Our current method for synchronization is slow, especially spin locks. Another issue is that the primitive, xchgl is pretty slow. How do we speed things up? Hardware Lock Elision was introduced by Intel on the Haswell microarchitecture iteratation, implementing new instructions, xacquire and xrelease. These instructionsare similar to locking but provide better performance.
Using xacquire to set a lock:
lock: movl $1, %eax try: xacquire lock xchgl %eax, mutex cmp $0, %eax jnz try ret unlock: xrelease movl $0, mutex
xrelease movl $0, mutex
Deadlock occurs when two processes are waiting on the same resource, resulting in nothing happening. Deadlock is a global property of a system, and it is not obvious if deadlocking will occur when first looking at a piece of code. This is hard to deal with! The problem is not necessarily isolated to one piece of code. Dealing with deadlocks are like dealing with race conditions. By fixing one set of race conditions by adding locks, we've introduced more race conditions (deadlocks).
deposit($3, acct#29); withdraw($4, acct#29);But if you introduce a transaction that can transfer money between two accounts:
transfer($3, acct#19, acct#27);This can result in a deadlock! This occurs because one thread can be trying to transfer money from one account, while another thread is transfering money to the same account! Thread 1 will lock the account, and thread 2 cannot access it.
lock() can fail if you attempt to lock something that has already been locked. A solution would be to have it fail with some errno. The downside to this is that all applications would have to be modified to deal with knowing that there is a deadlock.
The example in class used a lock ordering algorithm. In the example, you are writing a primitive-like transfer function that needs to get more than one lock. Assume that it has the following structure:
typedef int lock_t; lock_t a,b;
In linux, you can produce an order by simply looking at the addresses of the locks a and b. The algorithm would acquire locks in order, and if one attempt to lock is unsuccessful, then release every lock and try again.
Priority inversion occurs when mutually exclusive resources are held indefinitively by low-priority processes as a result of higher-priority processes waiting to acquire them. The failure of the Mars Pathfinder in 1997 was the result of such a problem.
Suppose that there are three threads with priorities low, medium, and high. At first the low-priority thread is runnable, and the medium-priority and high-priority threads are both waiting. The low-priority thread will grab and lock a common resource. While it has a lock, the high-priority thread becomes runnable, and the CPU switches the context to the high-priority thread, which cannot run because of the the low-priority thread's lock on the common resource. The high-priority thread then has to wait. In an ideal situation, there should be a context switch to the low-priority thread such that it gives up its resource. However, if the medium-priority thread becomes available before the context switch, the medium-priority thread runs. Ultimately, the high-priority thread cannot run.
How do we fix this problem? When a lower-priority thread has a lock on an object that a higher-priority thread is waiting for, let the lower-priority thread borrow priority, such that the context switch will go back to the lower-priority thread.
Livelock is similar to deadlock, except that the states of the threads or processes constantly change with regard to one another and no progress is made. For example, assume there is a bounded buffer that takes requests from the outside world coming in at 100 Gb/s, but service operates at 10 Gb/s. As long as traffic isn't intensive, there are no problems, but as traffic does get big, we have a problem.
What we want is performance to be linear until 10 Gb/s and then level out after that. However, when you receive a packet, it comes in the form of an interrupt which is high priority and temporarily takes over the CPU. This decreases performance because at times of higher traffic, CPU must constantly handle interrupts which prevents adding requests to buffer.
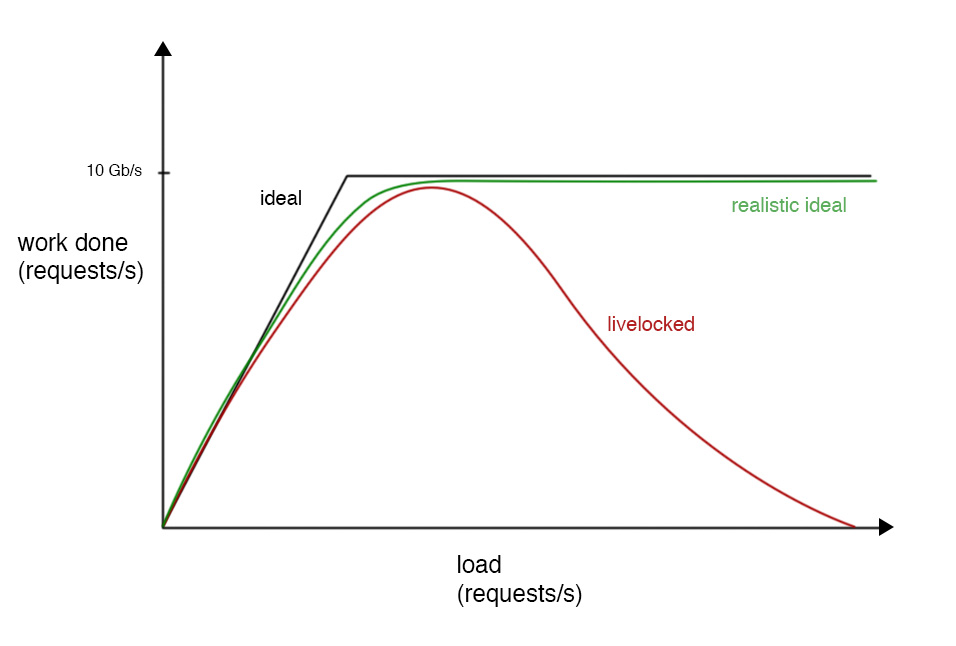
Solution: When the buffer fills, mask out interrupts and when it is less full, reenable them.
Event-driven programmingi is often used in embedded systems. There is only one thread, but computation is broken into a series of short events that are completed in their entirety at time of execution. At runtime, the system maintains a priority queue of incoming events. The main loop pulls an event from the queue, executes, and then grabs another.
The iron rule: event handlers do not wait for anything. They simply execute and then exit.
The advantage to event-driven programming is that each event is a critical section, given for free. There is no need for locking and unlocking because there is no resource can be taken over when you are in an event handler. The disadvantage to event-driven programming is that it does not scale to multicore.
Suppose you have 120 PB file system which consists of 20,000 600GB hard drives. We don't want to connect them all to the same bus, since the bus will get saturated. Instead, we put a few drives on a computer, call it a node, and attach it to a network containing many other similar nodes. How can we further improve performance?
Striping is a process where a large file gets striped into smaller pieces. These pieces can be read into RAM in parallel, so that there's no bottleneck.
A directory node keeps track of where all the files are. The issue with this is that the directory node becomes a bottleneck since all requests have to go through this node
If there is a directory with a dozen files, think of it as a linear array with a dozen entries, each with a file name. This works well for small directories but is terrible for big ones. For bigger ones we use something like a B+ tree (an n-ary tree that can have many children per node).
Distributed locking works like a blocking mutex, but it lives on the whole system. The system consists of many nodes and many connections between those nodes. Many clients can talk to the file system and do reads and writes to the closest nodes. However, problems can occur if part of the network gets cut off from the rest of the network.
There are two kinds of storage devices, hard disks and flash drives.
These are cheaper per byte by far but they have rotational latency. Say we have a 7200 RPM (120 Hz) drive. This means the worst case rotational latency is 8.3 ms (average case is 4.16 ms). There is also seek latency, which occurs when for example the read head is at the edge of the disk but we need to access something in the center of the disk.
| Seagate Barracuda 2TB Spec | Notes |
|---|---|
| 5400 RPM | |
| 5.5 ms average latency | This is very slow since we need to execute billions of instructions. |
| 300 Mb/s external transfer rate | |
| 95 Mb/s sustained data rate | Sustained data rate is much smaller because data is only going under the read head at 95 Mb/s. The disk controller has a cache and the cache talks to the bus, which can read 300 Mb/s but the disk drive itself only talks to the cache at roughly 95 Mb/s. |
| 32 MiD cache | |
| 512 bytes/sector | |
| 50,000 contacts starts/stops | This number tells you how many times you can park the read head when drive powers off before it will wear out. |
| 10^-14 non-recoverable read error rate | If you do a lot if I/O you can expect that for every 10 TB of data, there will be a bit error that the disk controller will not deal with. |
| 0.32% AFR (annualized fail rate) | There needs to be a strategy in place in case of failure. |
| 6.8 W avg operating power | |
| 5.5 W avg idle power | |
| 2 A startup current (12 Vpeak) | |
| 70G operating shock | |
| 300G nonoperating shock | |
| 2.6 bels acoustic noise |
Random access is much faster. However, flash wears out. If you keep writing to flash, eventually it will die. ¯\_(ツ)_/¯
To increase longevity, there is a technique called wear leveling. A flash controller sits on the bus to prevent reading and writing to the same location on the drive too many times and cause the disk to fail (there are hot spots such as logs that are used more often than others). The controller will instead move things around so the wear is more even.
| Corsair Force GT 60 GB Spec |
|---|
| 300 Mb/s transfer rate |
| 280 Mb/s read |
| 270 Mb/s write |
| 1000G operation |
| 2.0 W max power |
| 0.5 idle power |
| MTBF (mean time between failure) 1,000,000 hours |
At any point in time, your OS will have a set of requests for each disk or each flash drive. Each request will say, something like "I'm a read" or "I'm a write". This is the to-do list.
Say we have 1000 requests waiting. What do we do first? We could do priority, but app writers don't like that. Let's look at the simplest scheduling algorithm from before: First come first served (FCFS).
We'll finish this discussion during the next class