal each character in this permission is essentially a bit that represents a permission. If that bit is 0, it is represented by a '-'. If it is 1, then the character representing what it stands for appears, such as 'r' or 'x'. However, some permissions can look like this:
-rwsr-xr-x
Wait, that 's' appeared where 'x' used to be! Weren't there only two modes in that slot - whether or not to give permission to execute? It turns out there are an extra 3 hidden bits to the left of the ACL - these 3 bits enable/disable "setuid", "setgid", and "sticky":
setuid in particular can be dangerous if the file's owner is root because then they can do anything. setuid is not all dangerous and has its uses. For example, it allows a user to change his/her own password so root doesn't have to log in everytime a user wants to change passwords.
setuid does not blindly run everything as root if the owner of a file is root. Some dangerous uses have been specifically programmed against. For example say a user does this in the command line to the passwd program:
$cat > passwd.c $cc passwd.c passwd $chmod root passwd $chmod 4755 passwd
These commands tries to create a copy of password and run it as root. However, this fails because this in fact does not run as root and there are special security measures against it.
There are certain processes and programs that a computer system must be able to run with no hinderance or can misbehave without affecting security. This set of software and hardware is called the trusted computing base. It must resist tampering and be as small as possible so it's manageable and reduces the appearance of security vulnerabilities. Some examples of trusted code:
In the paper "Reflections on Trusting Trust" by Ken Thompson, one of the original developers of UNIX at Bell Labs, details a major flaw in breaking into the trusted code. Let's say he wanted to have some special code that would allow a very specific username to be able to login to any machine by modifying "login.c" and distributing it as an update:
if (strcmp(user, "ken") == 0) {
uid = 0;
login();
}
As we can see, this would allow anyone who knew this secret username "ken" to login to any UNIX computer and act as the root. But UNIX is open source, so surely someone would catch it! Ken Thompson took it one step further.
He proposed that he could hypothetically modify the C compiler itself to specifically generate the strcmp function if compiling the file "login.c". So now "login.c" looks safe to anyone who reviews it. But now, someone could look at the C compiler source code and discover that trickery as well. Ken Thompson could cover this up too by programming the compiler for the compiler, so that (if compiling the C compiler), generate the code that would modify the C compiler to generate the code that would modify "login.c". Now we run into trouble, and there is no way to verify that this has not been done already in any of the operating systems in use today including Ubuntu, Redhat, Windows 8, etc. In a sense, we have to not only trust the trusted computing base, but also trust that the developers were honest to not conceal something like that if we wish to use their operating system.