CS 111: Lecture 3, Modularity and Virtualization
Scribe Notes for Lecture 3 on January 14, 2013,
by Shulin Jia, Qu Jin, Kwun Hang Edmond Yu, Wei Zou.
Table of Contents
Problem 1: Indirect memory access with the insl instruction is not efficient
Solution: Direct Memory Access (DMA)
Problem 2: CPU is left idle during I/O operations
Duplicate Code for read_sector function
Analysis: Performance and Software Engineering Issue
Example: Effect of Modularity on finding and fixing bugs
Good Metrics for Modularization
Stack Characteristics during the function call
In the last lecture, we introduce the Very Secure Word Counter (VSWC). There are some problems related to our approach. The BIOS, MBR, and VSWC programs need to access the disk; however, our previous approach was not efficient. We introduce two problems with it and their solutions: DMA and double buffering. In our approach to VSWC, there were several exactly the same copies of read_sector function, which will cause performance and software engineering issues; the software engineering rescue to this problem is modularization.
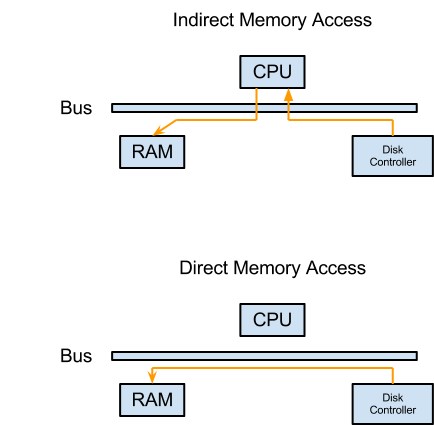
In our VSWC, we used insl extensively as our method to grab data from the hard disk to the RAM. However, insl is slow. As it is designed, insl transports data from the disk to the CPU before finally moving them to the RAM for use. Since all three components (the disk, CPU and RAM) shares the same bus, this method is effectively occupying the bus for twice as long as it is needed, slowing down other parts of the system as many operations require the shared bus to be free.
To correct this problem, we can use a method of data transport known as Direct Memory Access (DMA) to access data on the disk . In DMA, the disk controller issues the transfer of data to the RAM directly and skipping the middle-man – namely, the CPU. This way, our shared bus is used once instead of twice in the insl case, improving the overall performance of our program. The following is the graph for comparing Indirect Memory Access and Direct Memory Access.
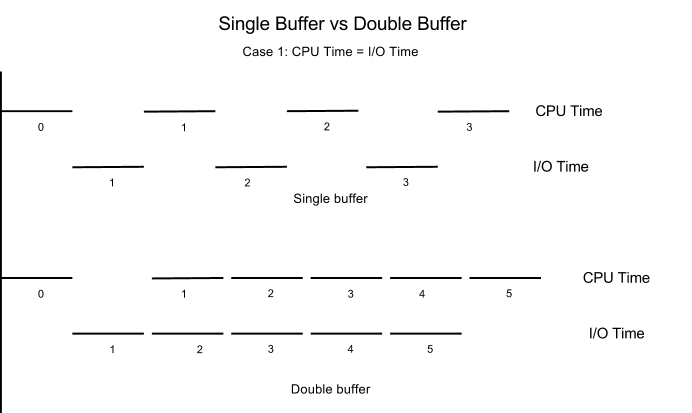
Now suppose our VSWC is slower – so slow that the time needed to process a block of data is the same as the time needed to retrieve them from the disk. Using a single buffer, the CPU first issues the read-from-disk command, goes idle while the I/O finishes, then process the data. In this version of VSWC, our CPU is left idling for half the time waiting for I/O operations to finish, and our disk controller is left idling when the CPU is processing.
To improve performance, we can use two buffers instead of one. With double buffers, when the CPU is processing the current block of data in buffer 1, it can also retrieve the next block into buffer 2 at the same time. When the processing (of buffer 1) is done, the CPU can then move on to the next block (in buffer 2) immediately without waiting. Using this technique on our “slow VSWC”, it allows our CPU to be active all the time. Comparing to using just one buffer, we would have achieved a 2X performance increase. However, the downside to this technique is that twice as much RAM is needed. The following is the picture illustrating the effect of double buffering.
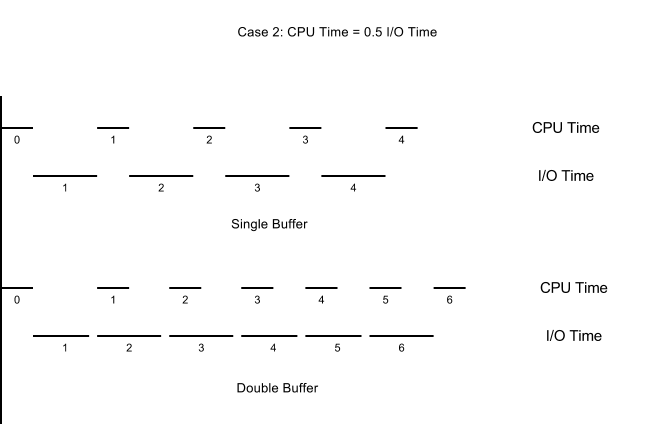
Of course, the improvement we can get from using double buffer depends on the relative speed of processing and I/O. The closer the processing time and I/O time is, the better the improvement. For example, if processing is 2 times faster than I/O, then the improvement will be much smaller (50%), because the CPU still has to idle for a significant amount of time. The effect is illustrated below.
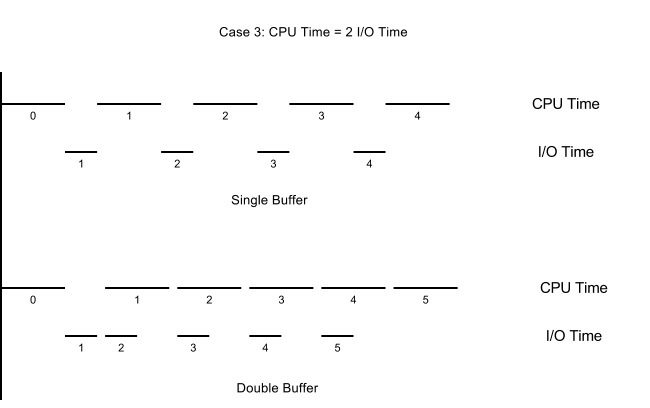
Conversely, if I/O is 2 times faster than processing, we are bottlenecked by the CPU, and we will gain only a 50% increase in performance compared to using single buffer.
What if we add even more buffers? Is that going to help? The answer is no: the disk controller can only retrieve one block at a time. If it is already at 100% utilization, adding more buffers won’t increase the performance at all – we are bottlenecked by the I/O channel.
Recall the Very Secure Word Count (VSWC) program introduced in the last lecture. The BIOS calls read_sector function to load the MBR (Master Boot Record) from disk into memory, the code section in MBR (first 446 bytes) calls read_sector function to load VSWC program into memory, and the VSWC program calls read_sector function to load a text file in order to count words of the file (for general operating systems, MBR calls read_sector function to load Volume Boot Record (VBR), and VBR calls read_sector to load an Operating System). Thus, there will be one copy read_sector in BIOS, one copy in MBR, and one copy in VSWC. It’s a waste since we have three copies of the same thing.
One solution to this problem is that we use only the copy in BIOS for all three loadings (BIOS, MBR, VSWC). This works in the VSWC case. In fact, However, if we want to boot operating systems later, the downside is that it assumes every OS reads sectors in a particular way. The read_sector function in our BIOS implementation constrains to work with disks of 512 bytes sector size, so it doesn’t work with all disk controllers, and doesn’t work on bigger sectors.
There are several downsides to keeping multiple copies of read_sector:
e.g. Running Microsoft Word and VSWC in parallel on the same machine. We have no way of taking care of the case in which they both use read_sector to read the same memory.
We only worry about problems 2 and 3 for now. To solve the 2 problems (code modification and code reusing), we need to apply Modularity (or Abstraction) to break our apps into “nice” pieces. To see the benefit of Modularity, let’s analyze the effect of modularity on finding and fixing bugs.
Notation:
N: number of lines of codes.
B: number of bugs in the code.
T: amount of time to find and fix a bug.
K: number of modules we use in the program.
(1) Case without module:
Assume the number of bugs B is proportional to the number of lines N, say
B = aN
and the time T to find and fix a bug is proportional to the number of lines N, say
T = bN
Then we can say the time to find and fix all bugs is
T_total = B * T = aN * bN = ab*N^2
So the total amount of time is proportional to N^2.
(2) Case with module:
Now, say we apply modularity. We use K modules, and each module has the same size, so the number of lines in a module is:
N_m = N / K
Also assume B bugs distribute evenly into each module, so the number of bugs in a module is:
B_m = aN / K
In a module, the time to find and fix a bug is proportional to the number of lines in that module, which is N_m = N / K, so the time to find and fix a bug in a module is
T = b*N_m =b N / K
Then the total amount of time to find and fix all bugs in a module is
T_m = B_m * T = (aN / K) * (bN / K) = ab (N^2)/(K^2)
For all bugs in the K modules, the time to find and fix all of them is
T_total = T_m * K = ab(N^2) / (K^2) * K = ab(N^2) / K
Thus, the time to find and fix all bugs is proportional to (N^2) / K.
Compare the cases (1) and (2), we can see with K modules, we reduce the amount of time to find and fix all bugs to 1 / K of the original time without modules.
(3) Downsides.
Does that mean the more modules we use the better it will be to maintain the program? Can we let K = 2N so reduce the time to find and fix bugs to N/2? That would mean we put only “half line” of the original code in a module! In the example, we assumed that the time to find and fix a bug is proportional to the number of lines within that module, which implies that a bug is related to one module only. However, the fact is that a bug can often relate to several modules, so when fixing a bug, we often need to consider more than one module. Another problem with modularity is that it hurts the performance. As will be described later in the notes, function calls (soft modularity) need to do stack operation, which will slow down computation. Hard modularity is even slower than soft modularity. Therefore, although modularity will help maintain the program, we should be careful when applying it.
What’s the reason to pick one module over another?
Simplicity (relates to cost in development) | Is a module easy to learn, to remember, to document, or to use? Is it intuitive? |
Robustness | How well pieces work in harsh conditions? Is it fault tolerant? |
Flexibility | A good modularization should be lack of assumptions about other modules. |
Performance | Does the modularization cost too much? |
In order to support modularization, it is discouraged to use lots of global variables and to create one function that does everything. Global variables may introduce undefined behaviors when a shared variable is changed in an unexpected way. One function that does everything (such as a turing machine) goes against the idea of modularity and code reuse. We also want to support readability so people can understand and debug a program.
To implement modularization we will use:
Using functions we can separate out pieces of instructions that are called repetitively. However it is important to know what the stack looks like between caller and callee functions. Problems involving the modularity of callee and callers derive from conflicts in memory which we will discuss. Using this factorial function example we can see how stack space is used during function call.
int fact (int n) {
if (n == 0)
return 1;
else
return n*fact(n-1)
}
And in assembly (Assuming x86):

%eax - holds the return value of the function call
%ebx - holds the value of variable n
%esp - stack pointer. Points to the top of the stack
%ebp - base pointer. Preserve the previous frame on the stack
gcc -s -O2 fact.c
gcc -s fact.c
fact: (function to be called)
pushl %ebp ->push the previous base pointer
movl $1, %eax ->store value 1 into %eax
movl %esp, %ebp ->set base ptr to the stack ptr
subl $8, %ebp ->move %ebp 2 bytes down
movl %ebx, -4(%ebp) ->move %ebx 1 byte down the base pointer
movl 8(%ebp), %ebx ->store n into %ebx
testl %ebx, %ebx ->see if n is 1
jne L5 ->if not, jump to the recursive process
L1: (return value)
movl -4(%ebp), %ebx ->store return value n into %ebx
movl %ebp, %esp ->set stack ptr to base ptr
popl %ebp ->pop out the old base ptr
ret ->return value
L5: (recursion happens here)
leal -1(%ebx), %eax ->store n-1(n from %ebx) to %eax
movl %eax, (%esp) ->set stack ptr to where n-1 is stored
call fact ->call fact
imull %ebx, %eax ->n*val(%eax)
jump L1 ->jump to L1 to return(val stored in %eax)
registers\routines | fact | L5 | L1 |
%eax | 1 | n-1 | return val |
%ebx | n | n | n |
%esp | top of the stack | addr of %eax (e.g.n-1) | base pointer |
%ebp | pushed in from previous base pointer | previous frame | popped out |
Soft modularity depends on modules working together. There is a certain amount of trust between the caller and the callee. In consequence, any errors suffered by one module may propagate to another as modularity is not enforced and the contract may be broken regardless of intentions by the programmer.
Contract | Consequence from breaking the contract |
Callee only modifies its own variables and variables it shares with the caller. Callee does not modify the stack pointer and leaves the stack the same as it was called when it returns. | Callee corrupts the caller’s stack and the caller may use incorrect values in later computations. |
Callee returns to the caller. | Callee gets unexpected values or loses control of the program (for example, infinite loop). |
Return values are stored in %eax | Caller will receive whatever value is in %eax which will be incorrect. |
Caller saves values in temporary registers (%ebx) to stack before calling callee. | Callee may change values that caller needs and caller will receive an incorrect computation. |
Callee will not have a disaster that affects caller (example: early termination). | This is called fate-sharing: caller will also terminate. |
In the example of the factorial function, the contract is thus:
Can we enforce modularity with a strongly typed language such as Java? While java does solve most of the problems of soft-modularity, systems are not completely implemented type-safe languages. And it is still possible to violate the caller-callee contract with Java with, for example, memory allocation and file i/o.
Thus in order to have enforced modularity we must use some external mechanism to limit the interaction between modules.
Hard modularity restricts interaction between modules and validates expected results from a module. One way to do is this by organizing modules as clients and services, which communicate through requests and responses respectively.
Hard modularity is enforced because since the client and the service do not share memory, and modules can check the validity of the messages sent between them. In consequence, hard modularity via client/service is much slower than soft modularity.
In the factorial example, hard modularity can be implemented with a web service available at a url such as http://factorial.cs.ucla.edu/fact=23 and the factorial of 23 would be printed in the browser. In this example factorial.cs.ucla.edu is the service and the browser is the client. If for some reason the web service goes into an infinite loop is becomes unavailable, the browser as an automatic response to stop waiting for a response or to display an availability error.
Conceptually the service and the client are on separate computers but using the OS, the two modules can exist on the same computer.
We can simulate the client/server organization on one computer by using virtualization. This means that a separate virtual computer is used to execute a module.
For example in the case of the factorial function, using a virtual x86 machine we can have an instruction called factl which produces the same results as that stores its return value in %eax. The factl instruction executes in a virtual memory and eliminates the possibility of memory overwriting from other modules.
Virtualization causes extra overhead and we need to speed up the process for it to be useable.