Lecture 14: Atomic update and Virtual memory
Contents
Atomic update
Emergent events affecting the hardware of the system can threaten the integrity of the filesystem. One such event is power failure. If the system were to experience power interruption in the middle of the write operation, bits may be corrupted and write may be shorn. In order to protect integrity of the file system, we need some sort of mechanism to make an update atomic, that is, an update should either succeeds and does what it is expected to do, or fails and recovers from failure. In general, there are two main ideas.
Commit record
A commit record acts as a directory block which keeps track of the existing data and the new data that is being written. A write operation is complete only when we commit change in the commit record, i.e- when the file system is notified that the operation succeeds. An atomic update should employ the following key steps -
BEGIN
PRE-COMMIT STAGING
COMMIT
POST-COMMIT OPERATION
END
Journal
In essence, a journal is a transaction log which the journaling file system uses to keep track of changes in the file system and file metadata before committing. Should the main file system report success of committed change, the journaling system would mark the update as complete and the operation can be considered a success. Otherwise, the operation is in progress, and if the system is brought down at this point, it can be restored to its most recent state through some mechanism. A journal can be imagined as a tracking file for commit records. For the purpose of the discussion, the journal entries are considered arranged chronologically from left to right, i.e- the right most entry is the most recent entry and the left most entry is the earliest entry.
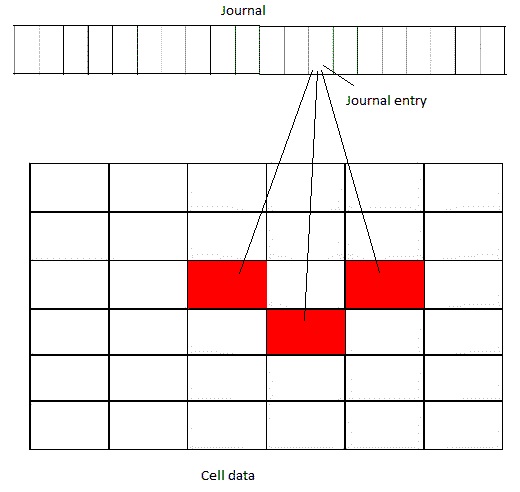
Recovery procedure
Recovery procedure is an outlined steps taken by the system to recover the data in case of failure in order to guarantee the atomicity of the file system update operation and durability of the data on the disk. Two of the most well known techniques are "Write-ahead log" and "Write-behind log".
Write-ahead log
In high-level description, Write-ahead log does the following
LOG CONTENT OF PLANNED WRITE
COMMIT
INSTALL DATA TO ACTUAL CELL DATA
Although the old data may or may not be recoverable, the new data that was being written was already logged by the time the copying of data begins. If the interruption occurs before committing, write is still not carried out and operation simply fails. If the interruption occurs after committing, we still have not fully flushed the planned write to disk, althouh the user has already issued a write, which is an incosistency.To discover the inconsistency, the journaling system scan the journal from left to right, looking for committed but not yest installed changes which indicates interruption. The file system can repair the inconsistency by looking at the metadata and either continuing where it left off or redo the installation of data to data cell. Note that since we are traversing the journal entry from left to right, recovery operation is very likely to be O(n).
+ last action more likely to persist+ no need to save old data
- slow recovery
Write-behind log
In high-level description, Write-behind log does the following
LOG CONTENT OF EXISTING DATA
INSTALL DATA TO ACTUAL CELL DATA
COMMIT
In this case, by the time the actual installation of new data begins, the old data was already logged. The whole operation is not considered a success until after commit is done. If the interruption occurs anywhere before commit, the data on-disk is either (a) complete original data (b) original data partially overwritten with new data. An inconsistency is said to occur in (b) while (a) can be considered a graceful failure. To discover the inconsistency, the journaling system scan the journal from right to left, looking for begun but not yet committed task and restore old value to the data cell.
+ more conservative
+ more recovery possible
+ fast recovery
- old data is usually cached, rendering logging of old data superfluous
Main memory database
Unlike traditional model, this type of database only uses its secondary storage to maintain the journal file. All of its cell data for actual files reside in RAM module. If the system fails, the file system can be restored by reading the journal from right to left, until the most recent successful write to the destination is found, which is very similar to write-behind log.
+ access to data is fast+ no seek time
- demands large RAM capacity
- recorvery is slow since all data need to be reloaded into main memory from secondary storage
Scheduling problems
Consider a uniprocessor system. At a point in time, it runs a process P1, which performs a complex action on the files, involving manipulation of its contents and some computation. In the middle of this operation, the system runs another process P2 which performs a relatively small task of asking the kernel the size of a file. Incidentally, this file is being worked on be P1 and the size of the file demanded by P2 is yet to be determined. How should the system resolve this?
One obvious and simple approach is to let P2 wait until P1 finishes and no longer needs that file.
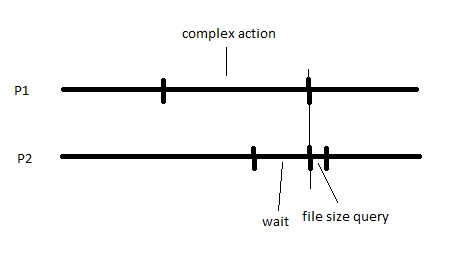
Now, if P2 performs some other complex action after querying file size, we may not want P2 to wait until P1 releases its hold on the file. Another approach is Cascading abort, which involves the following steps -
KERNEL SUPPLIES P2 WITH ITS BEST ESTIMATE OF FILE SIZE
P1 FINISHES AND P2 RECEIVES AN ERROR SIGNAL
IF P2 IS STILL AVLIVE, PERFORMS TRANSACTIONAL ROLLBACK AND ABORTS
Since the process simply aborts when it encounters such problem, cascading abort is automatable.
Another alternative is Compensating action, which involves the following steps -
KERNEL SUPPLIES P2 WITH ITS BEST ESTIMATE OF FILE SIZE
P1 FINISHES AND P2 RECEIVES AN ERROR SIGNAL
IF P2 IS STILL AVLIVE, DOES SOME COMPENSATING ACTION TO ACCOUNT FOR THE ERROR
Since the process needs to compensate for the error (in this case, perform a query again), compensating action adds up complexity but provides additional flexibility
Virtual memory
A common problem in sufficiently low-level programming language is bad memory reference, i.e. - dereferencing a pointer which points to location which does not belong to the process. In C++, when this happens, an exception occurs and the program crashes.
Consider a recent propsed gfile patch whcih uses alloca function to allocate memory
void *alloca(size_t size);
alloca allocates size bytes in the stack frame of the caller and return the pointer to the beginning of the allocated space. Effectively, alloca(x) is equivalent to growing the stack by x bytes. The problem occurs when size is too large, and the system is unable to move the stack pointer downward.
Due to the implementation of the language, many operations/function calls which involve moving the pointer around introduce room for bad memory reference. In order to address this, we can -
(1) avoid the problem by writing perfect code (- impractical)
(2) use help from the kernel or emulator trap (+fast)
(3) use compiler for static checking and runtime environment for runtime checkin (+debuggable)
A simple approach to isolate process's memory
In order to protect the program from making bad reference and possibly scrambling the data it does not intend to or does not have privilege for, we can take a naive approach
by dedicating a pair of register for each running process, such that one points to the lower bound of the process' virtual memory address, and the other points to the upper bound of the process' virtual memory address. For each memory access, we can check if Plower <= Adress < Pupper is true. If it is, then the access is proper and process should be allowed to access the memory, otherwise, an access violation occurs and the system should trap.
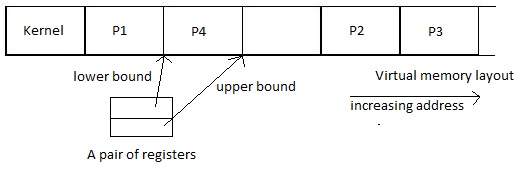
Figure 3: A native approach to implementaion virtual memory isolation.
+ simple
-
assume contiguous memory space for each process
- difficult to share memory between processes
In a real system where many processes run concurrently, access to shared library cannot be implemented with absolute instruction such as jmp 100038. Instead, we use a virtual memory address mapping, where multiple virtual addresses maps to the same physical location or relative addressing where instruction such as jmp x should be replaced with jmp *+offset, which is slightly slower but fixes the problem. Another fix is to add Plower to every reference to absolute address in the code.
Segmented memory
We could also maintain 8 register pairs for each process, with each pair marking the boundary for some area in the memory such as text, data and process's stack. Additionally, we could dedicate one pair to a shared memory region, which solves the problem of sharing memory in the naive approach. With this approach, memory is broken up into segments (called segmented memory in X86 architecture).

- susceptible to, external fragmentation; harder to grow memory
- segment sizes are limited
Paging
In order to eliminate the requirement for memory space to be contiguous for each process and the process's memory to reside on the RAM module, we need some memory management scheme which allows the process to be agnostic to memory retrieval. Paging is one such scheme. It translates linear virtual address into physical adress. It accomplishes this by using page directory and page table. In x86 architecture, entries in page directory and page table are 32-bits. The first 20 bits of page directory entry is used to keep the address of the page table, and the rest is offset. The first 20 bits of page table entry is used to keep the physical page adress, and the rest is offset. Each page represents 4096 bytes of virtual memory. A physical address can be mapped to the virtual address by calculating the offset within the directory and the offset within the table. Special register CR3 is used to keep track of address of page directory entry.
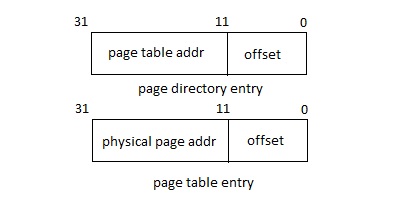
In order to grow memory, we can just scan the table for empty spot. Additionally, we can have mutiple level of page table very much like indirect block in file system, although this is less common, considering each page table takes up 4MB. When a virtual address is mapped to some location not loaded in main memory, a page fault occurs and the kernel must resolve the issue by swapping out a page from main memory (victim) and loading the sought page in its place.
Considering that performance of access operation is determined by the locality of reference, that is, access to data that resides on the lower level cache (register) will take less time than access to that on higher level (L1 cache). If majority of the virtual memory is mapped to location on secodary storage, the system could thrash, i.e. - the system is stuck constantly swapping pages in and out of main memory whilst not doing much of real work, causing the performance to degrade.