Overview
- Robustness in File Systems
- Invariants for a FS
- Performance Issues
- Robustness Terminology and Theory
- References
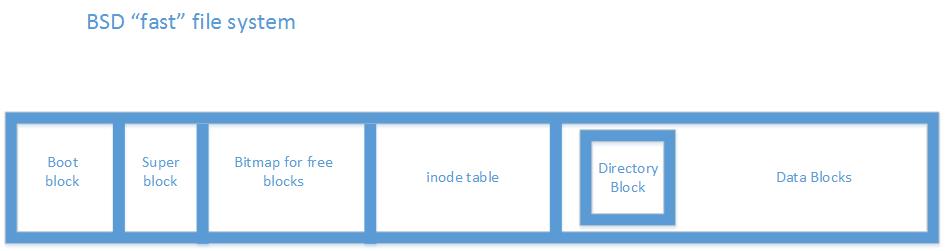
Say you are the product manager of an operating system. How do you go about choosing a file system for your OS? How can you make sure the FS you choose is robust? We can test invariants. Invariants in this case are boolean expresssions that should always be true for the FS.
Let's refer to the above invariants as the rules of our FS.
Rules 1-3 tend to have the highest prioty from developers since breaking these rules will corrupt the entire FS. Rule 4, although important, has less devastating effects.
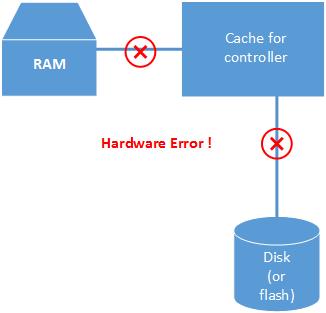
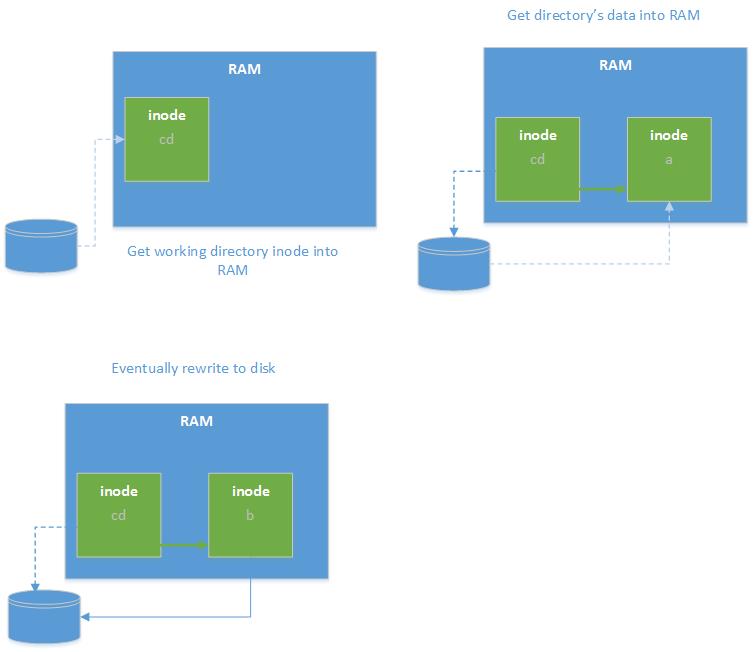
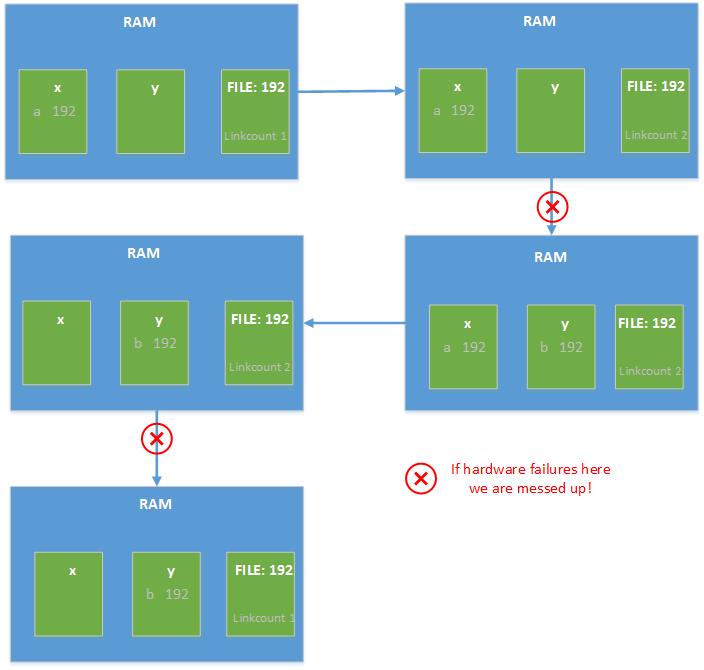
We off course keep the golden rule of atomiticty in mind when implementing this method. Here are the steps involved when you issue a write command.
A journal is separate file that tracks every change of the file system. Any change to the FS first gets logged to the journal. If power is lost while actually writing to to the FS in question, we can go back to the journal and restore the file system. Journals are usually implemented as circular arrays. When the buffer gets close to getting full, the journal entries are commited to the FS and the old journal entries are rewritten with new ones.