CS 111 - Lecture 3 Scribe Notes
Table of Contents
Very Secure Word Counter (VSWC) Program
The very secure word counter program (VSWC) is a program implemented during the previous lecture. The VSWC counts the number of words in a file as securely as possible. In this lecture, we will examine issues with our previous implementation.
Issues with VSWC
- Performance issues – it’s slow!
- It’s too much of a pain to modify VSWC, hard to maintain. (e.g. disks with different sector sizes)
- It’s too much of a pain to reuse parts of our program in other programs. “Cut&Paste” may work for a university project, but it doesn’t scale when developing real systems.
- It’s too much of a pain to run VSWC with other applications in parallel. Say we would like to run Microsoft Word and VSWC concurrently. If both programs use read_sector it’d be disaster!
- It’s too much of a pain to recover from faults reliably
Fixing Performance
Direct Memory Access
Using insl to get data off the disk is a resource hog – insl chews up the bus twice.
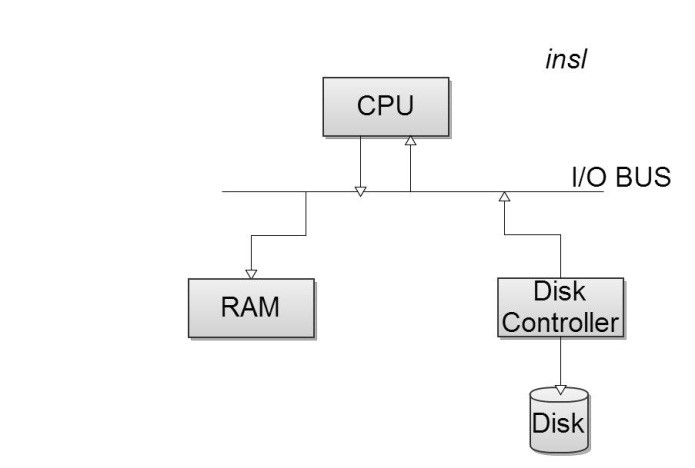
In the image above, the process used by insl is shown. In order to get data off the disk, the CPU commands the Disk Controller to grab the data off the disk. The CPU then issues a second command to store the data onto the Random Access Memory (RAM).
Solution:
Use Direct Memory Access! In Direct Memory Access, the CPU issues a DMA command to disk controller which tells it to send data directly to RAM. In comparison this chews up the bus only once.
Double Buffering
Another angle would be to consider how the CPU and the I/O interact currently interact. With a single buffer the CPU and I/O, each of which requires use of the buffer, must wait for each other to finish their individual tasks before executing their own tasks.
Suppose VSWC is a much slower program. Say that counting words (securely) took as much time to process the buffer as it takes to read the buffer from disk. Then the word counting process will be waiting for data half the time and VSWC will be twice as slow as it should be.
Solution:
Use double buffering! Double buffering fetches the next batch of data while simultaneously processing the current batch. Let’s look at the work diagram for both:
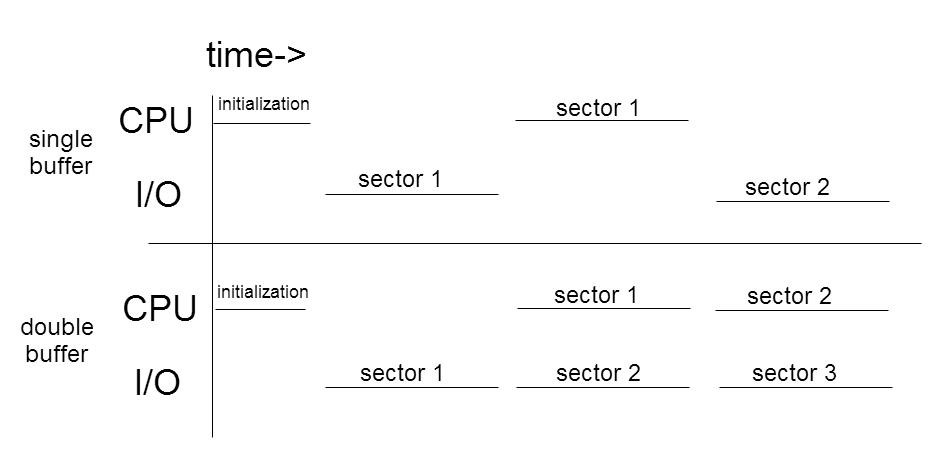
This effectively doubles the speed at which the program occurs.
Question: if double buffering gives 2x speedup, will triple buffering give 3x speedup?
No! Our program is hard limited by an I/O bottleneck. In order to read in I/O, we would need to have finished processing the previous input with the CPU. We would need multiple disks.
In the example above, we assumed that the I/O and CPU worked at about the same speed. But what if they operated at different speeds?
Suppose if either CPU or I/O was significantly faster than the other. The faster process would have to wait for the slower process to finish with its current sector before operating on the next sector. The slower process would in effect bottleneck the program. This effect is shown in the figure below:
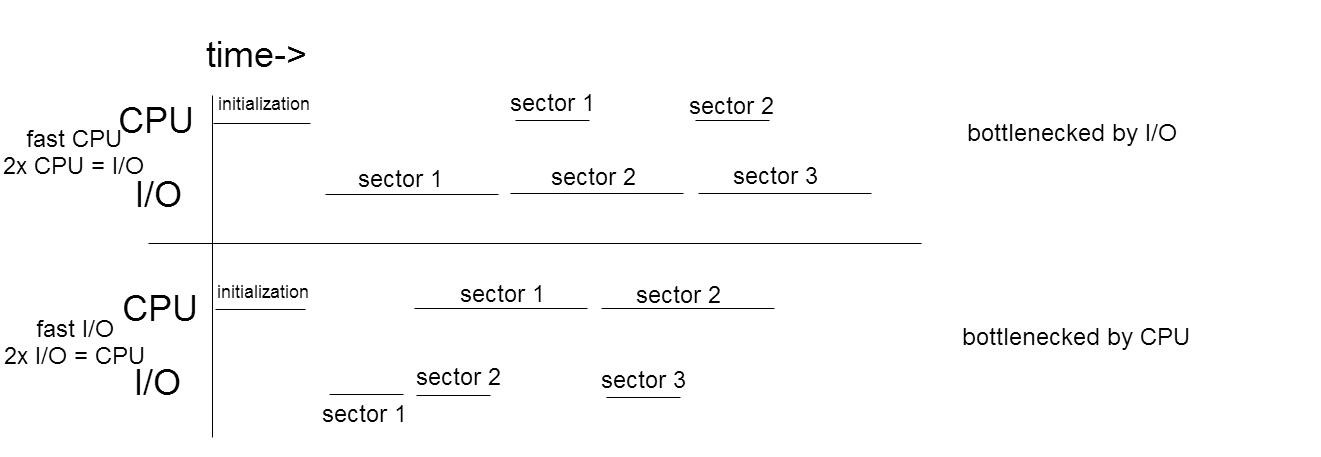
Caveat to Solution:
Double buffering is most efficient when CPU ≈ I/O, but double buffering is still faster than single buffering even when CPU != I/O. Speedup will be less than 2x.
While we have attempted a fix with performance, this isn't the only issue with VSWC.
Let’s count the number of places read_sector is copied: 1 copy in BIOS, 1 copy in MBR, 1 copy in VBR (if we had one), 1 copy in VSWC.
Could we save on having copies of read_sector? Say we just reuse the copy in BIOS – would this work?
Yes.. but there are problems. The BIOS implementation constrains disk controller (sector sizes must be 512 bytes) and constrains the OS. In practice, OS’s have a specialized read_sector. The read_sector issues shows there’s more that’s wrong with VSWC than just performance: there are software engineering issues.
Modularity
Now that we have tackled the first issue, performance, we will move onto problems 2 and 3. These are about trying to alter the VSWC, as it is tuned towards the aspects of one operating system at one point in time (that is, changes to the operating system might crash the VSWC). Its fixed values (accessing specific disk sectors) makes it both difficult to update the code and to use the program for other purposes. We’ll try to use modularity (break it apart) and abstraction (break it apart well) to solve these problems.
Modularity Metrics
Modularization can be “good” or “bad.” We need metrics to establish what is good modularization.
- Simplicity – modularization should be easy to learn, to remember, to use, to document, etc.
- Robustness – modules should work well in “harsh” conditions, tolerate faults, reduce noise
- Flexibility – each module should have as few assumptions of other modules as possible
- Performance – good modularization should not be an inherent resource burden
Creating Modularity
In what ways can we create modularization?
- Don’t: Instead, use lots of global variables and a giant function that does everything. In essence not using modularity creates a state machine, which isn’t a bad thing. Turing machines are a classic state machine and they’ve been shown to be capable of anything (you can’t trust those turing machines). State machines lose out on the benefits of modularization, but they’re fast!
- Functions/procedures/routines/methods: function call modularity, e.g. placing the ability to read from a sector in a function called "read_sector"
- Client/server modularity. We’ve already seen this in insl, client is CPU while server is disk controller.
- Virtualization: the meat and potatoes of OS. We’ll be using this a lot.
Consider a program with N lines of code and K modules (N = 106 and K = 2x103)
Assume number of bugs ∝ N and assume time to find and fix a bug ∝ N.
∴ time to fix all bugs ∝ N2, but this is without taking advantage of modularity
Using modularity assume modules divide up total program evenly, i.e. each module has N/K = 500 lines.
Assume each bug belongs to a module and bugs are distributed evenly among all modules. Thus, number of bugs ∝ N/K x K, and time to find and fix a bug ∝ N/K
∴ time to fix all bugs ∝ (N/K)2 * K = N2/K < N2
This sounds really great, and modularity does speed up debugging. However, in reality the speedup yield isn’t quite as good. In particular, bugs can belong to multiple modules. Some of our assumptions do not hold in practice. Consider having K = N2 modules. Then the time to fix all bugs is trivial!
Function Modularity
Separating code into functions separates processes from each other. In short, it allows each process to be considered individually from each other, which makes debugging them easier. It also allows for the coder to reuse their functions in different programs that require that one specific process (assuming that the function is written in such a way that allows for other programs to call upon it, e.g. allowing in general inputs instead of specifically defined structures within the current program).
Recursion: Factorial Example
Recursion is a special case of function call where the caller is also the callee. We shall examine the code for a factorial function as an example.
{
if (n == 0) {
return 1;
}
return n * fact(n-1);
}
If the c code above was stored in a file called fact.c then to get the assembly code,
we need to run the following on an x86 machine:
gcc –S fact.c
When getting the assembly code, you would normally run the command:
gcc –S –O2 file
However, if we ran this with the "-O2" flag (which optimizes our code) on our factorial function, it would compile it as if it was a loop instead as a recursive function. For the purposes of our lecture, we will ignore the optimization in order to examine the assembly code of a recursive function.
The assembly code for the factorial function would look like:
pushl %ebp
movl $1, %eax
movl %esp, %ebp
subl $8, %esp
movl %ebx, -4(%ebp)
movl 8(%ebp), %ebx
testl %ebx, %ebx
jne .L5
.L1:
movl -4(%ebp), %ebx
movl (%ebp), %esb
popl %ebp
ret
.L5:
movl %eax, (%esp)
call fact
imull %ebx, %eax
jmp .L1
From the assembly code, we can tell that:
%ebx stores n
%eax stores return value
In the recursive case, our factorial function would jump to L5 to compute the next number. Otherwise, if n equals 0, it would return the base case stored in L1.
The stack would look similar to what is shown below:
We have just jumped into: fact
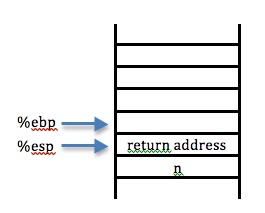
We have completed up to: movl %esp, %ebp (Although this isn't shown below, the value of %ebp has been pushed on the stack)
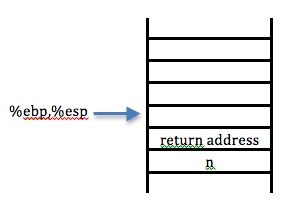
We have finished all the necessary stack storage from fact, and are either going to jump now to L1 or L5
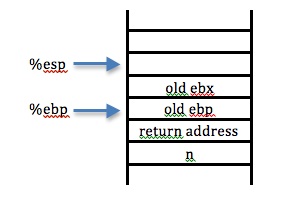
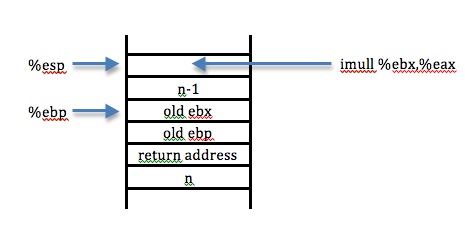
We have jumped to L5, and have computed n-1
Caller-Callee Contract
There is a caller-callee contract (i.e. an agreement between the caller and callee of the function) in order for this process to work without security breaches and/or bugs.
The unwritten caller-callee contract consists of the following conditions:
- sp[0] = return address (sp: "Stack Pointer")
- sp[1] = n
- sp[i] = ith variable
- at return:
- %eax holds return value (can hold any value during execution)
- %ebx,%ebp unchanged (can hold any value during execution)
- %esp = old %esp + 4 (callee’s responsibility to pop return address)
- no changes to sp[1], sp[2], ... , base of stack
- we have enough stack space = 16 x n+8 bytes
-
callee must set ip = sp[0]
- not return to a random location
- not loop forever
What goes wrong if this contract is violated?
anything!
Trust is required!
This is an example of soft modularity. With soft modularity, cooperation is voluntary. With
voluntary cooperation, a hostile callee could attack the caller with impunity.
Client-Server Modularity
To make our factorial example into client-server modularity, the factorial function is stored on a server. Then the client can call the server to get the result. For example, http://factorial.cs.ucla.edu/23 would print 2.58520167 x 1022.
This is an example of hard modularity. Instead of getting access to how to computation is done with the function modularity, the user can only use the browser interface to utilize the factorial function.
Hard modularity provides much better protection, but it is also much, much slower because of the UI interface. The client-server option is good for things that are big and hard to do. Big and hard problems are slow anyways, so the UI overhead wouldn't add too much extra time.
Virtualization Modularity
The image below illustrates virtualization. The OS contains an implementation of fake hardware, which the application runs on. The OS itself runs on the actual hardware.
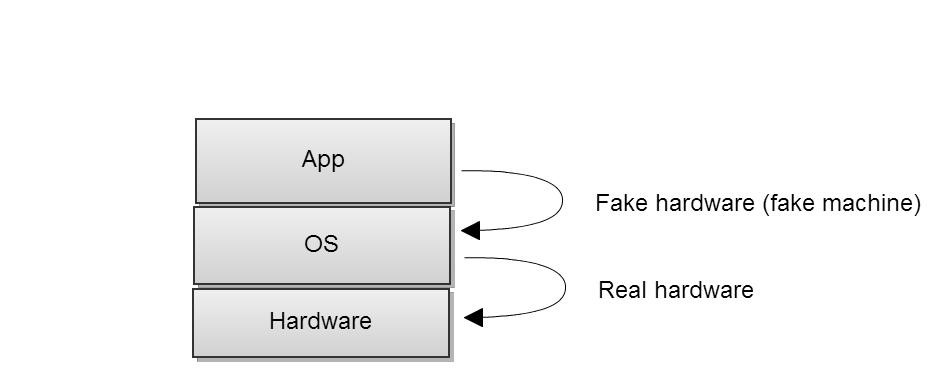
Virtualization is also an type of hard modularity. To make our factorial example into virtualization modularity, we create a virtual machine that would support x86 machine code and the new instruction factl. The process would be to first write an x86 emulator. Then, we would add the factl instruction to it. Finally, we would run the program that requires the factorial function in our emulator by using: factl %eax
However, this process is also very slow so we need to speed it up! We will learn how to speed this up in a future lecture.