CS 111 Lecture 13: File System Robustness
Presented by Paul Eggert on February 25, 2015
Scribe notes written by Ryan Voong and Frank Wang
File System Invariants
While there are many invariants, in this class we focus on the following four conditions:
- Each block is used for exactly one purpose. This means that a block can fulfill the role of a superblock, data block, bitmap block, or inode block, but cannot fulfill multiple roles.
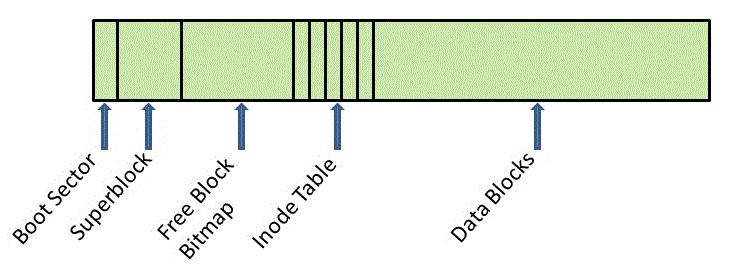
- All referenced blocks are initialized to data appropriate for that block. For instance, if there is a directory that mentions an inode located in the inode table, then that entry must be properly initialized. Something like a negative size field will not be allowed. Similarly, if there is a data block that is a directory, random bits are now allowed because directories follow a specific format.
- All referenced data blocks are marked as used in the bitmap.
- All unreferenced data blocks are marked as free in the bitmap.
Consequences of Violating Invariants
- If we violate invariant 1, the system will get confused because it is using blocks for different reasons. It is likely that the system will overwrite data with other data when we don't want it to. Some potential problems include silently losing data and crashing the kernel.
- If we violate invariant 2 by forgetting to initialize a block (one example of this is a superblock that just contains garbage), the file system may examine random data, follow random pointers that aren't pointing at anything useful, crash the operating system, etc.
- If we violate invariant 3, the result will be a data block that is used but isn't marked as used. This means that we can overwrite data blocks and directory blocks when we do not intend to.
- If we violate invariant 4, we may have permanently unused blocks. This "block leak" causes a loss of efficiency and wastes space, but the file system is technically still functional because we don't lose any data.
Obviously, violating of invariant 4 is the least harmful. When writing file system code under a strict time limit, it is important to prioritize.
Performance
One way to think of how a file system works: a data structure partially on disk or flash, and partially on RAM. We can think of RAM being a cache for what's on disk. Suppose process 1 does a write, and 0.0002 seconds later, process 2 does a read. The read occurs in the kernel and looks at the cache instead of the disk.
Dallying and Batching
Dallying is basically delaying a request in hope that we can batch it future requests. For file systems, it occurs when the user does many writes, but the file system doesn't save data on disk or flash until a few milliseconds later because perhaps another write occurs. The system then tries to write them all at once. This can improve performance by delaying requests that, in the future, may not even be necessary.
Batching is combining several operations into one to reduce setup overhead. For file systems, this occurs when the user writes things one byte at a time, but leaves things sitting in the cache.
Problems to Address
The Volatility of RAM
If we lose power, the write just doesn't happen because RAM is volatile. We can lose data that's written just before a crash as a result of tricks that supposedly improve performance. To some extent, this problem is not a big deal. How would we know the write doesn't get done? As long as the write success is not executed, then this may be acceptable.
The Uncertainty of Write Success
Suppose the write success is visible to the user. Data that is stored on disk may not reflect the sequence of actions that the user did. Some side effects may not be saved due to out of order writes. One way to fix this issue is to complicate the API, using some new system calls:
int fsync(int fd) /* takes all of the data sitting cached and makes sure that on disk, all cache for this file has been written */
However, there is an issue with this: if we lose power during the fsync call, then the result is a bad disk (specifically I/O failure). So let's try something else:
if (fsync(fd) != 0)) error();
if (write(fd, buf, 8192) != 8192) error();
if (fsync(fd != 0)) error();
For this implementation, we need 2 blocks. In the inode table, there is a block containing the inode for our file, and we need to change mtime and size. To fix this, we introduce another system call, int fdatasync(int). In this case, if all we've done is change the last modified time, we can use fdatasync instead of the second fsync. This will be twice as fast because you don't have to move between the inode table and the block.
One misconception is that the system call int close(fd) will synchronize data to the disk. However, closing the file with this system call is completely unrelated to saving data on disk. It is not guaranteed to write cache to disk or flash.
System Calls
What if we want to rename files? Let's consider rename("a", "b"), which renames a file a to b.
- It goes and finds the working directory's inode by finding the working directory's inode number in the process table and reading it into RAM.
- It finds
"a"by loading the directory data into RAM. Then, it changes"a"into"b"in the directory's data. - Eventually, the cache is written to the disk.
If we use this approach, and there are multiple renames, we could encounter problems. In the event we lose power in the middle, it's possible that some files get renamed, and some don't. This is because we may be able to write out one cache entry, but not the others. This means that after reboot, we may lose some of the renames, but also have some later renames after the ones we lost succeed. But what if want the first rename to hit the disk?
Intuitively, one might try to use the sync() function; this won't work because sync() only schedules. Meanwhile, the other functions we learned about, like fdatasync(int fd) and fsync(int fd) require file descriptors. The problem at hand is that if you do renames in a directory, you want to make sure that the change in directory is actually in disk.
rename("x/a", "x/b");
dfd = open("x", O_RDLONLY);
fdatasync(dfd); //synchronizes directory
Unfortunately, a serious problem can occur when we rename from one directory to another. If the power goes out at an inopportune time, we can have a situation where two different directory entries are pointing at the same file, but the file only has a link count of 1. Of course, this can cause dangling pointers upon deletion. So what do we do if we want to rename a file and move it to a different directory? Let's consider rename("x/a", "y/b"), which renames a file a to b and moves it from directory x to y. It needs to take steps to make sure that the file system's invariants are not violated if we lose power. Our approach is as follows.
- Read the inode.
- Read
x's data. - Read
y's data. - Write an inode in which the link count is 2.
- Write
y's new data with a pointer to the file. - Write
x's new data. - Change the link count back to 1.
This implementation does not preserve all invariants, but also will not cause a crash. At some point, the recorded link count is 2 while the actual link count is 1. There may be issues if the system loses power at that point.
fsck
fsck is a tool that checks for errors in a file system. It works by:
- opening the raw device
- reading the bytes off of the disk directory
- looking for incorrect link counts
- putting orphan files in the
/lost+founddirectory
It may be run only on unmounted file systems because all of the bytes are static and unchanging while fsck is reading them. It is common to run fsck after a reboot.
Interaction Between Scheduling and Robustness
Suppose we have a set of pending I/O requests. We want to read block 932 and write block 49171631. We can use many different scheduling algorithms, such as SSTF (shortest seek time first) or FIFO (first in, first out).
If we use FIFO, we will have nice properties for file system robustness, but performance will suffer. Suppose we have a careful ordering of I/O:
write 39216
write 2196 // inode link count = 2
write 3721
write 2196 // inode link count = 1
If we use SSTF, this is what will happen:
write 2196 // the duplicate write has been removed, which is bad!
write 3721
write 39216
We want to find a compromise that has most of the performance of SSTF, but not the correctness disaster. In this compromise,
- It's okay to reorder data blocks (assume that there is no
fsyncorfdatasync) - Remember dependencies in non-data blocks. Give writes with dependencies. For example, say that a certain write must occur before another specific write. The low level system must respect these dependencies.
This compromise is used by BSD file systems.
Robustness Terminology and Theory
There are three main goals to keep in mind when designing a file system:
- Durability. File systems should keep working even if there is a failure (like losing power) in the underlying hardware.
- Atomicity. When the user makes a change to the file and a failure occurs, they should see that the change is either made completely or not made at all. For example, if you lose power in the middle of doing
rename ("a", "b"), you want the file to be either renamed or not renamed. There shouldn't be two links to the same file or no links. - Performance. File systems should be fast. We measure speed in terms of throughput (How many operations are completed per second?) and latency (How long does it take to complete an operation?).
Implementing Atomicity
Assume we're implementing it atop an underlying device where writes aren't atomic.
We have two ways to write:
nawrite("B"); // nonatomic write
awrite("B"); // atomic write
This is an implementation of awrite that does not work:
void awrite(char x) {
// lock out all readers
write(x);
unlock(...);
} // THIS DOES NOT WORK

The golden rule of atomicity: when you write, never overwrite the last copy of your data.
Instead of having only one disk drive, have a device with multiple blocks or drives and keep two copies of the data. Now we must do two writes:
write(I, "B");
write(II, "B");
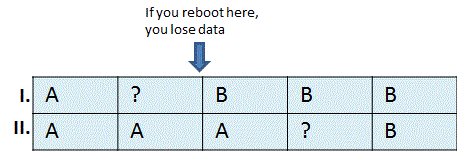
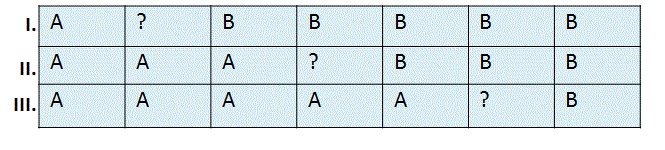
We always want to keep an old version of the data. After a reboot, we always use the newest version of the file. However, this presents a problem: we may lose data!
Instead, we can keep a third copy of the data to ensure that never lose data. But this presents an additional problem: we've tripled our required disk space.
Lampson-Sturgis Assumptions
- Storage writes may fail or may corrupt other blocks. When you do a write, you will write data but the data may be wrong. Also, the write head may be slightly off-track and cause a byte error on the neighboring track, so that when you, say, write to block 100, it might corrupt block 2973.
- A later read can detect the bad block. This is true 99.999% of the time.
- Storage can spontaneously decay. For example, you can drop your flash drive or cosmic rays may flip a bit. We assume that assumption #2 can detect if this happens.
- Errors are rare.
- When errors occur, repairs can be done in time. Assume that you have something like an operations staff that pays close attention for when disk drives break so that they can be replaced.
Two Main Ideas
These ideas will help us build a file system with good performance, atomicity, and durability.
- Commit record. Commit records apply to file systems similarly to how locks apply to data structures. We want to update all ten blocks atomically. We can't update them sequentially because we can lose power at any moment. Instead, copy the original blocks so that we have a new version and an old version. We also keep a commit record. If the commit record is 1, use the new version; if 0, use the old version.

- Journaling. The goal is to make changes to cell data atomically. We have another section of the device called a journal. In the journal, say, for example, "I plan to write locations 2, 12, 13, 22, 33, etc." Log in the journal all of the changes you plan to make, then append a commit record. If the system crashes, we can use the journal to complete the changes.