Disk Scheduling and File System Design Notes Notes by Cheng Cheng
Table of Contents- Disk Scheduling Algorithms
- First Come First Serve
- Shortest Seek Time First
- Elevator Algorithm
- Anticipatory Scheduling
- Multiprogramming
- File System Design
- Eggert's 1974 Research Project (RT Filesystem)
- FAT
- Unix
- Berkeley FFS
Disk Scheduling Algorithms
First Come First Serve (FCFS)
First come first serve serves requests in the order they come in.First come first serve will have an average wait time based on random reads, gives an average wait time of 1/3 N.
Explanation: Pretend we have the following disk with sectors 0 to N. +-----------------------------------------+ | | | | | | | | | | | | | | | | | | | | | | +-----------------------------------------+ 0 N If requests are evenly and randomly distributed then the following integral will define the average wait time with N = 1. Therefore average wait time for any N is 1/3 N.
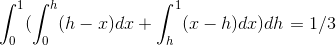
Shortest Seek Time First (SSTF)
Shortest Seek Time First picks the nearest request to the head.Assuming we have read requests {20, 97, 512, 109321} and the head is @ 96, SSTF will pick 97.
SSTF VS FCFS: SSTF has more throughput, but FCFS is more fair.
SSTF niceness = seek time. FCFS niceness = arrival time
A hybrid algorithm can be defined where niceness = seek time + arrival time
Elevator Algorithm
The Elevator algorithm is a hybrid algorithm that attemps to be fair and have good throughput.The head is like an elevator, the requests people and the sectors floors. The head moves up and down from end to end. This guarantees no starvation yet also appears to be fair. However it has a problem of being unfair, requests in the middle are serviced more often than ones on the end. To fix this, the elevator is made to move in only one direction, and when it reaches the end moves all the way back to the beginning. This is slower, but more fair.
Head's Path: Suppose the disk was size N +-----------------------------------------+ 0 N Then the head would travel like so if unfair: -->-->-->-->-->-->-->-->-->-->-->-->-->-->+ +<--<--<--<--<--<--<--<--<--<--<--<--<--<-- -->-->-->-->-->-->-->-->-->-->-->-->-->-->+ +<--<--<--<--<--<--<--<--<--<--<--<--<--<-- and like this if fair: -->-->-->-->-->-->-->-->-->-->-->-->-->-->+ -->-->-->-->-->-->-->-->-->-->-->-->-->-->+ -->-->-->-->-->-->-->-->-->-->-->-->-->-->+ -->-->-->-->-->-->-->-->-->-->-->-->-->-->+
Anticipatory Scheduling
Anticipatory scheduling is optimization of scheduling based on what the OS believes programs will do.Suppose we had two programs A and B with the following requests:
A: {1,2,3,4,5}
B: {1001,1002,1003,1004,1005}
In an imaginary scenario the following will happen with a SSTF or elevator algorithm.
1. A runs first, gets request #1 fulfilled then goes and does some work.
2. B runs, and the disk will grant the request since there's nothing else head moves to 1001.
3. A then runs and head has to move all the way back to 2.
4. So on and so forth oscillating ~1000 vectors.
This is extremely inefficient, to fix this you can use anticipatory scheduling. In essence, it is the batching of requests from a given program and delaying the requests from other programs in the hope that this will lead to more efficient performance overall. For example in the above case, after the request for 1 is fulfilled, the algorithm will delay a certain amount waiting for A to give another request in the hope that it's closer than B's request. The details of this algorithm are a "dark art", it's hard to decide what is actually optimal. To help with the decision making, applications can use specialized syscalls whose purpose is only to help this scheduler decide on whether or not to delay other applications.
Multiprogramming
Multiprogramming is another way to improve I/O performance.Multiple programs each with I/O needs can be batched / satsified in parallel. In general running I/O in parallel is better than
sequential for this reason.
File System Design
A filesystem is a hybrid data structure that lives on RAM and disk. It wants the capacity and permeance of secondary storage, but also the speed of RAM.Eggert's 1974 Research Project
Eggert had a professor who told him to write a OS which had a text editor and a compiler. This was essentially unix. This meant that he needed to write a file system.Fun fact: he had to write it in assembly and the computer he ran it on couldn't subtract numbers with large differences properly.
Modeled file system as a large array.
Some restrictions:
-File contents must be continguous
-Files must start at the beginning of a sector
-Each sector was 512 Bytes
In the beginning of this large array were 512 Bytes reserved for 16 byte file descriptors.
Arragned with 16 bits for the size of the file, 16 bits start sector, 12 bytes for the name
This approach is similar to the RT II filesystem.
Pros:
+simple
+Good and predictable for I/O since files are contiguous
Cons:
-Wasted space (a one byte file takes up a whole sector!)
-External fragmentation. If your files are sparsely distributed, your max file size is limited since files must be contiguous.
-Directory imposes limit on the # of files.
-Hard to grow files
-Apps must tell OS how much their output will be
-File names are short
-No user directories
FAT - file allocation table
FAT tries to fixe some of the cons above.FAT supports directories, easy file growth, and has no external fragmentation.
FAT has 4KiB blocks (8 sectors) instead of sectors
Data not contiguous. Linked list of blocks where a blocks next section is indicated in the FAT. (An array where arr[i] = next block for block i or 0 if there is none)
Directory Implementation
Directories are represented simply as a file with directory entries.
The first block holds the root directory. (superblock)
A directory entry contains several pieces of metadata:
8 bytes - filename
3 bytes - file extension
2 bytes - block # of first block
1 bytes - type of file (0 for regular, 1 directory)
2 bytes - file size
Disk layout +-----------------------------------------+ | superblock | FAT | BLOCKS | +-----------------------------------------+Finding free space
Eggert: You have to look at the data
FAT: free space is marked as -1 for free blocks
Problems with FAT
-Sequential I/O can be very seeky since a file is in a lot of different places. To improve performance, a file's pieces can be collated together to be more contiguous, this is called defragmentation. This is however expensive and risky due to corruption during power outage.-Renaming a file in the same directory is cheap, but moving it between directories is forbidden due to technical issues. Consider the case where during a move you copy over a file and then power is cut. If you then remove one file, the other file won't think it's been removed and you will be reading "freed" space.
UNIX Filesystem
The big idea is to use inodes, which are pieces of fixed size metadata associated with every file.Inodes are put into RAM when a file is in use, otherwise they are moved to disk.
Inodes are held in a table taking up some blocks.
Directory entries are essentially pointers to these inodes, which in turn actually point to the file.
Inode Structure
Inodes contain the following pieces of data:
-size in bytes
-type
-date
-permissions
-# of links (Number of entries pointing to this inode / file)
Since inodes hold metadata, this simplifies directory entries so they can just be 14 bytes for the name and 2 bytes for the inode #.
Moving file between Directories
How moving a file between directories works with inodes:
1. add entry to the new directory
2. add link to inode
3. remove entry from the old directory
4. remove link to inode
This method is resistant to power loss because of the links!
Git Clone
Inodes is why git clone is so fast, because you just need to hookup the inode #'s toentries and increment the link counts.
PROBLEMS
Possibility of link overflow, since link count is 1 byte quantity.You cannot hard link except to files, otherwise you may get circular links.
Handling removal
You would expect to get a file to get removed when an inode's link count == 0, but this is not 100% true.Example:
foo's link count is 1
(rm foo; cat) < foo
This shouldn't work because cat will have nothing to read from due to the rm. Therefore the OS mandates that a file's storage is reclaimed if the link count is 0 and nobody has it open currently.
Large Inodes
inodes contain an indirect block. This is similar to a FAT table, showing you where the pieces of the file are.10th entry holds one indirect block, up to 16MB file
11th entry in inode holds doubly indirect block. 2^35 bytes