CS111 Lecture 10: File system performance
Notes by McKenna Galvin and Neil Bedi
Synchronization cont’d
Going faster
It would be nice if we could get our spinlocks to go faster, in particular the primitive xchgl that slows things down.
On Haswell architectures (and others, but not SEASnet), the Hardware Lock Elision does the locking, but it “cheats” to get performance. On x86, it executes the xchgl instruction, but with a new prefix, xacquire, that modifies the way xchgl behaves:
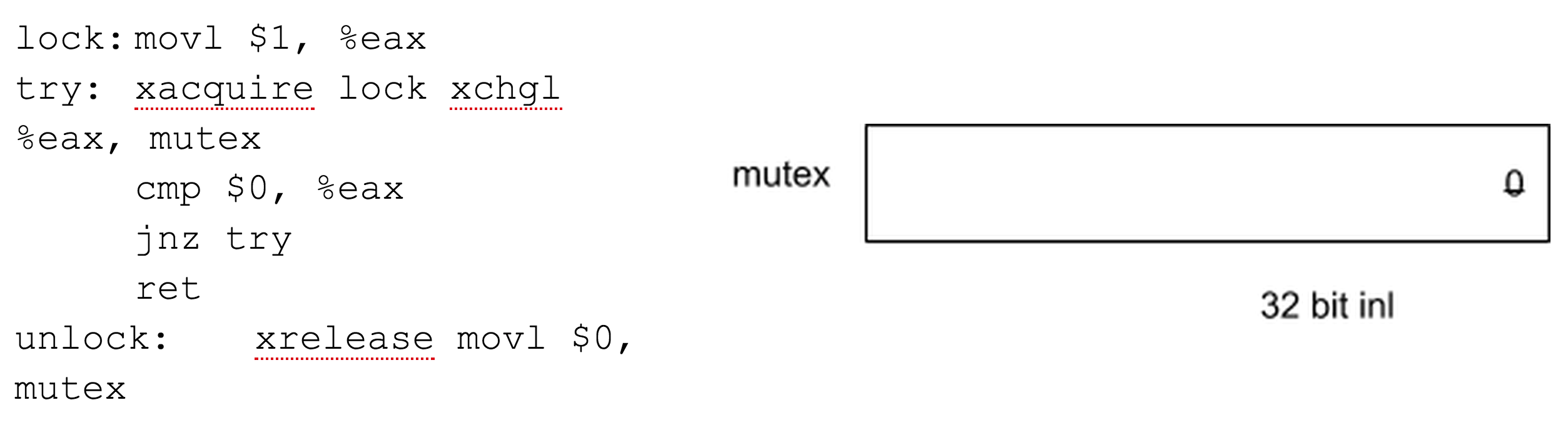
With the Hardware Lock Elision, multiple threads can execute critical sections protected by the same lock if they aren’t performing operations that could conflict. The “xacquire” prefix allows this to occur.
Further reading
Deadlock
Simple primitives like deposit/withdraw won’t deadlock because they do very simple tasks. However, we can get into trouble when we deal with more complicated code. For example, consider the following transaction:
transfer($3, acct #19, acct #27);
An implementation of this transfer function might involve locking both account 19 and 27. But say you have two threads which are each calling transfer() and are trying to lock the other’s accounts, so they spin forever. You can’t prevent this problem by using hardware locking or condition variables, so this is a classic deadlock example.
Deadlock is a global property of your system, and it’s not obvious by looking at one part of the code that it will be dangerous. These properties are like death in operating systems because it’s not immediately apparent that there’s an issue.
We’ve seen examples of global, non-obvious problems before (e.g. race conditions). By trying to handle race conditions, we’ve introduced so many locks that we’ve made another race condition. Deadlocking is a race condition!
Necessary conditions for deadlock:
- Mutual exclusion: Only one thread can use a resource at a time
- Circular wait: For example, thread 1 waits on thread 2 while thread 2 waits on thread 1, creating a loop
- No preemption of locks: A thread can’t just kick another thread off the lock – it must happen voluntarily
- Hold & wait: When one thread holds a resource and waits on additional resources that are held by other threads
If you can cross out any one of these 4 things, you won’t have deadlock.
Solving the deadlock problem
- Detect deadlocks dynamically
-
- Have the operating system keep track of the process, every resource it holds and every resource it tries to hold
- If lock() fails with errno = EDEADLOCK, it means we can’t get the lock now because it would cause a deadlock
- With this approach, applications no longer have to worry about deadlock
- Redesign so that deadlocks can’t occur (without losing synchronization) using lock ordering
-
- Assume that locks are ordered (you can use the address of the lock to determine which one comes before another)
- Acquire the locks in order
-
- If successful, we are okay
- If one is unsuccessful, unlock everything and retry
Priority Inversion
Priority Inversion is another global, non-obvious connection between locking and scheduling that can cause a host of problems.
Suppose you have three threads, L, M, and H of low, medium, and high priority, respectively, that all need to use a resource. If L is currently using the resource and H wants to use it, H will be blocked because L still has the lock. In an ideal world, we’d like to have H get immediate control of the lock when L is done. However, suppose M also becomes runnable when L is still using the lock. Because M is higher priority than L, the resource could be given to M, so H would not get the chance to use the resource.
This problem actually occurred with JPL’s Mars Pathfinder in 1997. So how would we go about solving this issue?
Lock preemption could work, but is too disruptive. It would boot processes working with fragile data structures and lose their work. So instead, as a fix we could temporarily assign H’s priority to L while it’s executing so that M doesn’t step in afterwards (since H > M).
Livelock
Livelock occurs when threads are running (i.e. not blocked), but you’re still not making progress. It’s similar to deadlock, and to some extent, it’s even more insidious than deadlock because it is hard to debug since everyone seems like they’re getting work done.
The following illustrates an example of livelock:
Assume we have a bounded buffer which takes requests from the outside world at a high rate, but our system can only handle requests at a lower rate. As long as there isn’t too much network traffic, we’re fine because we can just queue requests.
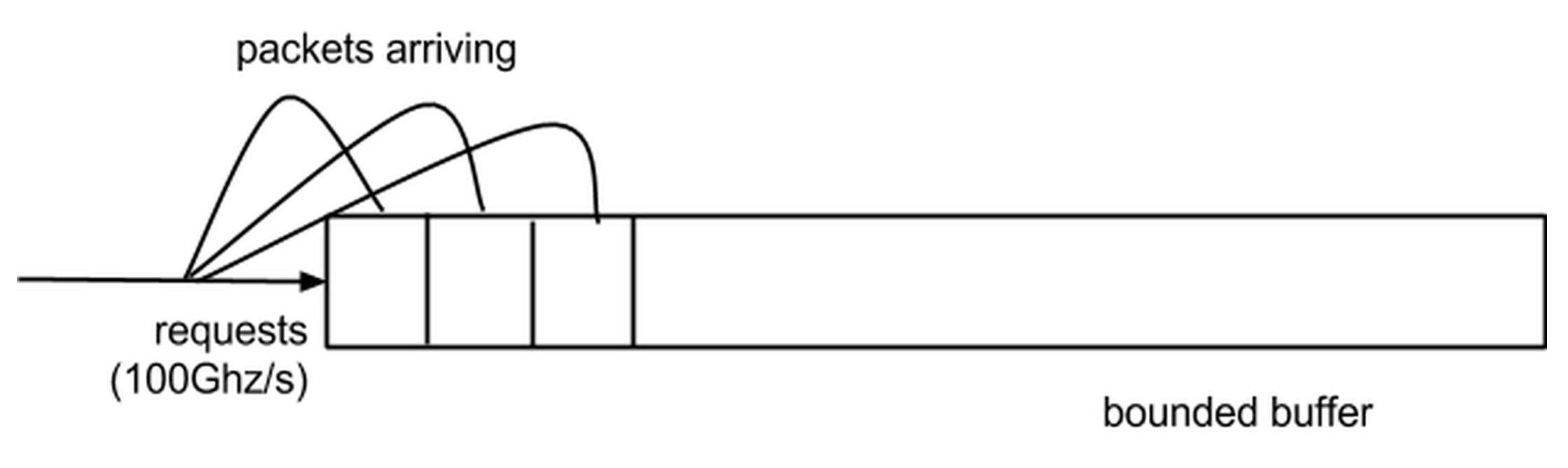
In a lot of cases, though, we won’t be able to handle all of those requests. To process these requests, we need to do the computation in addition to handling interrupts. In the normal way of treating it, interrupts will have higher priority, because you don’t want to lose the data. So we’ll have to sacrifice some of that CPU time for handling interrupts, and performance stinks because you end up wasting a lot of CPU time stuffing things into memory that you’ll never get to.
Ideally, we’d like to spend as much of our CPU time doing valuable work. We can achieve this by masking interrupts once the buffer is full, and allowing interrupts again when the buffer is empty.
Event driven programming
Locking code is a hassle – there’s a huge potential for bugs, and it can be extremely confusing. Is there any way to prevent race conditions without dealing with the pain of locking code?
As it turns out, there is a way to achieve this. It is called event driven programming.
The basic idea of event driven programming is to first throw out the idea of threads. We still want to be able to deal with asynchronous events, but we won’t use threads for this. Instead, we organize our computation into a series of events, so that our program is a set of event handlers. At runtime, the system maintains a priority queue of incoming events and runs each event handle. Each event handler never waits; the goal is for it to just finish quickly.
The advantage of this approach is that each event handler is a critical section, so nobody can take over. Unfortunately, however, this approach doesn’t scale to multiple cores, so we don’t use it.
File systems
We’ll now switch gears and discuss file systems. File systems control how data is stored and retrieved.
One example of a file system is the IBM General Parallel File System (GPFS), which is a high performing file system with 120PB of data and 200,000 hard drives [each 600GB, 15kRPM]. The drives are small for cost reasons and because smaller drives allows more parallelism.
Because we can’t fit all 200,000 hard drives, we’ll instead package a few into a group called a “node” and have a network of nodes. A network is a bunch of computers working together to provide the illusion of a single computer with this large file system.
Features of the GPFS file system
- Striping: Take the data and partition it into different blocks, so that parts of the file are distributed across the system
- Distributed metadata: Say we picked one node to be the “directory” node that keeps track of the locations of all the files. Requests would be sent to the directory node, which would then direct you to the appropriate location. There’s a problem with this, however, because everyone is always going to want to be communicating with that directory node. So instead, we distribute the metadata so there’s no single directory controller in charge of the system.
- Efficient directory indexing: We use a B+ tree (a balanced tree that’s very “bushy”) as our data structure for indexing the directory
- Distributed locking: The ability to use something like a blocking mutex, but it doesn’t just live in RAM, it lives in the whole CPU and everyone respects it
- Partition awareness: If part of the network fails and the file system is partitioned, some machines will remain working
I/O performance
Hard disk vs. flash
A hard disk is cheaper per byte, but with flash, the random access means it will be faster.
The problem with hard disks is that they are spinning magnetic disks with the read head waiting at the same spot, so there is latency:
- Rotational latency: you have to wait to spin to right spot
-
- 7200 rpm = 120Hz, so 1/120sec rotational latency in the worst case
- 1/240 sec in the average case
- Seek latency (also called read head latency) from the head moving between the center and edge of the disk to be at the right spot
Let’s compare the specs of a particular hard disk vs. flash memory:
Seagate Barracuda LP 2TB hard disk
- 5900rpm
- 5.5ms avg. latency (if you want to talk to this drive, it will take you 5.5ms to read from the drive. In 5.5ms you could perform billions of instructions, a clear mismatch in performance with the CPU!!)
- 300 Mb/s external transfer rate (rate at which it can talk from the cache to the bus)
- 95 Mb/s sustained data rate (rate at which it can talk from the disk to the cache, we ideally want this to pump out data as fast as possible)
- 32 MiB cache
- 512 bytes/sector
- 50,000 contacts starts/stops
- 10^-14 non-recoverable read error rate
- 0.32% AFR (Annualized failure rate - means that the disk drive has fried)
- 6.8 W average operating
- 5.5 W average idle
- 2A startup current (12V peak)
- 70G operating shock (can take 70G of force while it’s operating)
- 300G nonoperating shock (when it’s turned off, you can shake it even more)
- 2.6 bels acoustic noise
Corsair Force GT - Flash
- 60 GB
- 300 Mb/s transfer rate
- 280 Mb/s read
- 270 Mb/s write
- 1000G operating shock
- 2.0 W max
- MTBF 1,000,000 hrs
A downside of flash is that it wears out. For this, there is a common technique called wear leveling. The flash controller will effectively “lie” about where it does the writes. You think you’re writing to block x but it instead moves it to another block to negate/spread out hot spots (areas where blocks are written more often).
Historically, flash drives have a very bad reputation for reliability because amateurs write the wear leveling code. So it’s fast, but you might lose all your work if you choose a drive with bad wear leveling code.
Scheduling
At any given point in time, your OS will have a set of requests for each disk or flash drive. Your job as a scheduler is to decide which to do next.
Suppose we use the simplest scheduling algorithm that we used for CPUs to apply to disk: first come, first served! Assume that we have an abstract device which acts like a disk (meaning seeks are required), and assume that the cost required is proportional to the distance.
Question for next time: Is first come first serve a good algorithm for disk drives?
(The answer is no.)