CS 111 Lecture 02/11/15
Akila Welihinda, Saad Syed, and Kenta Onimura
Synchronization Continued
Problem:
We want fast locks. xchgl is effective but slow.
Solution:
Haswell processors and successors have something called Hardware Lock Elision.
This has special instructions called xacquire and xrelease, which are faster than lock
because xacquire and xrelease don't tell other processors to stay off the locked section.
Instead, each processor does it's computations and stores it in it's cache. It then only
updates memory if no other process has acquired the lock. Otherwise, it acts as if the lock failed,
and all the other computation it performed is thrown away. This removes the bottleneck of telling each
process to stay off the locked region.
Example Code:
Lock: movl $1, %eax
Try:
xacquire lock xchgl %eax, mutex
cmp $0, %eax
jne try
ret
Unlock:
xrelease movl $0, mutex
The last bit of the mutex is 1 if the mutex is locked. With this new method the code in the critical section will always execute, but if xrelease fails (when the lock is locked),
the instruction pointer will jump back to the xacquire command and set a failed return value. This is much faster and improves performance.
Deadlocks
Deadlock occurs on much more complicated code.
Deadlock is usually not an issue for simple code like below:
deposit ($3, acct29);
withdraw($4, acct29);
However the following code can deadlock:
transfer(3, acct19, acct27); //executed by thread 1
transfer(34, acct27, acct19); //executed by thread 2
Consider the following implementation of transfer:
bool transfer(int num, Account f, Account t){
lock(f);
//decrement from f's balance
lock(t);
//increment t's balance
unlock(f);
unlock(t);
}
The above code can defintely deadlock! What happens if thread 1 locks account 19, and thread 2 locks account 27 right after that?
Facts about Deadlock:
- Deadlocks are usually a global non-obvious problem.
- Deadlock itself is a race condition. This is ironic because locks
are added to prevent race conditions.
4 Requirements of Deadlock
- Mutual Exclusion: If there is no mutual exclusion, then any process/thread can access memory without waiting for another to finish.
- Circular Wait: Whenever there is a circular waiting cycle. e.g.
| Process A |
Process B |
| lock(Y) | lock(X) |
| lock(X) | lock(Y) |
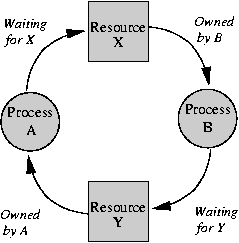
Process A won't complete until it gets lock X, but Process B doesn't give up lock X until it gets lock Y. This is also an example of problem number 4.
- No Preemption of Locks: If there is preemption, locks can be forcibly taken and a process that could otherwise wait infinitely (such as in the example above), would be forced to give up its lock and allow for another process to operate.
- Processes Hold and Wait: When processes hold one lock and request another. Deadlock can never occur if this condition is not satisfied. Refer to the above example for an example of this.
If any of the above 4 criteria is not met, then deadlock cannot occur.
Solving Deadlock
- Detect Deadlocks Dynamically:
Description: In order to detect deadlocks you need to keep a track of resources with a graph. This way, before assigning or waiting for a lock, the program can check if such an operation would cause circular wait. This can be done by performing a breadth first search or a depth first search on the graph modeling the resource/lock allocation and checking if any cycles would form due to the current request. If the current request has potential to cause a deadlock, it is rejected.
ex: lock(): can fail with a errno == EDEADLOCK.
Problems: This approach requires that existing applications be modified to deal with error messages indicating that a deadlock has been avoided. This makes it unfeasible to implement on large existing systems.
- Redesign so that Deadlocks can't occur:
Description: Write programs that implement some sort of lock ordering algorithm. In this system we only acquire locks in order (order can be determined by, say, memory addresses of the locks). If we acquire all the locks we want succesfully, we are good to go. Otherwise, if any lock was unavailable, we release all of our locks and start acquiring again from the start.
Example of Algorithm:
- if writing a primitive like transfer, where two locks are required:
- assume locks are ordered:
- typedef int lock_t; lock_t a, b; // Merely ask whether &a < &b, use address of locks
- acquire locks in order
- IF all successful, we are done and have all locks
- ELSE if we come across an unavailable lock, we release all locks and start acquiring from the start
Problems: Though this approach avoids the overhead of checking a graph for deadlock issues, it relies on programs being well behaved. That means that all applications must honor the lock ordering, else there could be unexpected deadlocks. This makes it hard on developers when they recieve deadlocks when they think that deadlocks can not occur or when they do not know about the specifics of the lock ordering system.
Priority Inversion
Priority inversion occurs when high priority process is completed after a process of lower priority (hence the inversion of priority) or when a high priority process is blocked from running due to a lower priority proces. It results from the subtle relationship between scheduling and locking. e.g. Mars Pathfinder 1997 was victim of prioirty inversion. Below shows an example
of thread execution which leads to priority inversion.
| Low Priority Thread |
Medium Priority Thread |
High Priority Thread |
| runnable |
waiting |
waiting |
| lock(m) |
waiting |
waiting |
| context switch to high priority |
waiting |
runnable |
| runnable |
runnable |
lock(m) |
| runnable |
Runs till completion |
waiting |
When the high priority thread attempts to call lock(m), this will block until the low priority thread releases the lock. Since the low priority thread has a low priority, this will take a long time.
Now that the high priority thread is blocked, the medium priority thread will be executed until completion. This causes an unexpected turn of events: the medium priority thread effectively gets
a higher priority than the high priority thread.
Solution
- Lock preemption: Force processes to give up locks.
Problem: If context switch occurs during critical section, memory corruption can occur. The analogy Professor Eggert mentioned was building a toothpick tower. The work is very delicate and does not handle interruption well.
- Borrow another thread's priority when owning a lock. This would mean that T_low gains T_high's priority temporarily because T_high is waiting on it to give up a lock. This lasts while T_low is executing its critical section so that it can quickly complete its task and give up its locked resources.
Livelock
Livelock is a state where threads/processes are running (they aren't in a waiting state) but due to some problem there is no actual work getting done. The following example illustrates livelock:
e.g. Receive livelock.
Consider a buffer that takes requests at 100 GB/s from a stream but can only process requests at 10 GB/s. In this sytem there are 2 major operations:
- Computation
- Handle interrupts: queueing incoming requests to buffer
Problem:
It would be natural to assign operation 2, handling interrupts, a higher priority. If not, then a lot of data would be permanently lost from the stream if it is not saved as it comes in. However, if the buffer continually recieves packets then no computation would ever get done since the requests come in at a faster rate than the program can process the data. Performance will suffer since the CPU can keep on inserting into buffer and nothing is serviced.
The graph below illustrates the performance.
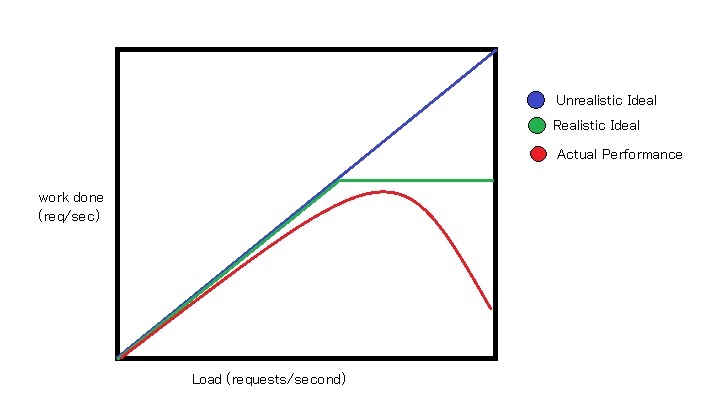
Solution:
When buffer is full, mask interrupts, and once buffer has space, reallow interrupts. Even if we continually handle interrupts, we would be losing data since the buffer has a finite size. Therefore, even though data will be lost during computation, it is not a worse situation from the previous implementation in regards to losing information.
Event Driven Programming
Reorganize OS to avoid locks?
Locking code is, in general, a bug magnet. Is there a way to avoid race conditions but forgoe locks altogether? A possible solution is implemented in many embedded systems today - event driven programming.
What is Event Driven Programming?
In event driven programming there is only one main thread and no locks at all. Instead, computation is organized into a series of events handled by event handlers, as opposed to computation handled by synchronized threads. Programs themselves are then conecptually just a set of event handlers. The system maintains a priority queue of incoming events and runtime simply consists of popping off the first element of the queue, handling it, and repeating. They key idea behind event handlers is that they NEVER wait. When an event handler runs it does not yield and runs quickly to completion. This naturally creates critical sections. Synchronization is not an issue since event handlers run uninterrupted and in sequence.
Advantages
As mentioned before, each event is naturally a critical section. No need to worry about synchronization since fundamentally event handlers run uninterrupted.
Disadvantages
Event driven programming does not work well on multi-core systems because event driven programming only makes use of one core. Since a huge majority of systems these days are multi-core, this is a problem. It may be unnatural to break down certain computations into various events with seperate handlers. This is mainly why event driven programming is generally only found on low level, smaller scale embedded systems.
File Systems Performance
Professor Eggert once had to help design a file system which ran GPFS and had 120PB of data; 200,000 hard drives(each 600GB, 15 kRPM).
Why only 600GB per hard-drive? Smaller hard drives allow more read/write operations to be done in parallel, thus improving performance. However one must also keep in mind that the price per byte goes up as the storage size goes down.
Tips for Designing Large File Systems
- don't hook up all hard drives and CPU to the same bus. There will be way too much traffic on this bus! An example of this bad implementation is shown below.
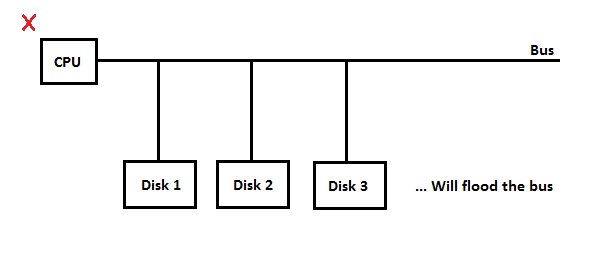
- Instead, create a node with a few controllers and few hard drives. The entire file system will consist of a network of nodes
Ideas for Implementation
- Striping
Description:
We want to be able to perform read/write operations on large files in parallel. This is not much of an issue with small files but there would be a huge overhead to read/write to large files. Striping essentially means breaking up a file and scattering it accross various disks. This avoids the bottleneck of one massive read/write operation and instead utilizes the numerous hard drives on the system to achieve a computational speedup. This naturally requires a directory node to keep track of all the files and where all of their pieces are stored.
Problems:
The directory node itself becomes a bottleneck since every operation must first go to it to figure out where it needs to access memory.
- Distributed Metadata
Description:
In order to avoid the bottleneck of a single directory node, we can scatter metadata (data about data) all over the system. In particular, this means that information about what is on the disk (where information is stored, who is the owner, what is the timestamp, etc) is dispersed throughout the system so that opertions do not have only a single source of reference.
Problems:
All of the dispersed data must be consistent. This means that when a change occurs somewhere in the system it must be logged everywhere else where that data is referenced.
- Efficient Directory Indexing
Description:
We want to avoid ineffcient storage methods. Take, for example, a system where directories store files in a linear array. The sorting computation required for a simple ls command would be too much for directories with, say, a million files. Instead we should use efficient data structures such as trees to represent directories. What is generally used is B+ trees. B+ trees are special data structures which take advantage of the way hard drives store their data. This allows them to be very fast when operating on huge amounts of data.
- Distributed Locks for Distributed Nodes/CPUs
Description:
Since our file system is composed of several nodes with several hard disks, we can't rely on locks existing only in a particular segment of memory. The locks, or blocking mutexes, must exist across multiple CPUs and disks.
Problems:
Synchronization of these distributed locks can get tricky.
- Parition Awareness
Description:
If the file syste becomes segmented, we don't want to lose the ability to perform operations in all parts of the system. With partition awareness the convention is that the largest partition, computed by number of connections or nodes, stays alive and retains the abiliy to do reads and writes. The other partitions are frozen and do not operate until the system is restored.
Problems:
Segments need to remain consistent. If a file is updated in a live partition, then the frozen partition must become aware of this after the file system is restored again.
I/O performance: Flash vs HDD's
There are two main ways in which memory is permanently stored: Hard Disks (HDD's) and Flash.
Hard Disk - Cheaper per bytes, but has higher rotational latency and higher seek time.
Flash storage - Higher price per bytes, but has higher throughput and lower seek time.
Rotational latency - is delay to rotate the read/write head over the designated sector.
Seek time - is the time for read head reposition itself to reach appropriate disk location
We will now compare a Seagate HDD with a Corsair SSD.
| Feature |
Seagate Barracuda (HDD) |
Corsair Force GT (Flash) |
| Capacity |
2 TB |
60 GB |
| Cache |
32 Mib |
--- |
| Bytes/sector |
512 |
--- |
| Contact (start/stops) limit |
50,000 |
--- |
| Non-recover Read Error Rate |
10^-14 |
--- |
| Annual Failure Rate |
0.32% |
--- |
| Average Operating Power |
6.8 Watts |
2.0 Watts |
| Operating Shock |
70 |
1000 |
The HDD also has a 300 Mb/s external transfer rate (rate of transfer to the CPU).
However, it has a 95 Mb/s sustained data rate (rate of transfer from disk to disk controller).
The sustained data rate is the more important statistic because it is the bottleneck.
The SSD also has a 300 Mb/s transfer rate limit. It also has a read limit of 280 Mb/s and a write limit of 270 Mb/s.
Downside of Flash:
- Flash wears out much quicker than its slower counterparts.
- After a certain number of flash accesses, that memory block dies out
- Hotspots are locations that are read/written to more often than others.
- Hotspots can cause certain blocks to wear out faster, and thus become a critical point for the entire drive if it fails.
Solution: Wear Leveling
Wear-Leveling algorithms exist to prolong the life of a flash drive. Wear-leveling works by moving blocks of memory around to even out flash wearing. Details are given below:
- move around hotspots so that all blocks tend to wear out around the same time
- software needs to map and keep track of physical blocks vs logical blocks
- wear leveling is in general very difficult to implement (just think about the storage of the mapping coordinates, it would become a hotspot itself)
Flash drives has bad reputation for reliability, since wear leveling is a difficult/unreliable algorithm and implemented poorly in cheap SSD.
Scheduling Revisited
At any point in time, you can have a bunch of read/write requests for one disk. Assume that the time taken to begin servicing a new request is proportional to its distance from the current read head position. How do we decide which requests to serve first?
We could use the First-Come-First-Serve algorithm, but our throughput can be improved upon if we try to schedule read/write requests that occur nearby each other in succession. This will reduce the seek time and rotational latency.