
Kevin Zhu, Justin Teo, Vir Thakor, Kalin Khemka
Date: 02/18/2015
Where there are N blocks, i is the current read position, and j is the position we want to read from next.
Between positions i and j, the average time is |i - j| / 2 to move the read head, assuming we’re measuring latency as a function of distance the read head needs the move. To find the total average between any two positions i and j (assuming random reads), we simply need to repeat this process for each possible combination of positions for i and j.
This yields the following graph:
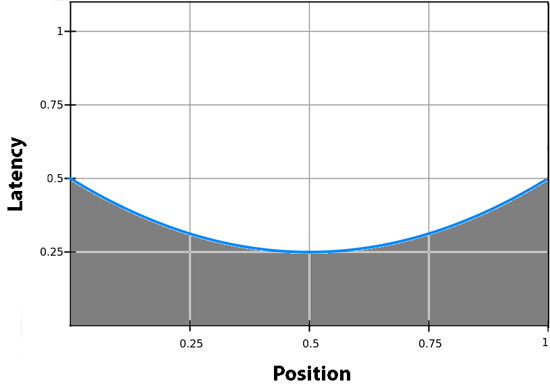
Integrating the area under this curve with respect to the read head position yields the result:
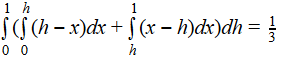
With these latency costs in mind, can we think of an efficient disk scheduling algorithm?
Imagine set of read requests {20, 97, 512, 109321}, where the head is at position 96.
Two basic algorithms come to mind:
| Shortest Seek Time First (SSTF) | First Come First Serve (FCFS) | |
|---|---|---|
| Pros | Best throughput | Fair and no starvation |
| Cons | Starvation possible | Slower |
| Priority | Seek time | Arrival time |
We've seen this similar problem in scheduling for the CPU, so how do we apply our solutions from CPU scheduling to disk scheduling?
Since both algorithms are priority scheduling, we can compromise with a hybrid approach, given by:
niceness = seek time + arrival time
Suppose that we do not know the arrival times and we only know the seek time and location on the disk. Essentially, we want to achieve fairness while paying no attention to the arrival time of requests.
This algorithm uses SSTF, but only operates in one direction such that it services the next read request that is in the direction that the head is moving. This approach is fair such that starvation is impossible, but it is still not completely fair. For example, requests at far ends, or synonymously people waiting on the first and last floor wait the longest. Resultantly, requests near the middle are serviced more often than others.

Solution: We can apply a circular elevator approach, where the elevator only travels upwards, and once it hits the very top, will restart at the very bottom immediately and continue traveling upwards. This is the approach applied most often in real-life situations.

Imagine another scenario where two programs A and B are both doing read requests:
A reading 1, 2, 3, 4, 5, …
B reading 1001, 1002, 1003, 1004, 1005, …
In the normal approach, the requests are serviced alternatively as they come in: 1,1001,2,1002,3,1003,…
Evidently, this is extremely ineffective since the read head has to jump forward and back about 1000 blocks between each service. What we ideally want to happen is to service A first for a while, then switch to B after a period of time has passed. This is known as anticipatory scheduling.
Instead of executing immediately, we purposefully delay in hope that process A is likely to issue a request to read a nearby block. This is regarded as a "dark art" as it requires guessing on what programs will do. To help aid the OS, we implement advisory system calls that a program can use to tell the OS that it will be accessing contiguous or nearby blocks.
There is one other way that we can improve I/O performance by multiprogramming multiple programs that each have their own respective I/O needs. Resultantly, each program can execute reads in parallel if they're accessing data on different disks, or maybe the data that multiple programs want to access can be batched together to minimize overhead. With these principles in mind, we can finally approach the problem of designing an efficient file system.
A file system is simply a data structure living on both secondary storage and RAM. Secondary storage allows for both capacity and permanence of data, whereas RAM is much faster. We want to design a file system that utilizes the best features of both.
In 1974, Professor Eggert was assigned a project to write a text editor and essentially duplicate UNIX on a Lockheed OS. To do this, he needed to write a quick and efficient file system to save files for the text editor.

With this layout, each file is stored contiguously into memory, where each sector is 512 bytes long. Additionally, a table of where the files are in memory, or a directory, is held at the beginning so that we can find files that need to be accessed. This table took up the first two sectors and provided important information for each file, such as the size of the file, the start sector, and the name of the file. In fact, this is the design of the RT-11 (Real-Time) file system (1972). However, this file system possesses many drawbacks.
| Advantages | Disadvantages |
|---|---|
|
|
To address many of these limitations, we need to completely redesign this file system.
In the late 1970s, a new file system was designed that would address many of the major problems of the RT-11 File Systems: the File Allocation Table file system. The representation in memory is shown below.

The goal of this system was to organize data as a linked list of blocks, so that file no longer need to be contiguous in memory. Instead of having the pointers to the next block in the blocks themselves since this would potentially create boundary problems on the blocks, the FAT takes care of the links. This problem gets rid of the problem of external fragmentation. The first block is known as the superblock, which indicates the file system version, size, and location of the root directory. Also, the FAT is simply an array of 16 bit numbers that indicates where the next block of a file is, given that the starting block was already provided.
![]()
For example, if a file is located 29, the FAT would indicate that the next block is located at locations 36 then 12, where 0 represents the end of the file and that there are no more blocks for the file.
Furthermore, this representation allows us to create subdirectories, since directories are just files with additional content.
| File Name | Extension | First Block | File Type | File Size | ... |
|---|---|---|---|---|---|
| foo_____ | .c_____ | 5 | 0 | 3 | ... |
| 0 | 0 | 0 | 0 | 0 | 0 |
For the file type, 0 represents a regular file, and 1 represents a directory. A row with all 0s represents an unused column.
However, the FAT system introduces a host of problems. Firstly, this system does not fix internal fragmentation, and can waste up to 4095 bytes for file. Also, since blocks are now spread throughout memory, there will be additional latency for the read head to move. This can be remedied by using a process known as defragmentation, where files are moved into orderly contiguous blocks for quicker access. However, this process is very expensive, and also would also result in massive corruption if the computer were to turn off during the procedure.
There is another problem with this approach when renaming a file into a different directory. Imagine if we wanted to perform this operation:
a/foo.c -> b/foo.c
During this process, the file is being modified in the table and is copied into the new directory. However, if we lose power during this process, then there are two scenarios. If the power is lost right when the file is removed, the file contents will be completely lost. If power is lost right after the contents are transferred, then the foo.c in directory a will point to empty space. Renaming a file into a different directory will also be a problem, since altering one copy will delete all copies. In the FAT system, this is simply completely forbidden to prevent these problems. Evidently we still need a new file system that is robust in all these scenarios.
In 1977, the new Unix file system was introduced to remedy all the problems of its predecessors. The biggest new idea was the inode, one for each file. The system uses a fixed size of data that gives metadata for a file, while also caching files in use and storing other unused files on disk.
The design of the file system was relative similar to that of FAT, with blocks linked throughout memory. However, instead of using the FAT array, it used an inode table.
The inode table stored metadata for each file in storage. This included the size in bytes, type (directory or file), date, permissions, number of links, and the locations of all the blocks for the file. While the first few indexes are direct pointers to blocks, the last two are pointers to indirect blocks, where one is a pointer to an array of blocks and the other is a pointer to a 2D array of blocks. This allows for a total of about 2^35blocks allocated for a single file. The use of links is also a new concept in this file system. This way, we can simply relink files to inode entries without have to delete and move contents anymore. Also, multiple files can be related to the same inode so that a file can exist in multiple directories simultaneously.
Directories are also similarly supported with a slightly similar design:
| File Name | Inode # |
|---|---|
| ... | ... |
This way, directories are much more organized and easier to index, since it only stored a 14 bit name and 2 bit inode number. Notably, the name is not even regarded inside the inode table.
The reason git clone works so fast even on enormous directories is because git clone simply makes a new git subdirectory and points to those inodes, meaning it doesn't need to copy all the data bit by bit into the subdirectory.

Using inodes, however, does produce other problems. For example, to remove a file using inodes, the system would have to first zero out the directory block and then decrement the inode link count. What would happen if the system loses power in between this process? Then the process would fail. Another example is the problem of cycles. If one were to create a hard link to the directory above a file, then trying to access or remove the file would lead to an infinite cycle. Because of this, the Unix File System does not allow for the creation of hard links to directories.
Another example of a problem involves the following code:
$(rm foo; cat) < foo
With the rules we have understood so far, we can see that there is a problem with this statement. The remove will run fine on foo, causing the link count to go to 0. This will let the OS reclaim the storage space that foo was using. However, when the cat command runs, it will take in the standard input from foo which no longer exists, and that will cause a problem.
To fix this, there is another rule that the OS follows. It can only reclaim the file storage if and only if the following two conditions are satisfied:
Another issue with inodes is the fact that if a file becomes too large, the inode itself will have to become larger as well to hold the block numbers where the data of the file is stored. To avoid this problem, the OS uses a fixed inode size, but uses the last 2 inode entries, numbers 10 and 11, as indirect blocks, which then functions as pointers to another array of blocks. These indirect blocks contain 2^11 block numbers. If only entry 10 is used, then a file that is 16 MiB large, or 2^24 bytes large, can be represented. If using simply the tenth block is not enough however, then the eleventh block is used, allowing for files up to 32 GiB large to be represented. If even that is not enough, then the eleventh block can point to even more indirect blocks, creating doubly linked blocks, which can store files of even greater size.
Fragmentation is still an issue with the Unix file system because the storage of data can be semi-random, thus sequential access is slow. Even with the inode blocks, the file's data is still stored as a link list and one have to traverse the linked list to collect all the data. When running the command lseek however, the Unix file system is much faster than the FAT file system. When run in the FAT file system, lseek is O(N) because to get to say the 5 millionth block, you have to traverse the linked list to get there. In the Linux file system, to get to that same block, you either find it in the inode already, or you have to traverse maybe one or 2 blocks farther to find this location through the indirect blocks. Thus, lseek is O(1) in the Unix file system.
To deal with fragmentation in the Unix file system, there is a variant called the Berkeley Fast File System. At the start of this file system, there is an area which is a bitmap of free blocks. There is one bit for every data block on the file system. It will hold 1 if the block is free, and 0 if the block is in use. An advantage of having the bitmap is that because it is so small, as it only uses 1 bit for every 8 KiB, it can basically fit onto the RAM, thus allowing the OS to quickly find free blocks helping with contiguous allocation. Because you don't have to read in a 16 bit or 32 bit number to find these free blocks, the process is much less expensive, and increases the amount of contiguous allocation.