CS111 Lecture 4 Scribe Notes (Winter 2013)
Operating Systems Organization
By Jacob Jarecki and Kevin Ren
Table of Contents
Details of Operating System Organization
Protected Transfer of Control
One method of having protected transfer of control is through the use of an interpreter
Benefits of an interpreter:
- Can do whatever you tell it to do
- It can gather performance statistics or correctness statistics
- Might be for a new (nonexistent) or different machine
Downsides of an interpreter:
- Resource hog, the CPU cost can be up to 10x more
- Slow and has memory cost
- Might be buggy
- Timing characteristics can differ from the actual machine, causing or "fixing" bugs
What we really want is the ability to add instructions to the instruction set.
Types of Instructions
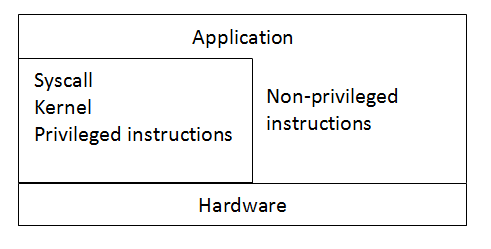
Instructions are divided into two categories: the non-privileged instructions and the privileged instructions. A non-privileged instruction is an instruction that any application or user can execute. A privileged instruction, on the other hand, is an instruction that can only be executed in kernel mode. Instructions are divided in this manner because privileged instructions could harm the kernel.
movl addl call ret
insl outb inb int
A program that tries to run a system call the kernel does not consider to be allowed will be terminated.
$ ./a.out # has system call the kernel disapproves of Illegal instruction killed $
Example of Removing a File
If we want to remove a file, we may have to write x86 instruction like:
pushl filename call unlink addl $4, sp
Instead, we just want:
pushl filename unlink addl $4, sp
To do this, we need to first put in an invalid instruction:
pushl filename 242 ;;invalid instruction, causes a trap addl $4, sp
The invalid instruction, 242, causes a trap, which gives us the protected transfer of control. By convention, the instruction on Linux for a privileged interrupt is int 0x80. So the set of instructions above should be changed to:
pushl filename int 0x80 addl $4, sp
How to do a Protected Transfer of Control
When a trap occurs, the hardware causes the following to happen:
-
Pushes
ss //stack segment
esp //stack pointer
eflags //processor control bits
cs //code segment
eip //instruction pointer
error code //details about the trap
- Sets ip = interrupt service routine
- Sets the processor control bit
Because of the many pushes needed, the int call is a slower than a general call. This means an interrupt causes the CPU to work much harder.
When the program executes the int 0x80 instruction, it then goes to the interrupt service vector, looks at entry 0x80, and executes that code. The processor control bits are switched when the code executes.
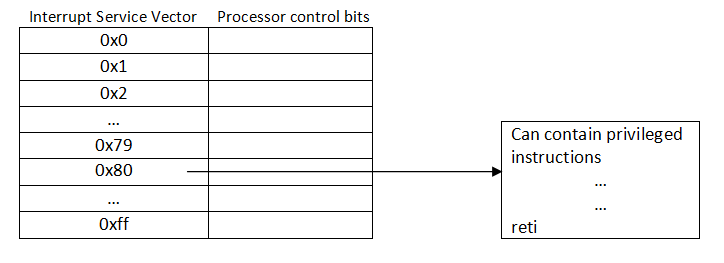
After executing this code, it’ll reach an instruction reti, which pops off everything that was pushed onto the stack before, switches back the processor control bits, and then returns to the original code. Reti is to a trap as ret is to a call instruction.
Protecting the Interrupt table
In order for this to work, we need to protect the interrupt table.
Instructions should not be allowed to stomp on the table by changing its information.
One solution is to keep the interrupt table in ROM (read only memory). However, you can still move the sp pointer to be next to the ROM and overflow the stack, thus trashing the kernel. To protect from this, we check the cs and ss bit to tell which stack we are using. This keeps the kernel protected.
A general rule of thumb is do not let the kernel trap! The kernel may likely go into an infinite loop and destroy itself if it is allowed to trap.
A Layered System
Suppose we have a virtualizable processor, where it's relatively easy to build a virtual machine on top of the real machine.
With such a system, modularity is established through components.
One component is having invalid instructions, which are reserved to the OS
The other component is reserved memory locations, which protects the kernel from being modified.
Through these components, a layered system is achieved:
Another example of a layered system, but with more layers:
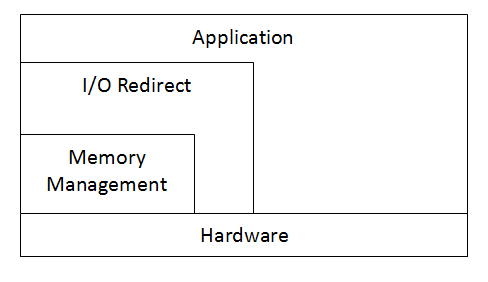
This layered system has a small inner level used for memory management, another level for redirecting output, and then the highest level which is used by applications. This approach gives much more protection and security to the memory management area of the code.
Ring Structured OS
A ring structured OS can be envisioned like the following:
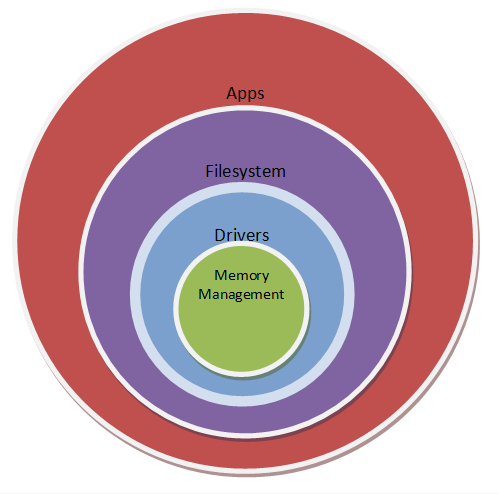
This is also called the microkernel approach because the memory management part of the OS is a very small portion. Here, there are 2 bits to tell what the processor level is. In total, there are 4 levels.
An real world example of this approach in use is in the upcoming BB10 (Blackberry 10) OS. This approach allows for more security, making it favorable when handling a large amount of sensitive corporate information. However, this extra level of security comes at a cost in performance.
Which Design to Use?
The design to use depends on what type of system is needed. If performance is key, then a system with fewer layers is preferred because fewer layers leads to higher performance, with the downside of less security.
However, if security is key, then more layers is preferred because this gives better security, with the downside of decreased performance.
Example System Call Implementations - Reading from Disk
Insl-Like System Call Example
This is an example system call implementation. The system call is arbitrarily numbered 39.
char buf[1024]; insl(192,buf,256); //insl(device_number, buffer_location, number_of_words) //1024 bytes * 4 bytes per word = 256 words
movl $39, %eax movl $192, %ebx leal buf, %ecx movl $256, %edx int 0x80
Implementation Problems:
- Lacks Security - This system call allows the application to read wherever it desires.
- Too Low Level - Most programmers would prefer a higher level API, just put the bytes they want, no word conversions
Higher Level Readline System Call Example
This is an example system call implementation. The system call is arbitrarily numbered 119.
//FILE* is a high level concept that will inevitably //have to represented by low level machine words char* readline(FILE* f);
movl $119, %eax movl f, %ebx int 0x80
Handles:
The above example illustrates the problem of handles.
A handle is a low level, small representation of a high level object.
Possible FILE* Handle Implementations
- A pointer to an actual object.
- An integer (FILE instead of FILE*), handed out by the operating system.
A reason not to use option 1, is that the application can then see internals of the operating system object.
Another API for Readline System Call Example
API: An API is an application programming interface, which means the format of a certain way to call some function.
C-Like Syntaxchar* readline (int file); //Assuming option 2 is taken in the aforementioned handles discussion //A line, here, is defined as a sequence of bytes terminated by a newline: '\n'
Implementation Problems/Solutions:
- Problem: OS must keep record of where the application is in the file
Solution: Let the OS take care of it - Problem: Reading of a partial line may want to be done
Solution: Let the application take care of it (unsupported) - Problem: A file may have extremely long lines, or perhaps have no newlines at all
Solution: Return NULL or zero, on long lines, set errno to some value on no new line case)
These fixes, however, are awkward. How big of a line is too big of a line? This is thus not a good API for reliably reading files.
And perhaps the most glaring downside, is the fact that readline expects the kernel to deal with memory allocation, while, in general, applications deal with their own memory allocation, which can at times be a nicer solution.
char* p = 1; //Not allowed char* p = 0; //Allowed char* p = -1 + 1; //Allowed
These system calls certainly function, but we still haven't reached an ideal level of abstraction. insl was too low level, and readline was perhaps too high level.
API for read_sector/read
void read_sector(int device_number, char* buffer, int sector_count);
Implementation Problems:
- Device numbers are not very portable
- Sector size could be 512 bytes, 2048 bytes, etc., causing great inconvenience for the application writer
Should be changed to:
void read(int file, char* buffer, int size_in_bytes); //accompanied by int open(char**) //returns the int to be associated with the file opened
Key Concept:
- Are we actually reading in less than a sector at a time with read?
- To the application, yes. To the operating system, no. The operating system creates a buffer to store data until it is needed.
API for pread
This API addresses the issue of the OS recording of file location
void pread(int file, int offset, char* buffer, int buffer_size);
pread seems great for non-sequential reading.
read seems great for sequential reading.
To get both, the following can be done:
void lseek (int file, int offset, int flag) //Values for flag // SEEK_SET 0 Offset is to be measured relative to start. // SEEK_CUR 1 Offset is to be measured relative to the current location. // SEEK_END 2 Offset is to be measured relative to the end of the file.
Lseek repositions the OS's opinion of where the application is in the file.
Lseek, in combination with read, is a pread.
Unix originally picked lseek and read, but later it, and POSIX, added pread.
read + lseek for sequential, pread for random access.
Dealing with Errors
The code is unlikely to do exactly what an application wants, despite its best intentions. For instance, if your pet chinchilla tips over your desktop computer, causing the read head of your disk to destroy your data, there are going to be some read failures.
Useful instead of returning void, the return value should be an int corresponding to the number of bytes successfully read.
For a read() of N bytes:
- Return value in range of (-1, N)
- 0 Means EOF reached
- -1 Meaning something went horribly wrong (in other words, go chastise your chinchilla)

Lseek returns new, updated offset, or -1 or errno.
To read last byte in file:
char c; if (lseek(fd, -1, SEEK_END) > 0) error(); if (read(fd,&c,1) != 1) error();To get current location within file:
int current_location = lseek(fd, 0, SEEK_CUR); //Doesn't change the location, just forces return of current location
An int works fine when the int contains more range than the file.
2^31 - 1 is only 2 GB, thus for ranges over 2 GB, and int won't work.
Double/Float's do not work due to rounding errors as the number approaches higher bounds (not to mention inf values)
Long is enough on x86-64 machines, but not on x86 machines, thus causing code like the following pseudo-code:
if x86-64 long else long long error();
Code instead uses an off_t type, a defined file offset type
//#include <sys/types.h> this is where those type definitions are typedef long off_t; off_t lseek(int, off_t, flag);
The int in the above is fine as less than 2 billion files are being used (we allow this limitation)
What about read?
ssize_t read(int, char*, size_t);
And since we may need buffers over 2 GB in size:
typedef unsigned long size_t; typedef int ssize_t //No good, since ssize_t != size_t; typedef long size_t; 32 typedef long long ssize_t; 64
Regardless, the problem exists, as even in the last solution, the sizes they don't match.
Aside About Race Conditions
Multiple applications can be doing I/O at the same time.
Often this results in buggy behavior.
In principle, the OS should serialize requests, and execute in that order.
Pass in bad pointer to read, NULL, or valid with bad size, read should return -1, and set errno to EINVAL.
An int FILE handle can refer to:
- File or disk
- Device
- Network connection
For references of type 2 and 3, the data requested may not be ready yet, do we wait?
For next time: What do we/should we do when data is not ready yet?
![]()