Recorded by Robert Fotino
Indirect blocks in an inode are used when the file size exceeds the amount of data that can be stored in the very limited direct blocks. The indirect block stores addresses to blocks where more data is stored. An indirect block can store addresses of BLOCK_SIZE / ADDRESS_SIZE blocks. When the first indirect block has been used up, the file system will allocate the doubly indirect block, which stores addresses to more indirect blocks that store addresses to data blocks. See the diagram below.
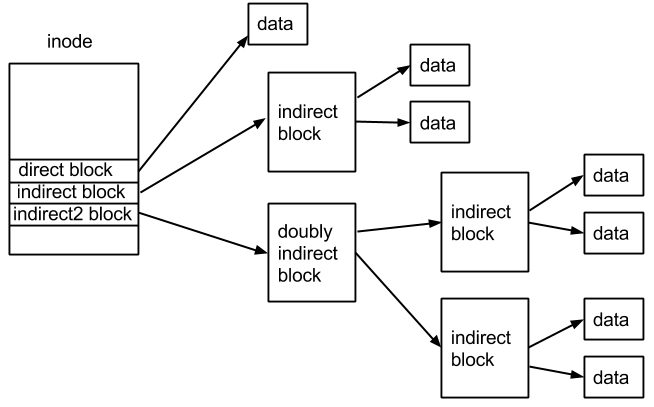
Suppose a file's size is 0. Then no blocks are allocated, and there is no fragmentation except for the wasted space in the inode for block addresses.
If the file size is 1 byte, then we waste BLOCK_SIZE - 1 bytes. For a 1 byte file with a block size of 8 KiB, we waste 8191 bytes in the data block + 44 bytes in the inode = 8235 bytes.
Another way to waste space is to create a holey file, also known as a sparse file, which is a large file that is mostly empty with some allocated data blocks throughout; for the parts of the file that are not allocated, reading will return zeros. Such a file can be created by seeking past the end of the file and writing, then seeking past the end and writing again, like so:
For the first billion bytes, reading from foo will return 0s. The file system will have to allocate a doubly indirect block, an indirect block, and a data block to store the 5 bytes for "hello". The total internal fragmentation for this file will be 44 bytes (inode) + 8188 bytes (doubly indirect) + 8188 bytes (indirect) + 8187 bytes (data block) = 24607 bytes. But it gets worse; we could seek elsewhere and store small amounts of data, allocating more indirect blocks and more data blocks with large amounts of unused space. Running $ ls -ls foo will report that not much space is used, even though the file is a billion bytes.
One of the applications of a sparse file is for relational databases. Since their data structures are stored on disk instead of just in RAM, if they have a hash table the hash function will cause data to be stored randomly throughout a large file, with large amounts of unused space in between.
One of the problems with sparse files is that since there are no blocks allocated for the holes in between, even though you can create an enormous file and read sequentially and get all zeros, you might not be able to write to the entire file because you could exhaust the blocks in the underlying file system.
Fairly small, typically 512 bytes.
Usually a multiple of the sectors size, for example an 8 KiB block = 16 * 512 byte sectors.
You might partition a disk so that you can allocate a certain amount of space for /, /boot, /usr, /home, and swap. Partitioning a disk into multiple file systems limits the damage that can be caused by a single file system running out of space, getting corrupted, etc. Note: swap is not a file system, it is used for dumping virtual memory.
Linux supports using multiple file systems, each of which can be mounted under a certain folder. For example, the root file system is mounted under /, and another file system can be mounted under /usr. This is different than exposing file systems to the user, i.e. C:\etc\passwd, D:\usr. Linux uses a uses a mount table to associate files to partitions that contain a file system. Each entry in the mount table would have a file under /dev that contains the file system, the path of the directory to mount to, and the type of file system so the operating system can use the right driver.
A potential issue with the mount table is that it could have loops, for example /foo could be mounted to /foo/bar. To fix this, there is a system call named mount(source, target); that fails if target is a descendant of source.
Linux supports multiple file systems by using object oriented programming. The file system is an object with certain member functions for standard operations like read, write, open, unlink, etc. This is accomplished via the VFS layer (virtual file system layer), which lets you "subclass" its provided structs, overwriting the function pointers for standard operations with your own. VFS was originally invented for NFS, or networked file systems. Reads and writes would just do requests over the network instead of from disk, with the same interface for user code.
In order to resolve a file name, for example open("foo/bar", ...);, the OS will start at the working directory (for a relative path) or the root (for an absolute path). It will then loop over each file name component, separated by forward slashes, and look up the inode number in the directory entry where the file name component is found. From the inode, we can get the directory entries to look up the next file name component and continue down the tree. If the file name component is missing from the directory entry, we get an ENOENT error, for "no such file or directory". If the current user doesn't have search permissions (the x bit on directories), then we get an EPERM error.
The working directory is separate for each process. There is a chdir(); system call for changing the working directory. There is also a chroot(); system call for changing the root. If we do chroot, it makes some files invisible, because you can't go back up the tree. Calling chroot("/.."); is the same as calling chroot("/");, which is a no-op. Only the root user can do chroot, because otherwise you could create your own directory with a changed /etc/passwd file, for example, that had stored passwords of your choosing. Then you could log in as root and do whatever you wanted. This is sometimes useful for running untrusted programs, because you can make a "chrooted jail" from which to run the program, so that it can't have access to important system files. Only the chrooted jail can be damaged.
If there is a low-level error in name resolution, like a bad sector so you can't retrieve data, the system call will fail and set errno to EIO.
Symbolic links have several advantages over hard links. They can exist across file system boundaries, because they store a path that they link to as text rather than an inode number. You could also have conditional symbolic links, although these are not used in Linux. You can't hard link to a directory, but you can create a symlink that points to a directory. Symbolic links can even point at nonexistent files.
One problem with symbolic links is that they can loop, or even point to themselves. To fix this for name resolution, there is a maximum number of symlink expansions before the resolution fails with the error ELOOP.
This depends on the file system implementation. If yes, either the data blocks of the symlink's inode or the inode itself could store the symlink contents. This would allow you to have hard links to symlinks. But suppose we did the following:
Now c is a hard link to the symlink b, but they have different meanings because they have different contexts based off of the directory they are stored in.
If symlinks don't have inodes, they could be stored as a special directory entry with the link name and target. This would mean that you couldn't hard link to symlinks, because there is no inode number to hard link to.
Symlink permissions are ignored. You can read a symlink, but you can't write to it. The permissions that matter are the permissions on the file being linked to. The owner and group of a symlink don't affect permissions, but they can be useful for calculating disk quotas per-user, since the symlink still takes up some space.
Symlinks require a few new system calls, depending on if we want information about the symbolic link or if we want the link to be resolved to the file that it points to. The lstat(...); system call does not follow symlinks; it is similar to stat("foo", &st);, which follows symlinks.
The system call readlink("foo", buf, bufsize); will tell us the contents of the symlink. These two syscalls are used by ls to get both the name and permissions of the symbolic link as well as the name of the file that it points to.
The unlink("foo"); system call does not follow symbolic links, because it can be used to remove symlinks.
One special type of file is the character device file, which provides a serial stream of input or output. An example of this is /dev/null.
The 1, 3 is located where the file size would normally be, and means that it is using driver #1 and device #3. Other common character device files include /dev/full, which gives the ENOSPC error on write, and /dev/zero, which when read gives infinite 0s.
To recreate /dev/null if it is deleted, we can use the mknod utility, which creates these special files.
The c means a character device file, and the 1 3 are the driver and device numbers. /dev/null has an inode number, so you can create hard links to it and other character devices.
Another type of special file is a named pipe, which can be created with the mkfifo command.
The file foo is now a named pipe, which functions the same as a pipe in memory except that it persists in the file system. When one process reads from it now, it will hang and wait until some other process has written to the pipe. If a process tries to write to a full named pipe, it will hang until someone has read from the pipe.
If we want to prevent access to a file, we could do $ chmod 0 foo, but this won't work because the attacker could mount the file and change its permissions to something that allows him or her to read.
Assuming the file has only one hard link, and no file descriptors to it are open, we could do $ rm foo, but the data contained in foo is still stored in the sectors of the disk. An attacker could scan the disk and find files that have been unlinked but not overwritten.
In order to erase the data from a file so that no attackers could read it afterward, we could do $ shred foo, which overwrites the file with 0s and random data, then unlinks it. However, shred will leave some traces, such as indirect blocks will be preserved, so an attacker could still potentially get the file size, whether the file was sparse, etc. If there are journaling entries still on disk, they might pertain to the shredded file but are not removed.
If you shred at the file system level, i.e. $ shred /dev/dsk/03, this will be more reliable, since there will be no traces of the file left on disk. However, it will take a very long time if the drive is large, because it has to generate a lot of random data, not to mention writing an entire drive several times.
To get rid of your data very quickly so that no attackers can see it, you should encrypt your file system. Then if you throw away the key, it is the same as shredding the entire drive because none of the data will be readable, but it won't take any time.