Lecture 10: Synchronization (contd.) and Filesystem Performance
Kevin Balke
Contents:
- Harware Lock Elision
- How to Solve the Deadlock Problem
- Priority Inversion
- Livelock
- Event-Driven Programming
- Filesystem Performance
- I/O Performance Review
Hardware Lock Elision
Suppose we want a faster locking mechanism. We would like something like xchgl but faster because xchgl slows things down.
lock:
movl $1, %eax
try:
xacquire lock xchgl %eax, mutex
cmp $0, %eax #should be 0 if grabbed lock successfully
jnz try #if not 0, try again
ret
unlock:
xrelease movl $0, mutex
The xacquire prefix is special; it does everything between xacquire and xrelease provisionally, i.e., in cache without committing to memory. When control reaches xrelease, if some other process had obtained the lock, control jumps back to xacquire and the call to lock() fails; in effect, all the work done between xacquire and xrelease never happened.
This removes the bottleneck of locking because it does not tell everyone to get out. This locking mechanism is good for situations where little work is done between lock() and unlock(). For example:
int var;
lock_t somelock;
if(lock(&somelock)) {
var = 29;
unlock(&somelock);
}What if we have too much locking? This can lead to the problem of deadlock. Suppose that we have an API for a bank. There are functions for performing transactions between accounts within the bank. For example, suppose that there is a transfer of money from account #19 to account #27 in the amount of $3. This transaction could be performed as follows:
transfer(3, 19, 27); //transfer $3 acct#19 --> acct#27This will cause deadlock if not performed carefully. Suppose this operation is performed as follows:
lock(#19);
lock(#27);
do work
unlock(#19);
unlock(#27);This will cause deadlock if there are multiple threads! For example:
- Thread 1 performs transfer from account #19 to account #27
- Thread 2 performs ransfer from account #27 to account #19
Thread 1 might acquire its lock on 19, after which it is interrupted to schedule Thread 2; Thread 2 will then aquire its lock on 27. Thread 2 will try to acquire a lock on 19, which Thread 1 still holds, so it will be marked blocked and its execution will stop. Thread 1 will then be rescheduled, and it will try to acquire a lock on 27, be marked blocked, and its execution will stop. Neither process will forfeit their lock, and so neither process will be able to run. This is known as deadlock.
We need to know when to look out for deadlock. So...
The 4 Things to Look Out for when Considering Deadlock
- Mutual Exclusion: If no process can gain exclusive access to a resource, deadlock is not a problem.
-
Circular Wait: If there is no loop in the graph of processes that wait on each other for resources, then deadlock is not a problem. Such loops may be of arbitrary size, so care must be taken in checking for them.
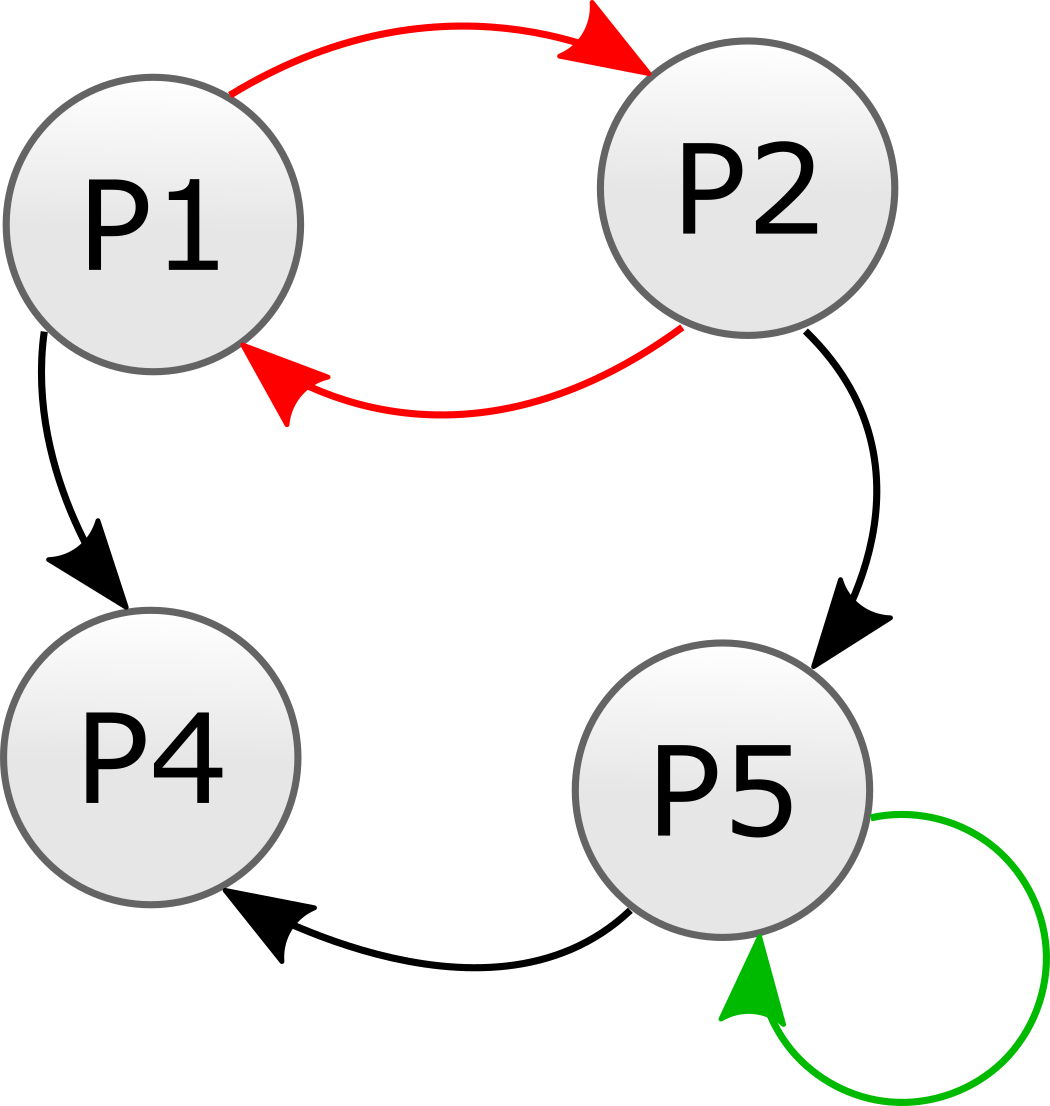
The arrows in the drawing show which processes wait on each other. There exists a wait cycle between P1 and P2 that could cause deadlock. Additionally, P5 waits on itself, which can cause deadlock. - Lock Preemption: If a process can lock a resource when another process has the lock (effectively booting the current lock holder off of the resource), then deadlock is not a problem.
- Hold & Wait: If a process cannot be holding resource(s) and wait on other resource(s) that are busy, then deadlock is not a problem.
How to Solve the Deadlock Problem
There are two major ways to solve the deadlock problem.
- Detect deadlock dynamically: The OS can prevent applications from causing deadlock by keeping track of all attempts to acquire resources and deny those that can cause deadlock.
A possible implementation could havelock()fail, settingerrnotoEDEADLOCK, when a process requests a resource that would create a loop in the wait graph (The OS will maintain such a graph). Applications have to be modified to account for this behavior. - Redesign the kernel such that deadlock cannot occur:
- One (drastic) way is to remove locking entirely!
-
Lock Ordering: Every process needs to agree on an ordering of all the possible locks in the system from
1-N. If this is implemented on LINUX, for example, the address of a lock can be used to determine order. If a process needs to have more than one lock, it will attempt to acquire them in order. If it attempts to acquire a lock that another process holds, then it forfeits all of its locks and retries from the beginning. This requires processes to use "try and acquire" primitives for blocking mutexes.
Priority Inversion
Priority Inversion is a global system property that can cripple multitasking systems. It is responsible for a serious bug that manifested shortly after the landing of the 1997 Mars Pathfinder Rover, causing unanticipated system resets under high-load conditions.
To understand this problem, imagine that there are three threads, T_low, T_medium, and T_high, running on the Pathfinder's on-board computer. Their names denote their execution priority.
-
T_highis responsible for communication back to Earth. This process must run above all else because loss of communications to Earth means critical failure. -
T_mediumis responsible for checking the battery level. -
T_lowis responsible for performing background processing, perhaps encoding images for transmission to Earth. This is of lowest priority.
Suppose that T_low is runnable, and that both T_medium and T_high are waiting upon resources held by other processes. T_low then calls lock(some_resource) and after obtaining this resource, is interrupted by the scheduler. At this moment, T_high becomes runnable (the resource it was waiting on has become available), and the scheduler passes control to T_high for execution. T_high then calls lock(some_resource), and because some_resource is held by T_low, it becomes waiting. At this moment, T_medium becomes runnable, and starts execution. T_high cannot run because T_low holds the resource it needs, and T_low, in turn, cannot run because it has lower priority than T_medium. In this way, the lower priority processes on the system collude to starve the higher priority processes of CPU time.
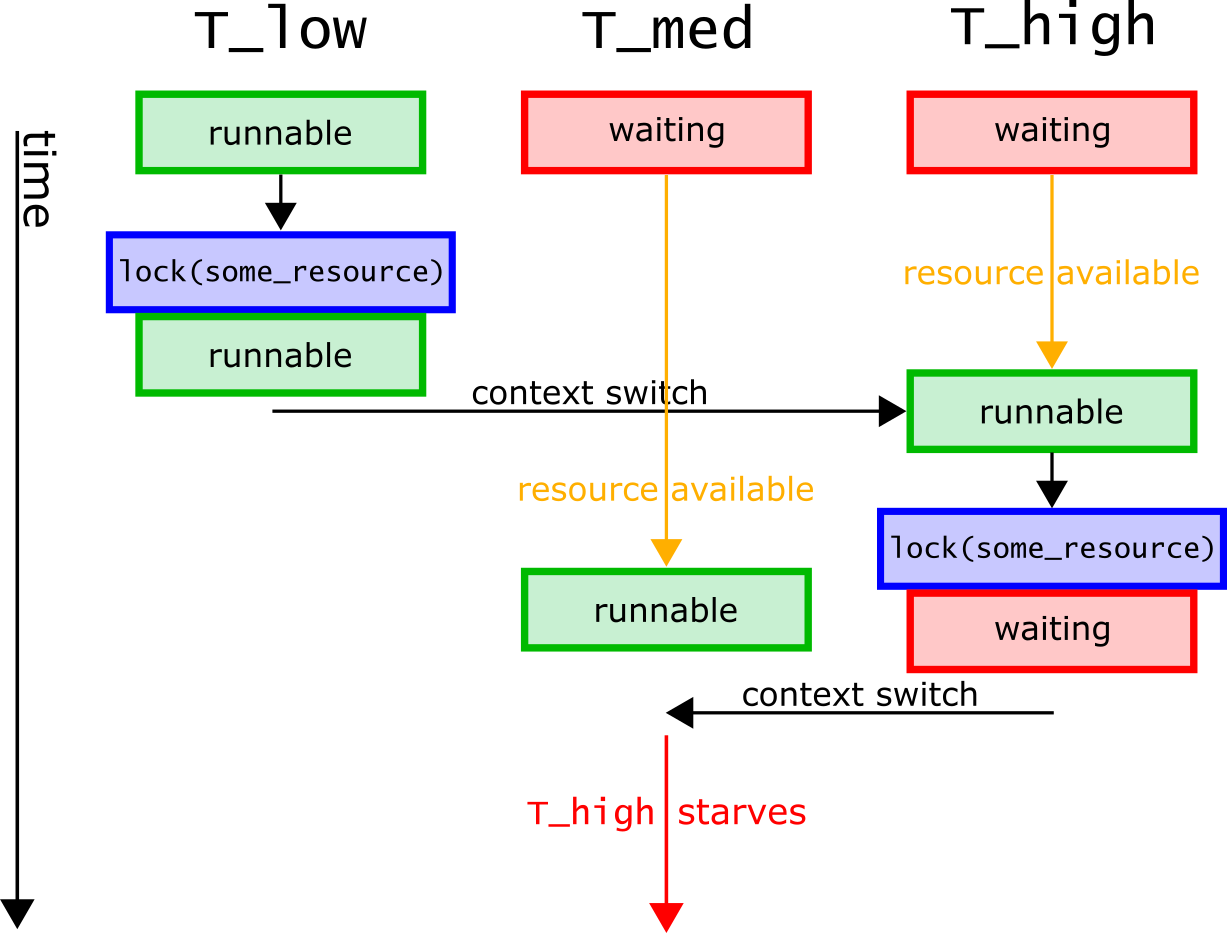 To fix this problem,
To fix this problem, T_high can temporarily lend its scheduling priority to T_low, ensuring that T_low can run and eventually release some_resource, allowing T_high to run in a timely manner.
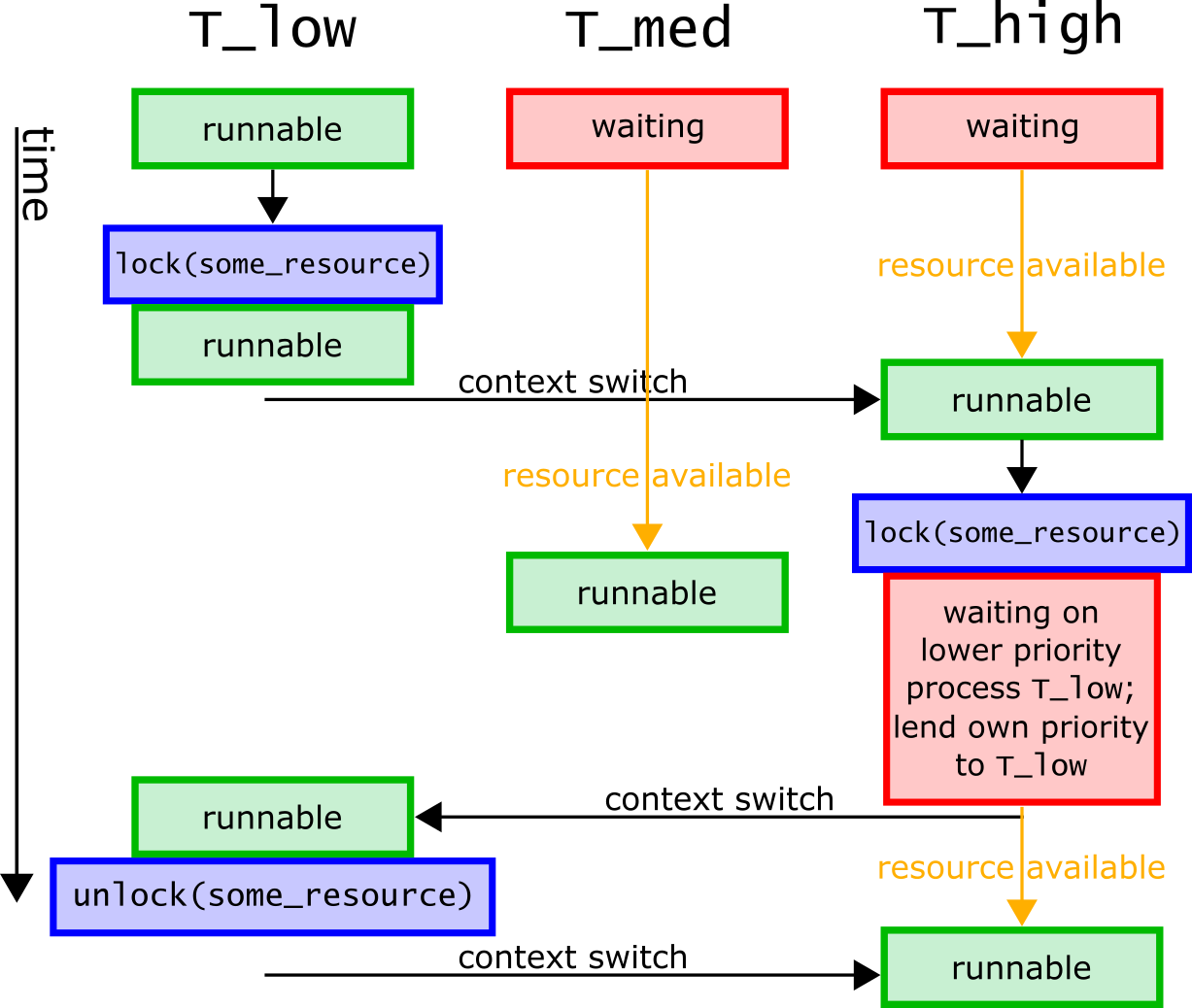
Livelock
There is another form of synchronization problem that is not deadlock. This problem is called Livelock. Livelock is where execution is not blocked (threads are running), but no progress (or very little progress) is being made.
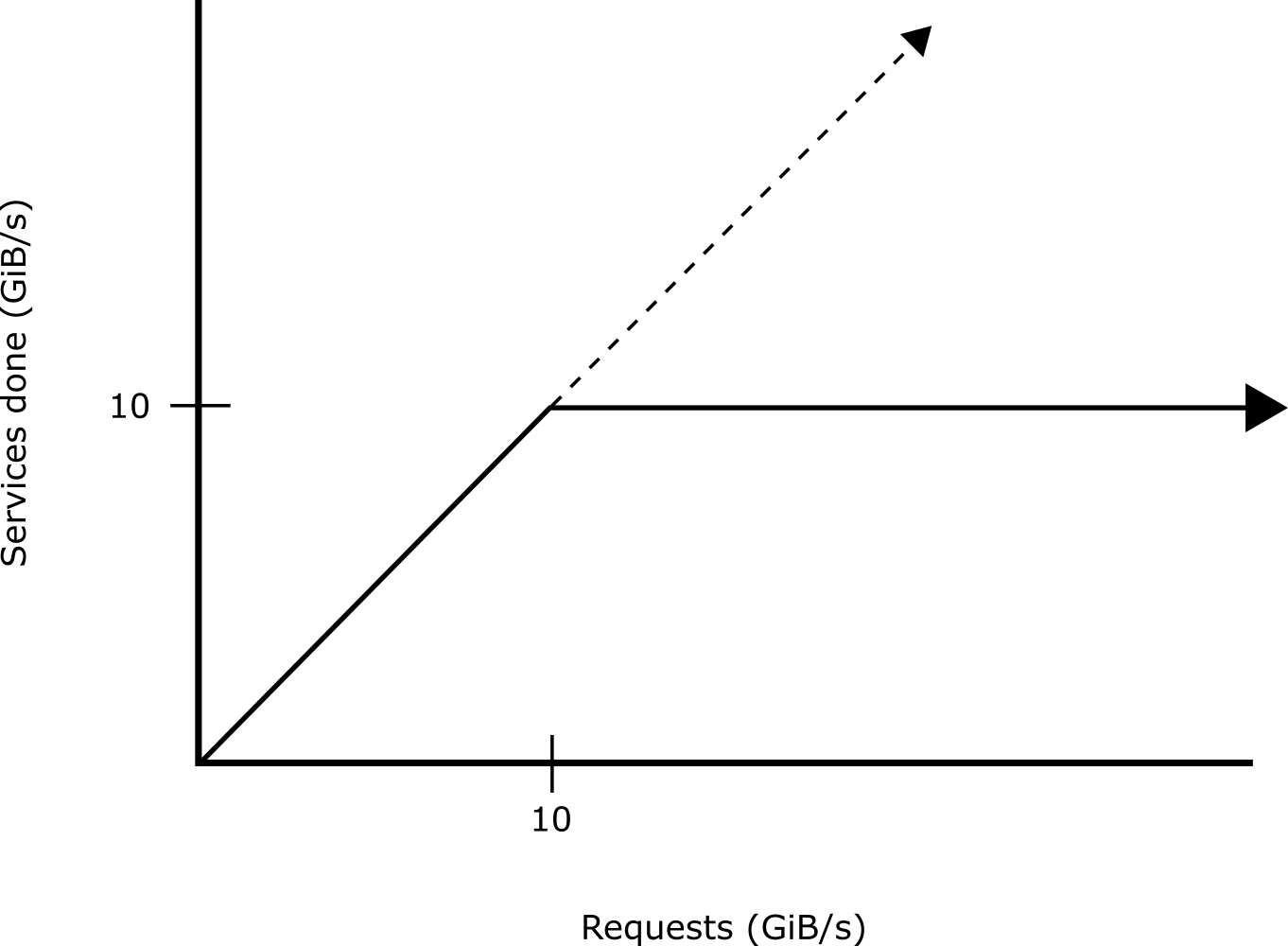
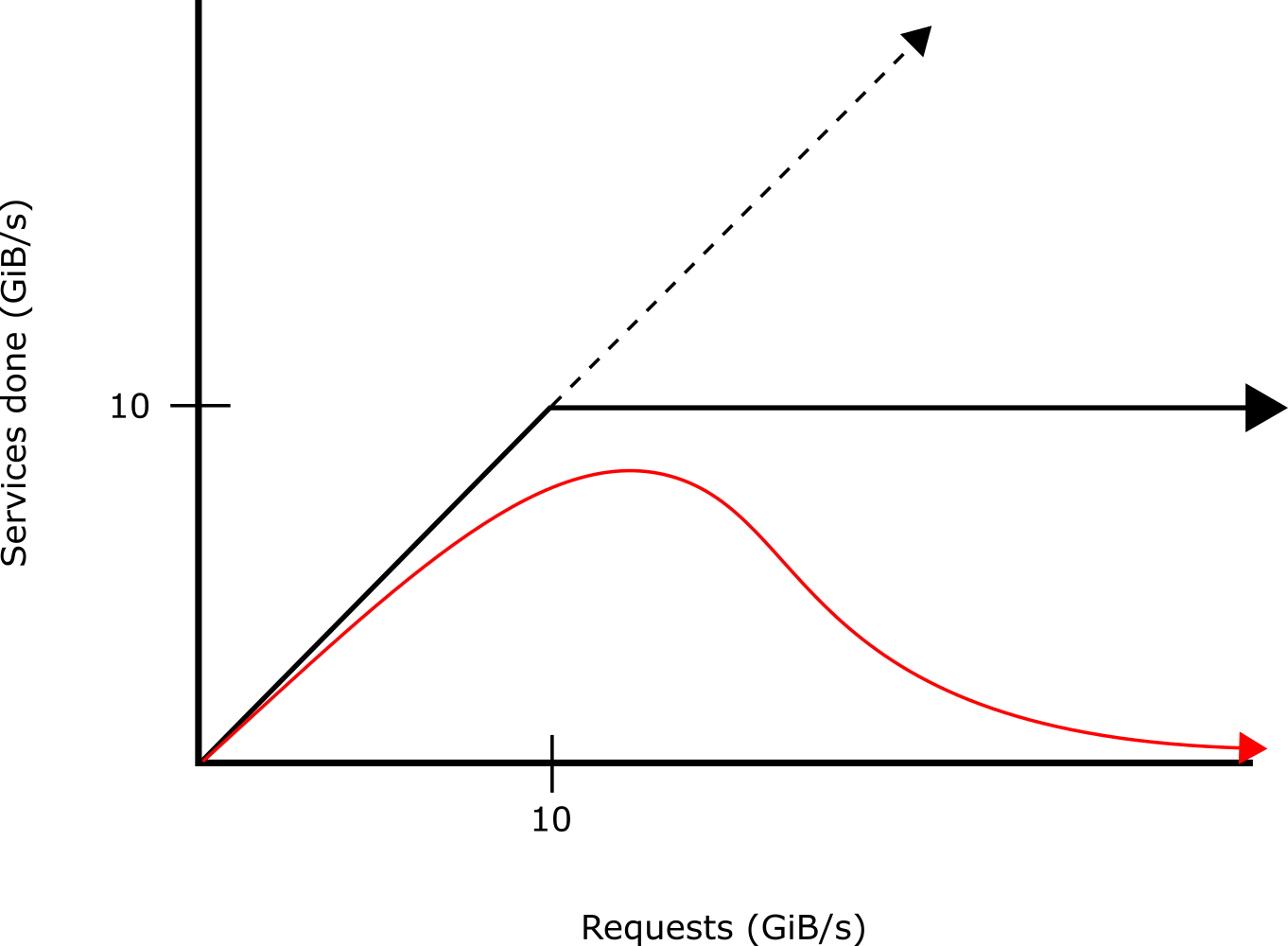
For example, suppose that there is a bounded buffer, and data from the network is being read into it at a maximum rate of 100 GiB/s. A service is emptying data from the buffer at a lesser 10 GiB/s for processing. As long as the network traffic is not too great, the process will be able to handle all data received.
However, if the network traffic exceeds the rate of the handling process, then there is a potential for livelock.
The behavior of the system should look like this:
However, there is some overhead associated with receiving a packet; when the network controller receives some data, it triggers an interrupt on the processor. The handler for this interrupt transfers data from the network controller's memory, over the bus, to the bounded buffer in memory, and modifies some bookkeeping data associated with that buffer.
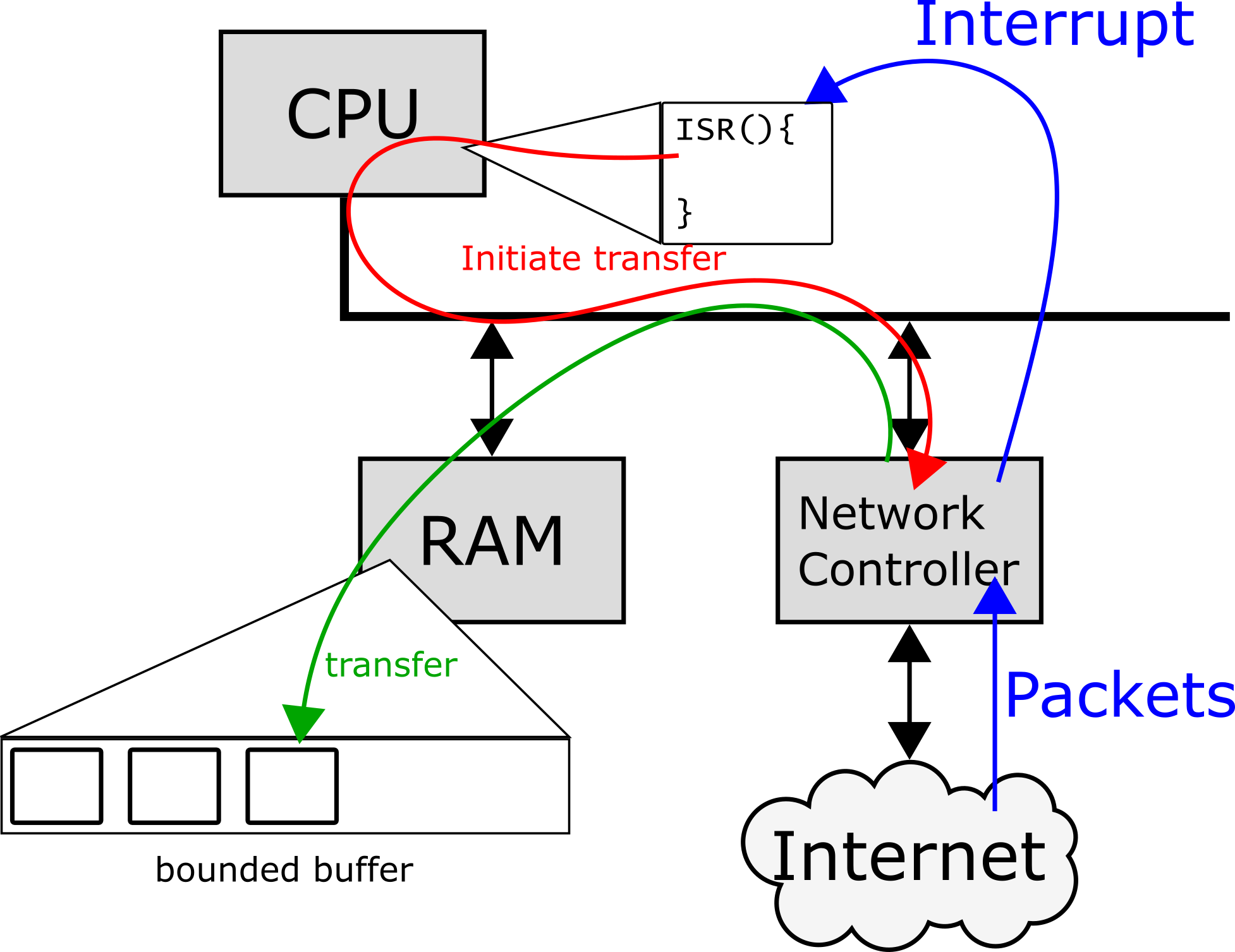 As the interrupt blocks the main execution context of the processor (interrupts are always of higher priority), the CPU spends all of its time handling interrupts, and the service meant to process the received data starves. This results in the following behavior:
As the interrupt blocks the main execution context of the processor (interrupts are always of higher priority), the CPU spends all of its time handling interrupts, and the service meant to process the received data starves. This results in the following behavior:
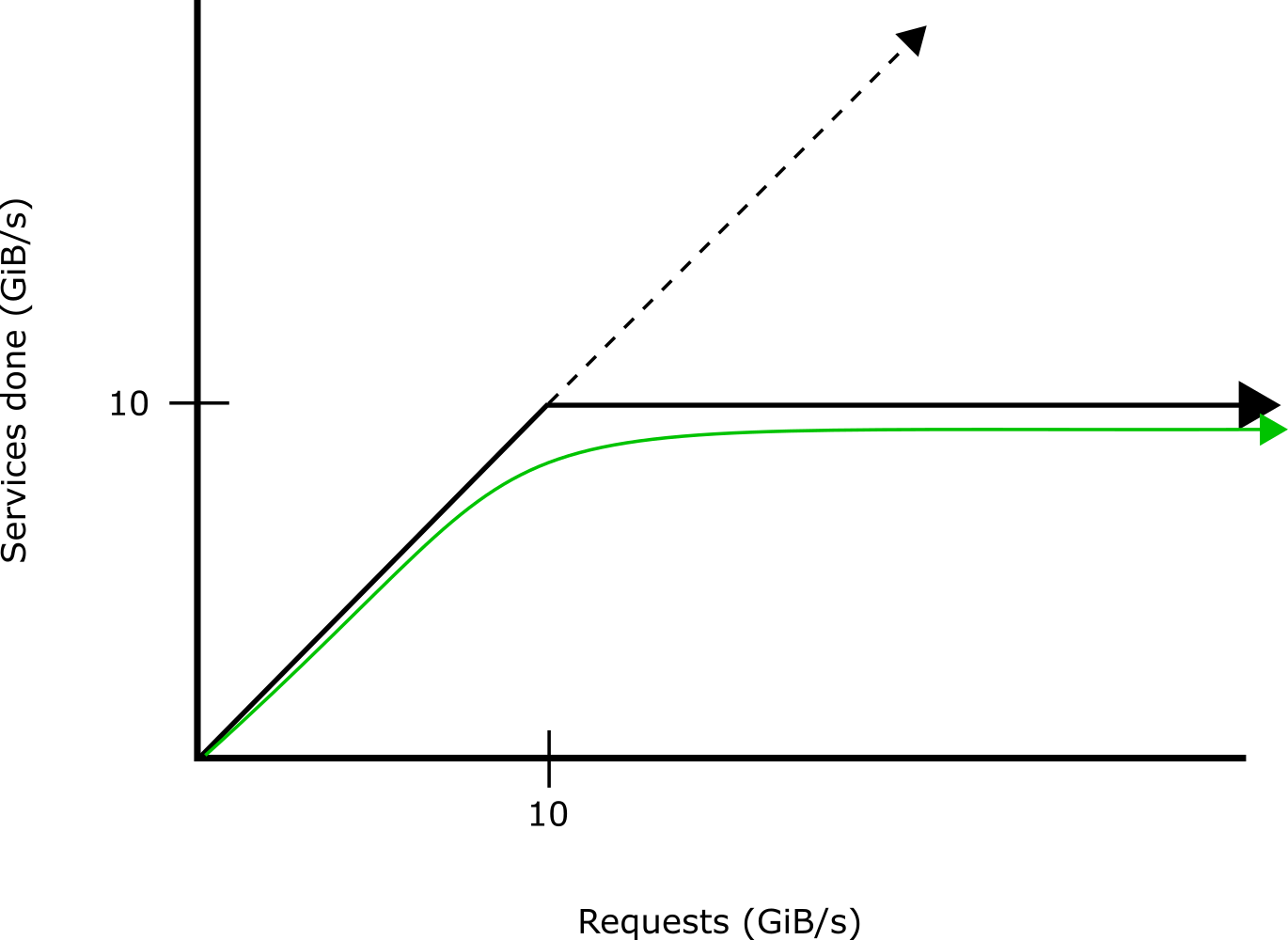
To solve this problem, the interrupt handler can mask its interrupt when the buffer fills. As the handling service cannot process more than 10 GiB/s anyway, there is no point in reading in data it will not be able to use. Once the service empties the buffer sufficiently, it can unmask the transfer interrupt, and more data from the network controller can be read into the buffer. This results in the following better behavior:
Event-Driven Programming
Suppose that we want to eliminate locking altogether, as the whole concept of locks is a bug magnet. We still want to prevent races, and we still want to be able to perform multiple tasks. This can be achieved with an operating system paradigm called event-driven programming.
In the thread model, there are concurrent threads that take control of the processor in turn to do some computation, and the kernel handles switching between them and managing their resources.
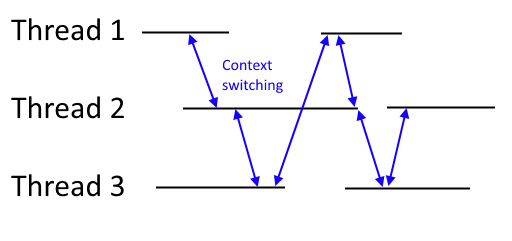 In an event-driven model, there is only one thread of execution (the main thread), and its sole purpose is to execute handlers for various events.
In an event-driven model, there is only one thread of execution (the main thread), and its sole purpose is to execute handlers for various events.
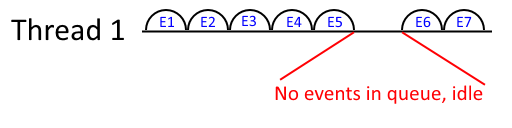 One such implementation could consist of a main loop that removes the first element from a queue of waiting events, and runs the associated handler. Once the handler returns, it proceeds to run the next handler in the queue, and so on. Events are scheduled to run by interrupt handlers, which are directly triggered by hardware interrupts.
One such implementation could consist of a main loop that removes the first element from a queue of waiting events, and runs the associated handler. Once the handler returns, it proceeds to run the next handler in the queue, and so on. Events are scheduled to run by interrupt handlers, which are directly triggered by hardware interrupts.
For a system built this way to operate effectively:
- handlers must never wait
- handlers must finish executing quickly (so as to not starve the other waiting handlers of CPU time)
Priority can be realized by selecting where in the queue to place a newly scheduled handler; a keyboard handler, for example, would be scheduled at the head of the queue, whereas a handler for a sleep timer might be scheduled at the tail of the queue.
There is a reason why this approach is not ubiquitous now. An event-driven processing model like the one described cannot scale to multi-core systems (see note) because it assumes that no other actor can modify a data structure that a handler is currently accessing. This is not the case in a system where there are multiple CPUs running concurrent threads that are accessing shared data. However, in single-core applications, this paradigm is very effective, and is therefore popular in low-power embedded systems.
Note: a multi-core system can use the event-driven model assuming that there is strict memory segregation between the different threads (no two event loops access the same data structure). Large clusters can also be realized by having individual CPUs running event loops communicate with one another over a network.
Filesystem Performance
Suppose that we have a processing cluster with a combined storage space of 120 PB (Petabytes), or 120,000,000 GB, distributed over a collection of 200,000 hard disk drives (each one having 600 GB of storage space, spinning at 15kRPM). Suppose also that this storage space is formatted to use a filesystem called GPFS.
Filesystem Topology
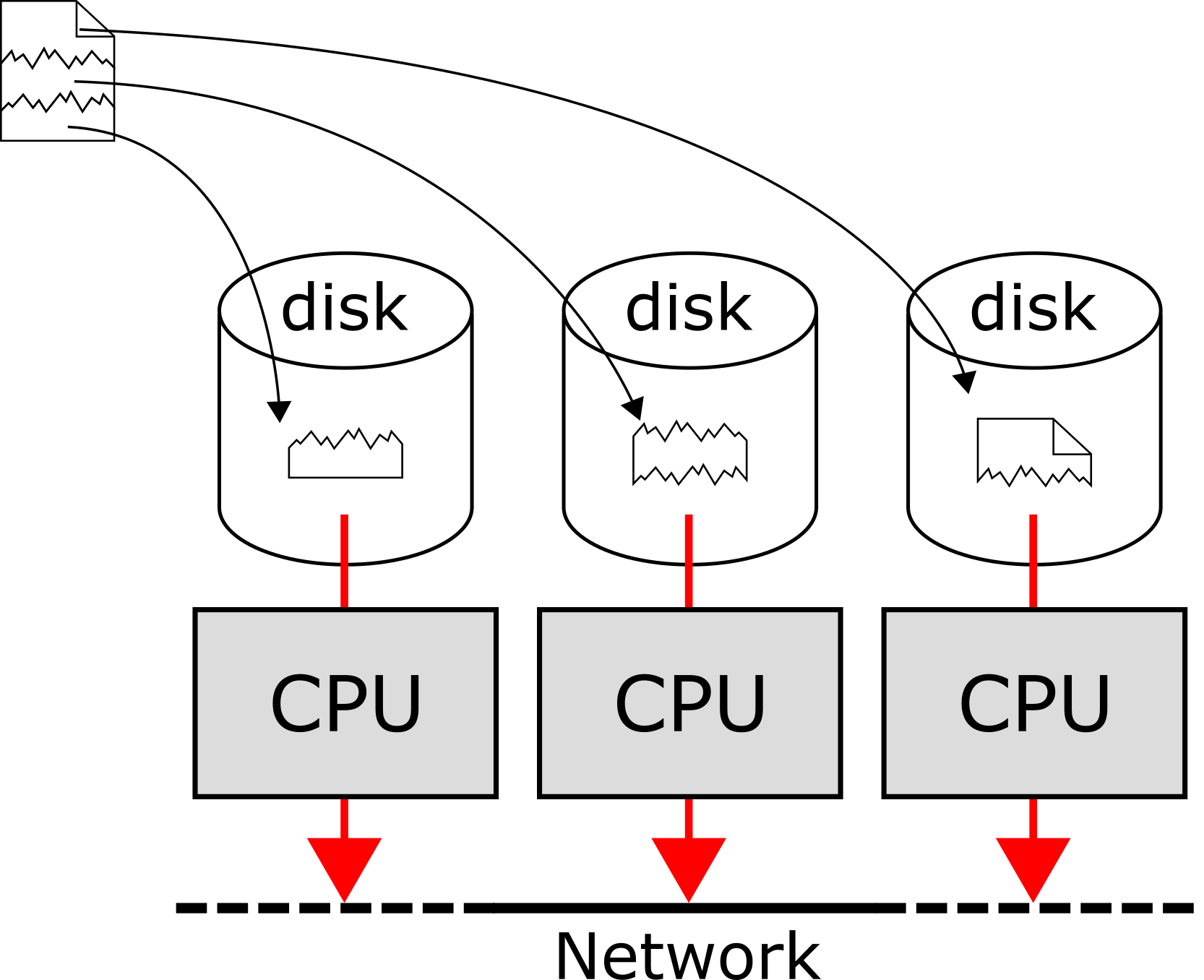
Let's think of some topologies for this system. Suppose that all of the drives are connected to one bus, and are managed by one CPU:
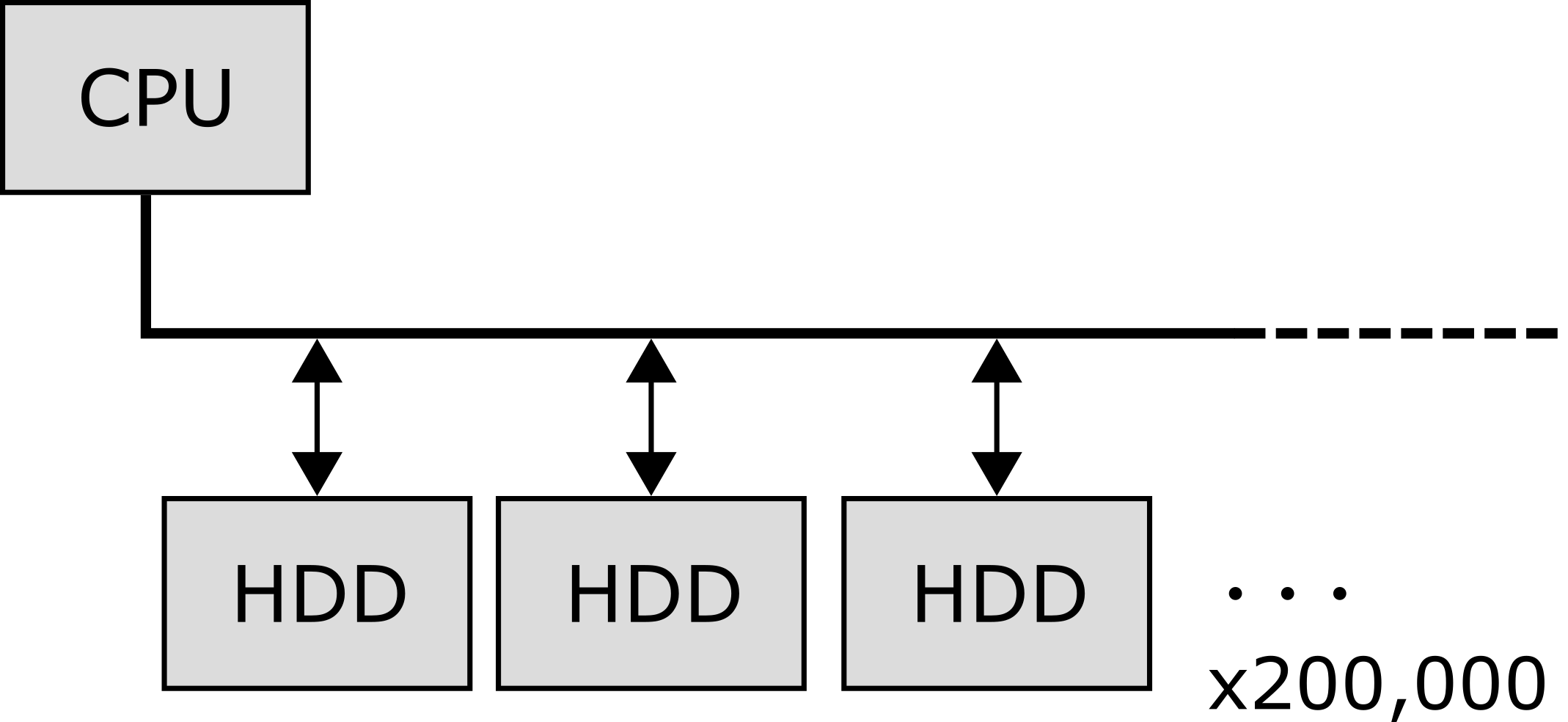 This topology is not going to fly. The bus bandwith is an enormous bottleneck here, and one CPU cannot perform parallel operations fast enough to make effective use of the massive amounts of data immediately available to it.
This topology is not going to fly. The bus bandwith is an enormous bottleneck here, and one CPU cannot perform parallel operations fast enough to make effective use of the massive amounts of data immediately available to it.
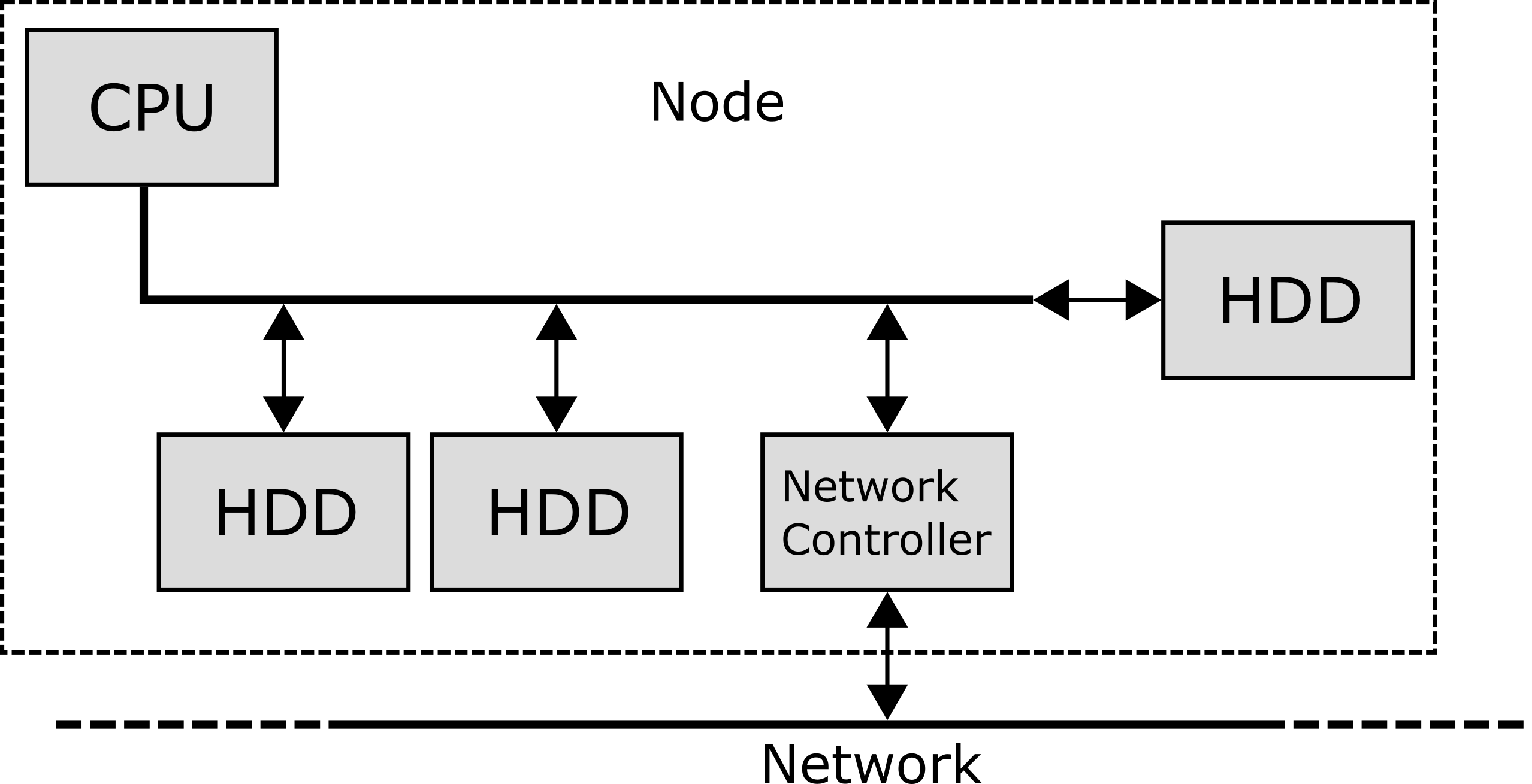
Suppose instead that there is a network node with a similar topology, albeit far fewer drives, and that the cluster is composed of thousands of such nodes interconnected through a network:
File Striping
How would we store files on such a system? Suppose that there is a 500GB file somewhere in the cluster that we want to access. One approach is to have the file located on one physical disk somewhere in the cluster, and have the associated CPU read the file out to the network as fast as possible for some other CPU to access:
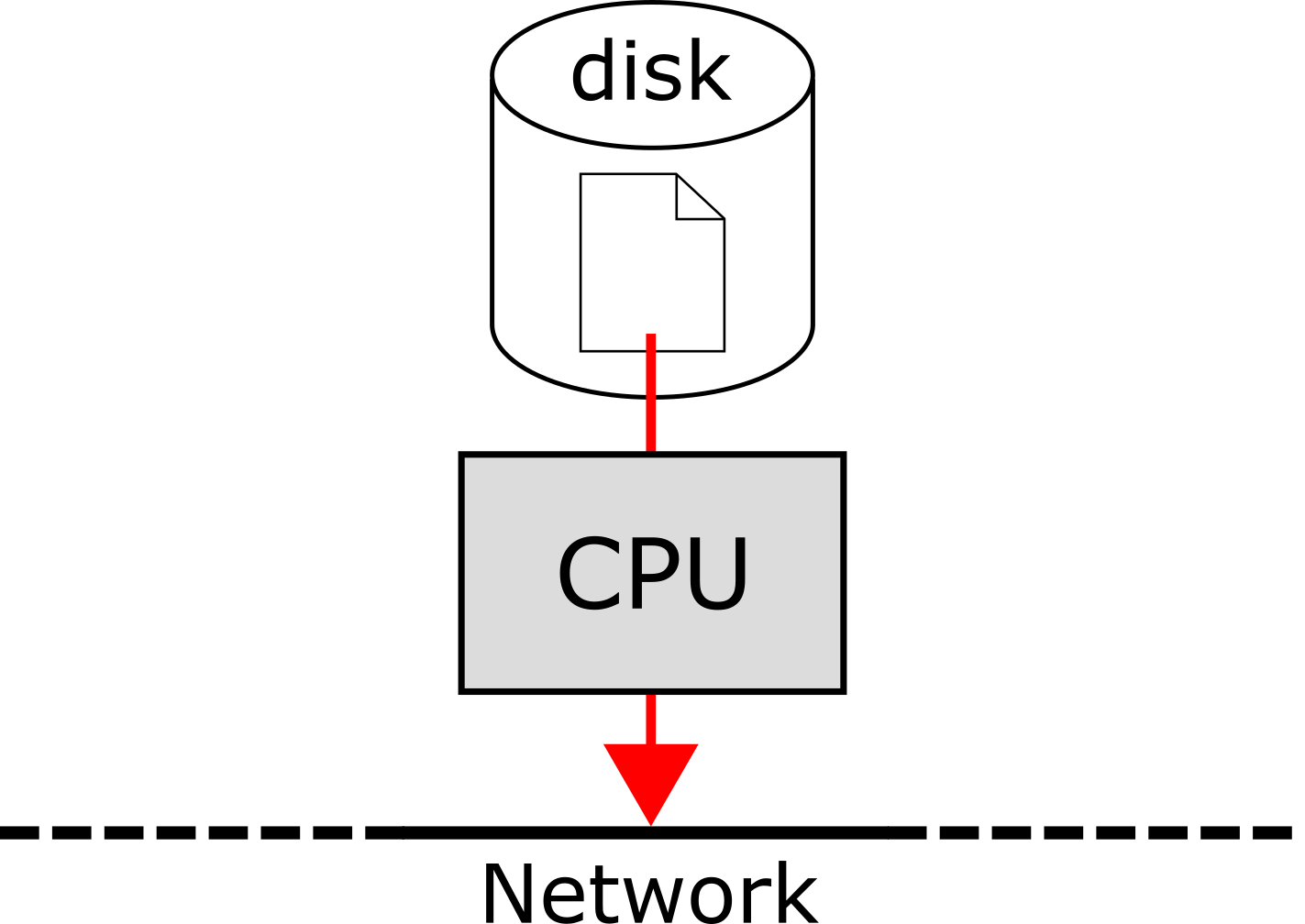 However, the speed of transfer is bottlenecked by the speed of the disk itself, and a 500GB file will take a very long time to access in this manner. A better approach is to store parts of the file on separate drives located in separate nodes of the cluster. This way, the operation of accessing the file can be divided amongst many CPUs, busses, and disks running in parallel, widening the bottleneck:
However, the speed of transfer is bottlenecked by the speed of the disk itself, and a 500GB file will take a very long time to access in this manner. A better approach is to store parts of the file on separate drives located in separate nodes of the cluster. This way, the operation of accessing the file can be divided amongst many CPUs, busses, and disks running in parallel, widening the bottleneck:
 This approach is known as striping. In order for this approach to work, we need to know where the parts of the file are; this gives rise to the concept of a directory node. The directory node is responsible for keeping track of and servicing requests for the locations of file contents. However, if there is only one directory node, accessing the directory becomes the bottleneck for the system, rather than accessing the files themselves. To solve this, a distributed directory system can be employed, and there can be distributed metadata for the files (last-modified time, size, etc.).
This approach is known as striping. In order for this approach to work, we need to know where the parts of the file are; this gives rise to the concept of a directory node. The directory node is responsible for keeping track of and servicing requests for the locations of file contents. However, if there is only one directory node, accessing the directory becomes the bottleneck for the system, rather than accessing the files themselves. To solve this, a distributed directory system can be employed, and there can be distributed metadata for the files (last-modified time, size, etc.).
Indexing
We would also like a way to efficiently index the directory. One possible approach would be to store a list of the files in a given directory as an array; this does not scale well, however, as a directory containing a large number of files would take a long time to search and modify the contents of. A better approach would be to store the index of the directory in a binary tree, as it would be inherently ordered and therefore easy to search, and easy to modify. However, a binary tree only has two children per node, whereas a directory can have many children. A better approach still would be to maintain a B+ tree of the files and folders, as a B+ tree has a high fanout (capable of matching the fanout of entries in a directory, for example), and is therefore suited for organizing filesystem data.
Distributed Locking
We also need a way to make changes to files that is both atomic, and distributed. For example, if one process attempts to append a line to a file, and another process simultaneously requests the contents of that file, the reading process should either see the file before the change, or the file after the change. This results in a need for a way to lock files for processing (marking them locked or unlocked in their metadata), and a need for those metadata updates to be available to all processes accessing the filesystem in a timely manner.
Partition Awareness
The distributed filesystem also has to be aware of partitions, whether intentional or accidental. Suppose, for example, that we have a distributed filesystem shared between the physics and engineering departments at UCLA. Some nodes are located in Boelter and others are located in the physics buildings, and they are wired together by a network line that runs between them. Clients exist outside the network that access data in the filesystem by talking to perimeter nodes. The topology of the network might look like the following:
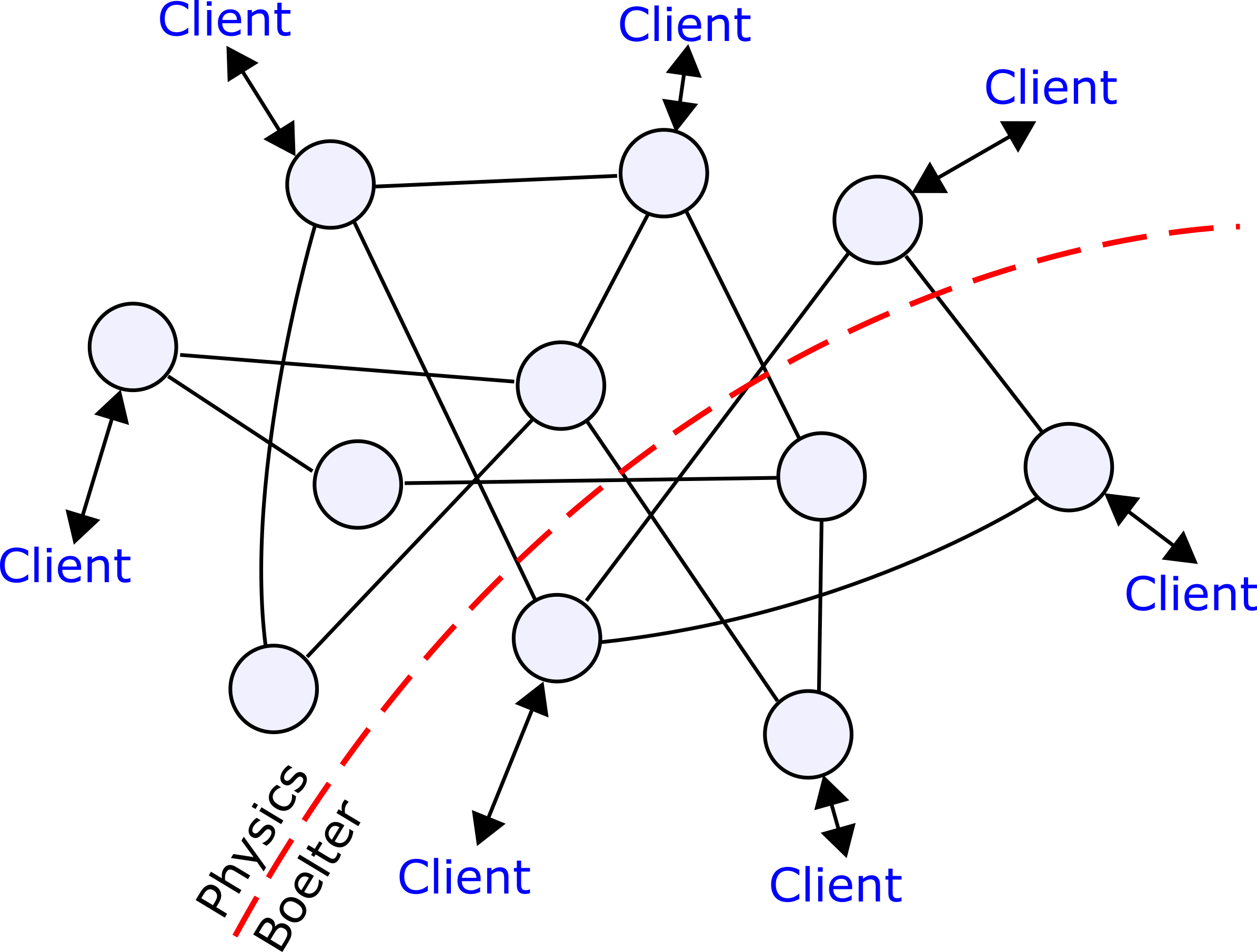 Suppose that some construction is being done in the Court of Sciences, and a backhoe cuts the line between Boelter and the Physics department, essentially partitioning the network into two pieces:
Suppose that some construction is being done in the Court of Sciences, and a backhoe cuts the line between Boelter and the Physics department, essentially partitioning the network into two pieces:
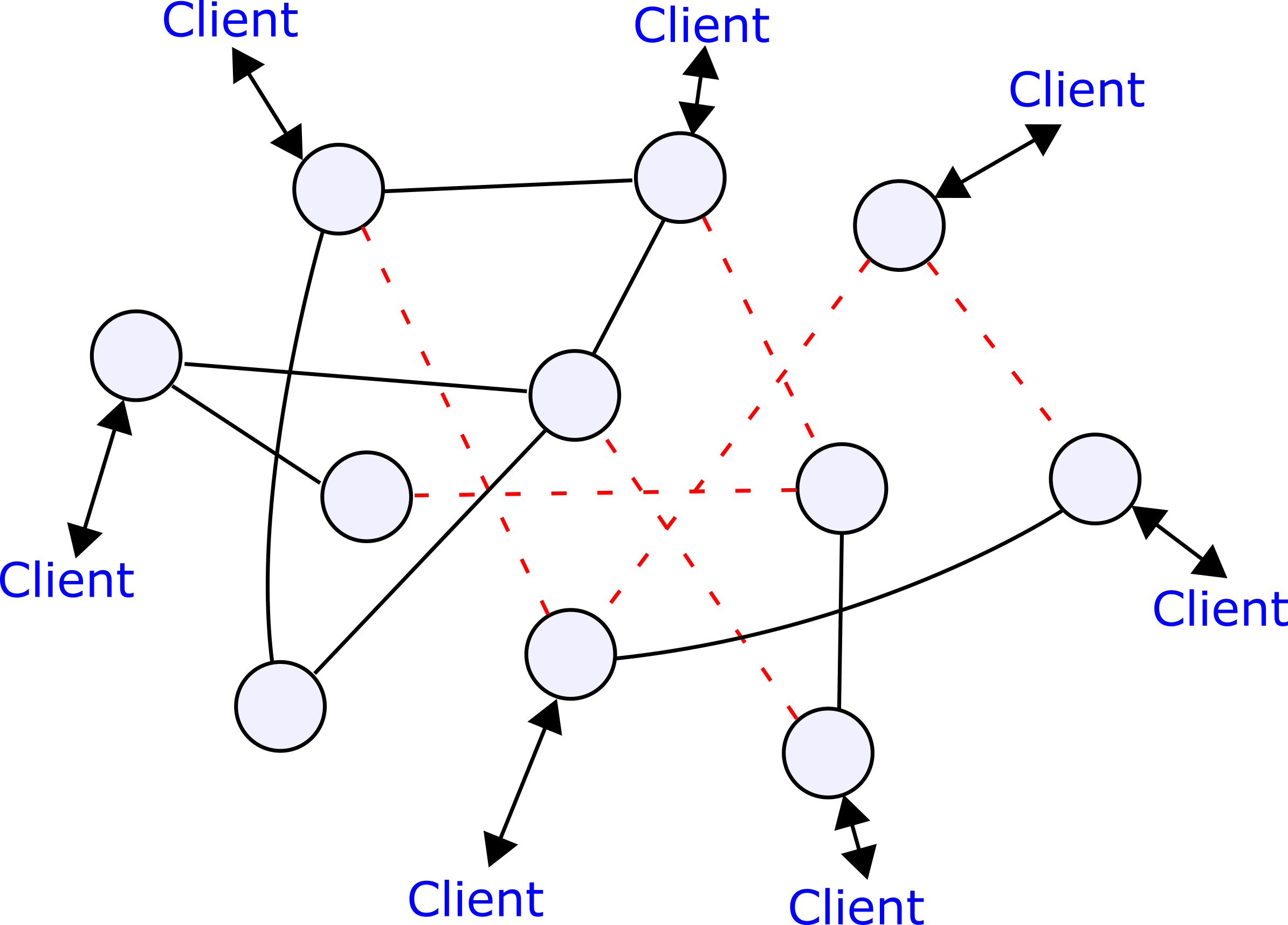 How will the filesystem respond? A conservative approach would be to stop all filesystem transactions immediately. However, this might upset users of the system, especially if one of the resulting network partitions is a very small part of the larger system. Another approach is to count the number of nodes in each of the resulting partitions, and freeze write transactions on those partitions that make up less than half of the total node count. Reads can resume on all parts of the network, and modifications can be performed on the data held in the majority partition. Once the network is reconnected, the lesser partitions and their clients can synchronize with the majority partition without conflicts.
How will the filesystem respond? A conservative approach would be to stop all filesystem transactions immediately. However, this might upset users of the system, especially if one of the resulting network partitions is a very small part of the larger system. Another approach is to count the number of nodes in each of the resulting partitions, and freeze write transactions on those partitions that make up less than half of the total node count. Reads can resume on all parts of the network, and modifications can be performed on the data held in the majority partition. Once the network is reconnected, the lesser partitions and their clients can synchronize with the majority partition without conflicts.
I/O Performance Review
We want to build a high-performance filesystem and therefore must understand the I/O performance of various storage devices. There are two primary forms of storage today: disks, and flash memory.
-
Disks have:
- Rotating platters = rotational latency: e.g.: 7200 RPM -> 120 Hz -> 8.33 ms/revolution -> average-case latency = 4.17 ms
- Mechanical read head = seek latency
- Mechanical components = prone to failure
-
Flash has:
- No moving parts = fast transfer, low latency, low failure rate
- Limited write cycles/sector
Tens of millions of instructions can be executed in the time it takes a rotating disk drive to reach the data you asked it for, so how can we keep system performance high when there is such a mismatch in the speed of our various devices?
The following table compares the specifications of two different hard drives, a Seagate HDD, and a Corsair SSD:
| Seagate Barracuda LP 2TB | Corsair Force G.T. | |
|---|---|---|
| Capacity | 2 TB | 60 GB |
| Speed | 7200 RPM | N/A (no moving parts) |
| Avg. Read Time | 5.5 ms | N/A (no moving parts) |
| Transfer Rate | 300 Mb/s | 300 Mb/s |
| Sustained Data Rate | 95 Mb/s | 280 MB/s read, 270 MB/s write |
| Cache Size | 32 MiB | N/A |
| Sector Size | 512 B | 512 B |
| Read Error Rate (Non-recoverable) | 10e-14 | N/A |
| Annualized Failure Rate | 0.32% | 0.88% (from MTBF 1e6 Hrs.) |
| Avg. Operating Power | 6.8 W | 2 W (max) |
| Avg. Idle Power | 5.5 W | 0.5 W |
| Startup Current | 2 A | |
| Operating Shock | 70 G | 1000 G |
| Non-operating Shock | 300 G | N/A |
| Acoustic Noise | 2.6 Bels | N/A (virtually silent) |
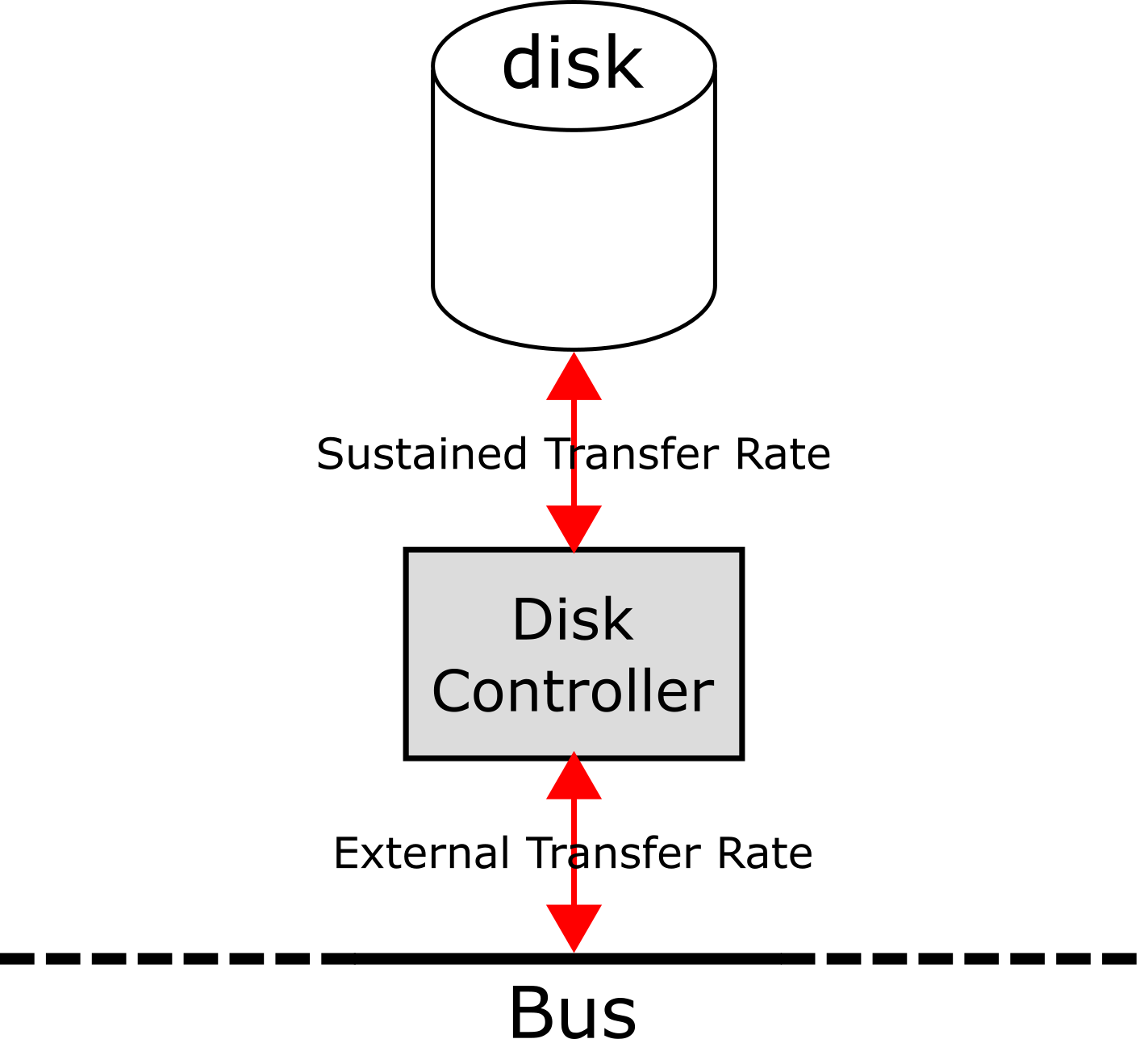
The external transfer rate and the sustained data rate are different quantities; the external data rate is the speed at which data from the disk controller cache can be read out over the bus, whereas the sustained data rate is the speed at which the disk controller can retrieve data from the physical medium:
Flash Wear-Leveling
Flash, specification-wise, appears to be much better than hard disks. However, its main deterrent stems from its limited write-cycle count. Each sector in a flash disk can only be written a certain number of times before failure. This number is somewhere in the hundreds of thousands, and therefore will cripple a drive if care is not taken to ensure that sectors get written to evenly. This procedure is known as wear leveling. A wear-leveling mechanism can be implemented by maintaining a table of mappings from virtual disk sectors to physical disk sectors, and moving virtual sectors to new physical sectors as the write count on them increases so as to balance the write load:
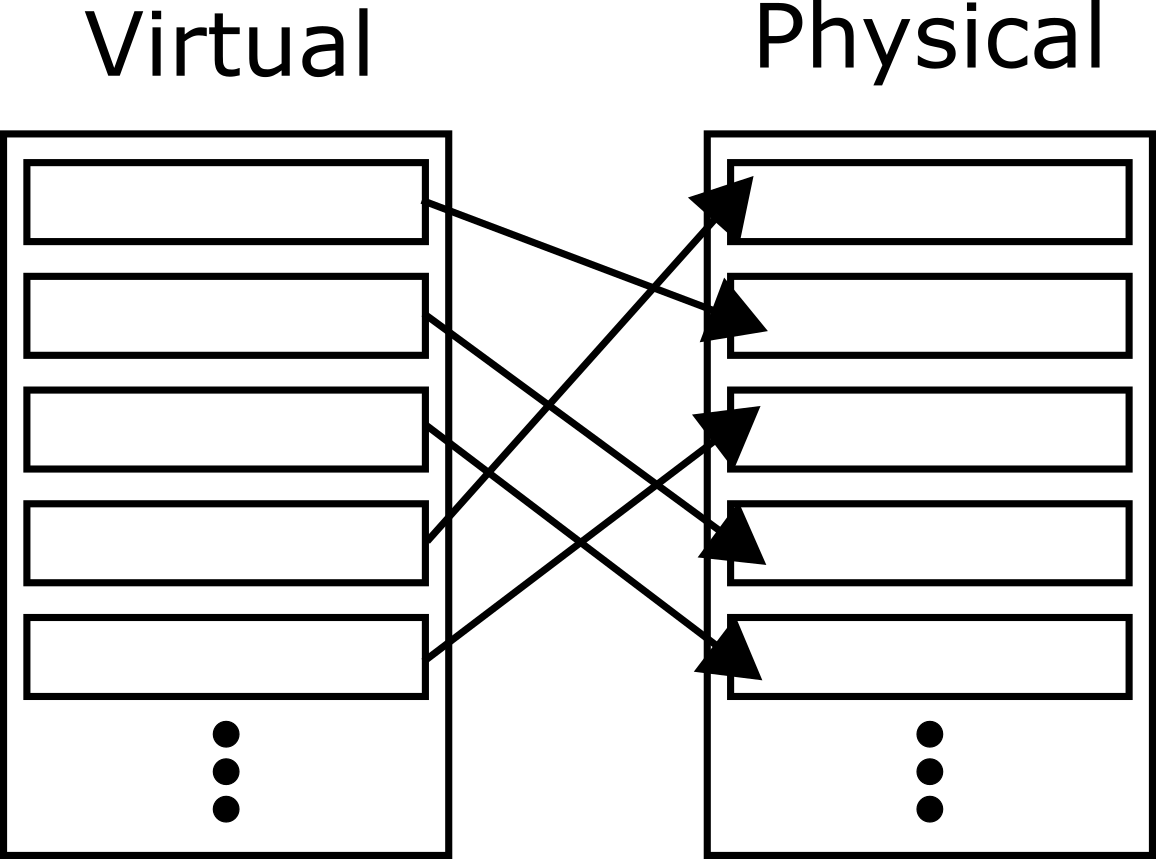 However, the mapping needs to persist between system power cycles; to solve this, a sector can be allocated as the index. Any modification to the contents of the disk that results in a remap will mean that the map itself will have to be rewritten, and the index sector will have to be moved!
However, the mapping needs to persist between system power cycles; to solve this, a sector can be allocated as the index. Any modification to the contents of the disk that results in a remap will mean that the map itself will have to be rewritten, and the index sector will have to be moved!

Filesystem Scheduling
At any given point in time in your O.S., there is a set of requests pending for each disk or flash drive:
| R/W | Offset | Length |
|---|---|---|
| R | 1456 | 96743 |
| W | 1337 | 5335111 |
| W | 99865 | 296732 |
| R | 98583 | 19603 |
How should the O.S. schedule these requests so as to best utilize the disk? Taking a hard disk drive as an example, average case performance will be very poor with unordered requests, because the requests will likely not be for data on the same sectors or tracks, and will require the disk to seek a lot to service them in the order they are issued. The cost of performing a read or write can be modeled as proportional to the distance between the read head and the sector in question:
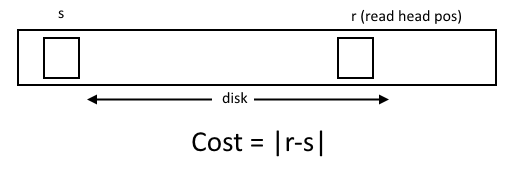 A better approach would involve sorting the requests by location so as to be able to serialize access to the sector and increase throughput. Is this a good approach? Can we do better?
A better approach would involve sorting the requests by location so as to be able to serialize access to the sector and increase throughput. Is this a good approach? Can we do better?