
Recall a simple performance model for disk I/O:
|i –j | = cost to read (move disk head)
Assuming random read access to disk and the disk is one unit big:
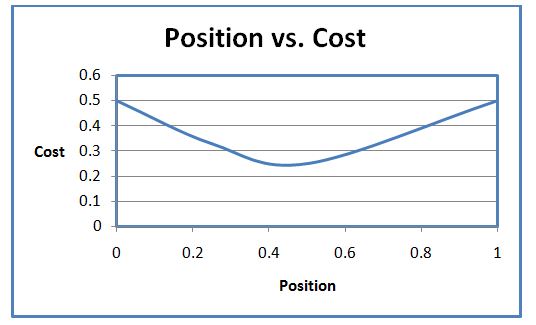
Points along the line represent the average seek time depending on position with the area representing the total average seek time from disk head position 0 to 1.
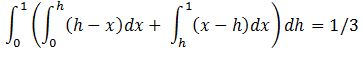
For example, we have a set of read requests {20, 97, 512, 109321} where the head starts at position 96. One approach is to read 97 (option with the shortest seek time) first, which would be Shortest Seek Time First (SSTF). Compared to First Come First Serve (FCFS), SSTF has the best throughput. However, it is not fair and can lead to starvation. If requests to read keep coming in that are closer to the read head, then farther requests, such as 109321, will never get processed. Because we are dealing with scheduling, we can borrow some ideas and concepts from CPU scheduling (SSTF - best throughput vs. FCFS - fair, no starvation).
Both algorithms are priority scheduling.
SSTF niceness = seek time
FCFS niceness = arrival time
Hybrid approach – niceness = seek time + arrival time
Another way to approach this without using arrival time while still having fairness is to use an elevator algorithm, where you start from the start and read to the end, then reverse direction and go to the end.
The problem with this approach is that it is not completely fair. Requests in the middle don’t have to wait as long to access the elevator than requests at the end, which can access the elevator when it is going only up or only down. To make it more fair, we can make the elevator only go in one direction. When it reaches the end, we can make the elevator go back to the beginning (like a circular elevator or array, always go “up”). It takes some time for the head to go back to the beginning, but since it is not processing read, it can quickly accelerate to get there, not wasting much time.

But what do we do in the following situation? We we have two programs:
A read requests: 1, 2, 3, 4, 5 B read requests: 1001, 1002, 1003, 1004, 1005
Delays will be very large due to multiple waits and reading across larger ranges. We can be processing read request 1, then get read request 1001, but we receive read request 2 as we are trying to move the head for the read request at position 1001. The head would be moving 1000 units as it juggles the requests of A and B when it should have just done the requests for A first.
Solution 1, Anticipatory Scheduling. Even though the head is at position 1 and a request is received to go to position 1001, delay instead of executing (this allows request 2 to come in and get executed). Performance is great, but we need to predict what the system will do. This is done through patterns and hints. There are advisory system calls that tell the system that it will need to head for more than one request.
Solution 2, Multi-programming. Multiple programs each with their own I/O needs that could be batched or satisifiable in parallel for better throughput.
File System – data structure living on both secondary storage and RAM. The File System should take the advantage of the capacity and permanence of the secondary storage as well as the performance and speed of RAM.
His task was to duplicate Unix on the Lockhead SO and write a file system (to write text editor). He modeled the disk on a contiguous array of sectors, with each sector 512 bytes. Files are given sectors in memory. The last sector belongs to the file, even if not all of it is used - this claimed but unused memory is indicated by the gray boxes in the diagram below. Files are filled in consecutive order. (file2 is right after file1 in memory and all of file1’s sectors are right next to each other).

The first four boxes indicate one file’s blocks of data, while the fifth block is another file. Notice the gray boxes, which indicate memory claimed by the files that are not actually utilized.
But there's a problem with this design: we need to keep track of where files are. The solution? Take the first two sectors to put a table that detail where files are.
Eggert’s design is similar to the RT-11 file system (REALTIME-11, 1973).
Pros:
Cons:
FAT (File Allocation Table) File System
First approach: Put next fields at the end of file - each block act as a linked list, pointing to the next block of the file, but it is bad if the read and write are in powers of 2 and it is strenuous to always check the end of each file to see where the next part of it possibly lies. A solution to this problem would be to put linked list info in a table located near the beginning of the array (FAT). It is an array of 16-bit numbers where each number points to the next block in a file and a 0 indicating that is the last block of a file. Because of this, there are no longer external fragmentation problems.
A directory (file with contents) follows the following diagram:

One of the first few blocks is a “superblock.” The superblock contains the file system version, file system size, and the block number of the root directory.

How do we keep track of all the free space without taking up more memory in RAM and with less scanning? One approach is, in the FAT (Free Allocation Table), let us denote free blocks by -1, 0 for the last field of a file, and any positive number to represent the next fields of each file.
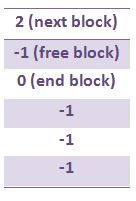
Problems with FAT: Sequential I/O can be seeky, i.e. the head can move a lot. Defragmentation (file repair procedure) in which one tries to rewrite and rearrange the file system to make it contiguous is rather expensive. One would need to watch out for corruption of sector arrangements if one’s system loses power during the defragmentation process.
Other issues arise with renaming files. Let’s examine the following examples:
renaming a file foo.c to bar.c is easy and fast renaming a file A/foo.c to B/foo.c is tricky and forbidden because one can lose the file in A before the file in B is even created or have two files (one in each directory) upon a power outage (deleting one would cause the other to point at a file that is no longer there); as a result, the solution is to simply prohibit renaming when involving directory names
UNIX File System (~1977)
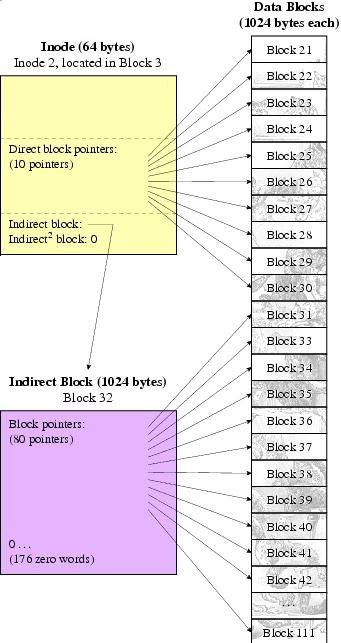
This file system attempts to avoid fragmentation and the renaming issues mentioned previously. Solution: The inode is the big idea that involves a small fixed size amount of memory devoted to metadata for a file. There is one inode per file. It is cached in RAM when the file is in use and stored in the disk otherwise. Inodes hold information such as the size of the file, type, date, permissions, number of links, and block numbers (indirect blocks and doubly linked blocks) that marks the positions of parts of the file in memory.


In an inode, part of the data is used to point to blocks that is used for the file. The first ten entries are pointers that directly point to the block that is part of the file. When a file cannot be represented with only 10 blocks worth of data, the next entry in an inode points to an indirect instead of a direct block. This indirect block's purpose is to hold pointers to other blocks of data - it is essentially a normal block that contains pointers to other blocks. If that is not enough, the twelfth entry in the indode is a doubly linked or doubly indirect block, which is a block of data containing pointers to indirect blocks (which contain direct pointers to blocks). This expands considerably how big a file can be.
How about moving files from one directory to another? One can successfully move the file from the A directory to B directory by changing links. This solves the problem of moving a file into a different directory as a link is created before the original file is removed; either the file stays in the original directory (operation never occurred from user’s perspective) or the file receives another link that lives in directory B. Git clone does a similar process and adds links to the original file being cloned. For example, the schematic would look like this: link(“A”, “B”); unlink (“A”); If one removes a file, one must decrement the link count and zero out the file. Adding an additional link to a file would increment the link count while adding an entry to a directory that would have the same inode entry as a different directory entry (that can be living in the same or different directory).
Problems with linking: Circular links don’t allow hard links to directories, but only to files because it will lead to a never ending cycle of following links to itself. Say a file named foo has a link count of 1.
Then we do the following call:
(rm foo; cat) < foo
foo’s link count becomes 0 upon executing the rm command, and upon executing the cat command in sequence, it errors/breaks. One must then be able to reclaim a file’s storage when the link count is 0 and no other process has it open (the OS knows this, not in the file system).
Side note comparisons between FAT and UNIX file systems:
FAT files can be random and sequential access is slow.
UNIX allows for better random access to files, though fragmentation is still an issue.